Compare commits
1 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
1d199224a7 |
+1
-2
@@ -1,4 +1,3 @@
|
||||
node_modules/
|
||||
packages/*/node_modules/
|
||||
packages/*/lib/
|
||||
packages/glob/__tests__/_temp
|
||||
packages/*/lib/
|
||||
+8
-20
@@ -1,42 +1,28 @@
|
||||
{
|
||||
"plugins": ["jest", "@typescript-eslint"],
|
||||
"extends": ["plugin:github/recommended"],
|
||||
"extends": ["plugin:github/es6"],
|
||||
"parser": "@typescript-eslint/parser",
|
||||
"parserOptions": {
|
||||
"ecmaVersion": 9,
|
||||
"sourceType": "module",
|
||||
"project": "./tsconfig.eslint.json"
|
||||
"project": "./tsconfig.json"
|
||||
},
|
||||
"rules": {
|
||||
"eslint-comments/no-use": "off",
|
||||
"github/no-then": "off",
|
||||
"import/no-namespace": "off",
|
||||
"no-shadow": "off",
|
||||
"no-unused-vars": "off",
|
||||
"no-undef": "off",
|
||||
"@typescript-eslint/no-unused-vars": "error",
|
||||
"@typescript-eslint/explicit-member-accessibility": ["error", {"accessibility": "no-public"}],
|
||||
"@typescript-eslint/no-require-imports": "error",
|
||||
"@typescript-eslint/array-type": "error",
|
||||
"@typescript-eslint/await-thenable": "error",
|
||||
"@typescript-eslint/ban-ts-comment": "error",
|
||||
"@typescript-eslint/ban-ts-ignore": "error",
|
||||
"camelcase": "off",
|
||||
"@typescript-eslint/camelcase": "off",
|
||||
"@typescript-eslint/consistent-type-assertions": "off",
|
||||
"@typescript-eslint/camelcase": "error",
|
||||
"@typescript-eslint/class-name-casing": "error",
|
||||
"@typescript-eslint/explicit-function-return-type": ["error", {"allowExpressions": true}],
|
||||
"@typescript-eslint/func-call-spacing": ["error", "never"],
|
||||
"@typescript-eslint/naming-convention": [
|
||||
"error",
|
||||
{
|
||||
"format": null,
|
||||
"filter": {
|
||||
// you can expand this regex as you find more cases that require quoting that you want to allow
|
||||
"regex": "^[A-Z][A-Za-z]*$",
|
||||
"match": true
|
||||
},
|
||||
"selector": "memberLike"
|
||||
}
|
||||
],
|
||||
"@typescript-eslint/generic-type-naming": ["error", "^[A-Z][A-Za-z]*$"],
|
||||
"@typescript-eslint/no-array-constructor": "error",
|
||||
"@typescript-eslint/no-empty-interface": "error",
|
||||
"@typescript-eslint/no-explicit-any": "error",
|
||||
@@ -46,6 +32,7 @@
|
||||
"@typescript-eslint/no-misused-new": "error",
|
||||
"@typescript-eslint/no-namespace": "error",
|
||||
"@typescript-eslint/no-non-null-assertion": "warn",
|
||||
"@typescript-eslint/no-object-literal-type-assertion": "error",
|
||||
"@typescript-eslint/no-unnecessary-qualifier": "error",
|
||||
"@typescript-eslint/no-unnecessary-type-assertion": "error",
|
||||
"@typescript-eslint/no-useless-constructor": "error",
|
||||
@@ -53,6 +40,7 @@
|
||||
"@typescript-eslint/prefer-for-of": "warn",
|
||||
"@typescript-eslint/prefer-function-type": "warn",
|
||||
"@typescript-eslint/prefer-includes": "error",
|
||||
"@typescript-eslint/prefer-interface": "error",
|
||||
"@typescript-eslint/prefer-string-starts-ends-with": "error",
|
||||
"@typescript-eslint/promise-function-async": "error",
|
||||
"@typescript-eslint/require-array-sort-compare": "error",
|
||||
|
||||
@@ -7,14 +7,6 @@ assignees: ''
|
||||
|
||||
---
|
||||
|
||||
Thank you 🙇♀ for wanting to create an issue in this repository. Before you do, please ensure you are filing the issue in the right place. Issues should only be opened on if the issue **relates to code in this repository**.
|
||||
|
||||
* If you have found a security issue [please submit it here](https://hackerone.com/github)
|
||||
* If you have questions about writing workflows or action files, then please [visit the GitHub Community Forum's Actions Board](https://github.community/t5/GitHub-Actions/bd-p/actions)
|
||||
* If you are having an issue or question about GitHub Actions then please [contact customer support](https://help.github.com/en/actions/automating-your-workflow-with-github-actions/about-github-actions#contacting-support)
|
||||
|
||||
If your issue is relevant to this repository, please include the information below:
|
||||
|
||||
**Describe the bug**
|
||||
A clear and concise description of what the bug is.
|
||||
|
||||
|
||||
@@ -1,95 +0,0 @@
|
||||
name: artifact-unit-tests
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
pull_request:
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
|
||||
jobs:
|
||||
build:
|
||||
name: Build
|
||||
|
||||
strategy:
|
||||
matrix:
|
||||
runs-on: [ubuntu-latest, windows-latest, macos-latest]
|
||||
fail-fast: false
|
||||
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
|
||||
steps:
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: Set Node.js 16.x
|
||||
uses: actions/setup-node@v3
|
||||
with:
|
||||
node-version: 16.x
|
||||
|
||||
# In order to upload & download artifacts from a shell script, certain env variables need to be set that are only available in the
|
||||
# node context. This runs a local action that gets and sets the necessary env variables that are needed
|
||||
- name: Set env variables
|
||||
uses: ./packages/artifact/__tests__/ci-test-action/
|
||||
|
||||
# Need root node_modules because certain npm packages like jest are configured for the entire repository and it won't be possible
|
||||
# without these to just compile the artifacts package
|
||||
- name: Install root npm packages
|
||||
run: npm ci
|
||||
|
||||
- name: Compile artifact package
|
||||
run: |
|
||||
npm ci
|
||||
npm run tsc
|
||||
working-directory: packages/artifact
|
||||
|
||||
- name: Set artifact file contents
|
||||
shell: bash
|
||||
run: |
|
||||
echo "non-gzip-artifact-content=hello" >> $GITHUB_ENV
|
||||
echo "gzip-artifact-content=Some large amount of text that has a compression ratio that is greater than 100%. If greater than 100%, gzip is used to upload the file" >> $GITHUB_ENV
|
||||
echo "empty-artifact-content=_EMPTY_" >> $GITHUB_ENV
|
||||
|
||||
- name: Create files that will be uploaded
|
||||
run: |
|
||||
mkdir artifact-path
|
||||
echo '${{ env.non-gzip-artifact-content }}' > artifact-path/world.txt
|
||||
echo '${{ env.gzip-artifact-content }}' > artifact-path/gzip.txt
|
||||
touch artifact-path/empty.txt
|
||||
|
||||
# We're using node -e to call the functions directly available in the @actions/artifact package
|
||||
- name: Upload artifacts using uploadArtifact()
|
||||
run: |
|
||||
node -e "Promise.resolve(require('./packages/artifact/lib/artifact-client').create().uploadArtifact('my-artifact-1',['artifact-path/world.txt'], process.argv[1]))" "${{ github.workspace }}"
|
||||
node -e "Promise.resolve(require('./packages/artifact/lib/artifact-client').create().uploadArtifact('my-artifact-2',['artifact-path/gzip.txt'], process.argv[1]))" "${{ github.workspace }}"
|
||||
node -e "Promise.resolve(require('./packages/artifact/lib/artifact-client').create().uploadArtifact('my-artifact-3',['artifact-path/empty.txt'], process.argv[1]))" "${{ github.workspace }}"
|
||||
|
||||
- name: Download artifacts using downloadArtifact()
|
||||
run: |
|
||||
mkdir artifact-1-directory
|
||||
node -e "Promise.resolve(require('./packages/artifact/lib/artifact-client').create().downloadArtifact('my-artifact-1','artifact-1-directory'))"
|
||||
mkdir artifact-2-directory
|
||||
node -e "Promise.resolve(require('./packages/artifact/lib/artifact-client').create().downloadArtifact('my-artifact-2','artifact-2-directory'))"
|
||||
mkdir artifact-3-directory
|
||||
node -e "Promise.resolve(require('./packages/artifact/lib/artifact-client').create().downloadArtifact('my-artifact-3','artifact-3-directory'))"
|
||||
|
||||
- name: Verify downloadArtifact()
|
||||
shell: bash
|
||||
run: |
|
||||
packages/artifact/__tests__/test-artifact-file.sh "artifact-1-directory/artifact-path/world.txt" "${{ env.non-gzip-artifact-content }}"
|
||||
packages/artifact/__tests__/test-artifact-file.sh "artifact-2-directory/artifact-path/gzip.txt" "${{ env.gzip-artifact-content }}"
|
||||
packages/artifact/__tests__/test-artifact-file.sh "artifact-3-directory/artifact-path/empty.txt" "${{ env.empty-artifact-content }}"
|
||||
|
||||
- name: Download artifacts using downloadAllArtifacts()
|
||||
run: |
|
||||
mkdir multi-artifact-directory
|
||||
node -e "Promise.resolve(require('./packages/artifact/lib/artifact-client').create().downloadAllArtifacts('multi-artifact-directory'))"
|
||||
|
||||
- name: Verify downloadAllArtifacts()
|
||||
shell: bash
|
||||
run: |
|
||||
packages/artifact/__tests__/test-artifact-file.sh "multi-artifact-directory/my-artifact-1/artifact-path/world.txt" "${{ env.non-gzip-artifact-content }}"
|
||||
packages/artifact/__tests__/test-artifact-file.sh "multi-artifact-directory/my-artifact-2/artifact-path/gzip.txt" "${{ env.gzip-artifact-content }}"
|
||||
packages/artifact/__tests__/test-artifact-file.sh "multi-artifact-directory/my-artifact-3/artifact-path/empty.txt" "${{ env.empty-artifact-content }}"
|
||||
@@ -1,38 +0,0 @@
|
||||
name: toolkit-audit
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
pull_request:
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
|
||||
jobs:
|
||||
|
||||
build:
|
||||
name: Audit
|
||||
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: Set Node.js 16.x
|
||||
uses: actions/setup-node@v3
|
||||
with:
|
||||
node-version: 16.x
|
||||
|
||||
- name: npm install
|
||||
run: npm install
|
||||
|
||||
- name: Bootstrap
|
||||
run: npm run bootstrap
|
||||
|
||||
- name: audit tools (without allow-list)
|
||||
run: npm audit --audit-level=moderate
|
||||
|
||||
- name: audit packages
|
||||
run: npm run audit-all
|
||||
@@ -1,91 +0,0 @@
|
||||
name: cache-unit-tests
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
pull_request:
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
|
||||
jobs:
|
||||
build:
|
||||
name: Build
|
||||
|
||||
strategy:
|
||||
matrix:
|
||||
runs-on: [ubuntu-latest, windows-latest, macOS-latest]
|
||||
fail-fast: false
|
||||
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
|
||||
steps:
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: Set Node.js 16.x
|
||||
uses: actions/setup-node@v3
|
||||
with:
|
||||
node-version: 16.x
|
||||
|
||||
# In order to save & restore cache from a shell script, certain env variables need to be set that are only available in the
|
||||
# node context. This runs a local action that gets and sets the necessary env variables that are needed
|
||||
- name: Set env variables
|
||||
uses: ./packages/cache/__tests__/__fixtures__/
|
||||
|
||||
# Need root node_modules because certain npm packages like jest are configured for the entire repository and it won't be possible
|
||||
# without these to just compile the cache package
|
||||
- name: Install root npm packages
|
||||
run: npm ci
|
||||
|
||||
- name: Compile cache package
|
||||
run: |
|
||||
npm ci
|
||||
npm run tsc
|
||||
working-directory: packages/cache
|
||||
|
||||
- name: Generate files in working directory
|
||||
shell: bash
|
||||
run: packages/cache/__tests__/create-cache-files.sh ${{ runner.os }} test-cache
|
||||
|
||||
- name: Generate files outside working directory
|
||||
shell: bash
|
||||
run: packages/cache/__tests__/create-cache-files.sh ${{ runner.os }} ~/test-cache
|
||||
|
||||
# We're using node -e to call the functions directly available in the @actions/cache package
|
||||
- name: Save cache using saveCache()
|
||||
run: |
|
||||
node -e "Promise.resolve(require('./packages/cache/lib/cache').saveCache(['test-cache','~/test-cache'],'test-${{ runner.os }}-${{ github.run_id }}'))"
|
||||
|
||||
- name: Delete cache folders before restoring
|
||||
shell: bash
|
||||
run: |
|
||||
rm -rf test-cache
|
||||
rm -rf ~/test-cache
|
||||
|
||||
- name: Restore cache using restoreCache() with http-client
|
||||
run: |
|
||||
node -e "Promise.resolve(require('./packages/cache/lib/cache').restoreCache(['test-cache','~/test-cache'],'test-${{ runner.os }}-${{ github.run_id }}',[],{useAzureSdk: false}))"
|
||||
|
||||
- name: Verify cache restored with http-client
|
||||
shell: bash
|
||||
run: |
|
||||
packages/cache/__tests__/verify-cache-files.sh ${{ runner.os }} test-cache
|
||||
packages/cache/__tests__/verify-cache-files.sh ${{ runner.os }} ~/test-cache
|
||||
|
||||
- name: Delete cache folders before restoring
|
||||
shell: bash
|
||||
run: |
|
||||
rm -rf test-cache
|
||||
rm -rf ~/test-cache
|
||||
|
||||
- name: Restore cache using restoreCache() with Azure SDK
|
||||
run: |
|
||||
node -e "Promise.resolve(require('./packages/cache/lib/cache').restoreCache(['test-cache','~/test-cache'],'test-${{ runner.os }}-${{ github.run_id }}'))"
|
||||
|
||||
- name: Verify cache restored with Azure SDK
|
||||
shell: bash
|
||||
run: |
|
||||
packages/cache/__tests__/verify-cache-files.sh ${{ runner.os }} test-cache
|
||||
packages/cache/__tests__/verify-cache-files.sh ${{ runner.os }} ~/test-cache
|
||||
@@ -1,90 +0,0 @@
|
||||
name: cache-windows-bsd-unit-tests
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
pull_request:
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
|
||||
jobs:
|
||||
build:
|
||||
name: Build
|
||||
|
||||
runs-on: windows-latest
|
||||
|
||||
steps:
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- shell: bash
|
||||
run: |
|
||||
rm "C:\Program Files\Git\usr\bin\tar.exe"
|
||||
|
||||
- name: Set Node.js 12.x
|
||||
uses: actions/setup-node@v1
|
||||
with:
|
||||
node-version: 12.x
|
||||
|
||||
# In order to save & restore cache from a shell script, certain env variables need to be set that are only available in the
|
||||
# node context. This runs a local action that gets and sets the necessary env variables that are needed
|
||||
- name: Set env variables
|
||||
uses: ./packages/cache/__tests__/__fixtures__/
|
||||
|
||||
# Need root node_modules because certain npm packages like jest are configured for the entire repository and it won't be possible
|
||||
# without these to just compile the cache package
|
||||
- name: Install root npm packages
|
||||
run: npm ci
|
||||
|
||||
- name: Compile cache package
|
||||
run: |
|
||||
npm ci
|
||||
npm run tsc
|
||||
working-directory: packages/cache
|
||||
|
||||
- name: Generate files in working directory
|
||||
shell: bash
|
||||
run: packages/cache/__tests__/create-cache-files.sh ${{ runner.os }} test-cache
|
||||
|
||||
- name: Generate files outside working directory
|
||||
shell: bash
|
||||
run: packages/cache/__tests__/create-cache-files.sh ${{ runner.os }} ~/test-cache
|
||||
|
||||
# We're using node -e to call the functions directly available in the @actions/cache package
|
||||
- name: Save cache using saveCache()
|
||||
run: |
|
||||
node -e "Promise.resolve(require('./packages/cache/lib/cache').saveCache(['test-cache','~/test-cache'],'test-${{ runner.os }}-${{ github.run_id }}'))"
|
||||
|
||||
- name: Delete cache folders before restoring
|
||||
shell: bash
|
||||
run: |
|
||||
rm -rf test-cache
|
||||
rm -rf ~/test-cache
|
||||
|
||||
- name: Restore cache using restoreCache() with http-client
|
||||
run: |
|
||||
node -e "Promise.resolve(require('./packages/cache/lib/cache').restoreCache(['test-cache','~/test-cache'],'test-${{ runner.os }}-${{ github.run_id }}',[],{useAzureSdk: false}))"
|
||||
|
||||
- name: Verify cache restored with http-client
|
||||
shell: bash
|
||||
run: |
|
||||
packages/cache/__tests__/verify-cache-files.sh ${{ runner.os }} test-cache
|
||||
packages/cache/__tests__/verify-cache-files.sh ${{ runner.os }} ~/test-cache
|
||||
|
||||
- name: Delete cache folders before restoring
|
||||
shell: bash
|
||||
run: |
|
||||
rm -rf test-cache
|
||||
rm -rf ~/test-cache
|
||||
|
||||
- name: Restore cache using restoreCache() with Azure SDK
|
||||
run: |
|
||||
node -e "Promise.resolve(require('./packages/cache/lib/cache').restoreCache(['test-cache','~/test-cache'],'test-${{ runner.os }}-${{ github.run_id }}'))"
|
||||
|
||||
- name: Verify cache restored with Azure SDK
|
||||
shell: bash
|
||||
run: |
|
||||
packages/cache/__tests__/verify-cache-files.sh ${{ runner.os }} test-cache
|
||||
packages/cache/__tests__/verify-cache-files.sh ${{ runner.os }} ~/test-cache
|
||||
@@ -1,37 +0,0 @@
|
||||
name: "Code Scanning - Action"
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
pull_request:
|
||||
schedule:
|
||||
- cron: '0 0 * * 0'
|
||||
|
||||
jobs:
|
||||
CodeQL-Build:
|
||||
|
||||
strategy:
|
||||
fail-fast: false
|
||||
|
||||
|
||||
# CodeQL runs on ubuntu-latest, windows-latest, and macos-latest
|
||||
runs-on: ubuntu-latest
|
||||
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v3
|
||||
|
||||
# Initializes the CodeQL tools for scanning.
|
||||
- name: Initialize CodeQL
|
||||
uses: github/codeql-action/init@v1
|
||||
with:
|
||||
languages: javascript
|
||||
|
||||
# Autobuild attempts to build any compiled languages (C/C++, C#, or Java).
|
||||
# If this step fails, then you should remove it and run the build manually (see below)
|
||||
- name: Autobuild
|
||||
uses: github/codeql-action/autobuild@v1
|
||||
|
||||
- name: Perform CodeQL Analysis
|
||||
uses: github/codeql-action/analyze@v1
|
||||
@@ -1,80 +0,0 @@
|
||||
name: Publish NPM
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
package:
|
||||
required: true
|
||||
description: 'core, artifact, cache, exec, github, glob, http-client, io, tool-cache'
|
||||
|
||||
jobs:
|
||||
test:
|
||||
runs-on: macos-latest
|
||||
|
||||
steps:
|
||||
- name: setup repo
|
||||
uses: actions/checkout@v3
|
||||
|
||||
- name: verify package exists
|
||||
run: ls packages/${{ github.event.inputs.package }}
|
||||
|
||||
- name: Set Node.js 16.x
|
||||
uses: actions/setup-node@v3
|
||||
with:
|
||||
node-version: 16.x
|
||||
|
||||
- name: npm install
|
||||
run: npm install
|
||||
|
||||
- name: bootstrap
|
||||
run: npm run bootstrap
|
||||
|
||||
- name: build
|
||||
run: npm run build
|
||||
|
||||
- name: test
|
||||
run: npm run test
|
||||
|
||||
- name: pack
|
||||
run: npm pack
|
||||
working-directory: packages/${{ github.event.inputs.package }}
|
||||
|
||||
- name: upload artifact
|
||||
uses: actions/upload-artifact@v3
|
||||
with:
|
||||
name: ${{ github.event.inputs.package }}
|
||||
path: packages/${{ github.event.inputs.package }}/*.tgz
|
||||
|
||||
publish:
|
||||
runs-on: macos-latest
|
||||
needs: test
|
||||
environment: npm-publish
|
||||
steps:
|
||||
|
||||
- name: download artifact
|
||||
uses: actions/download-artifact@v3
|
||||
with:
|
||||
name: ${{ github.event.inputs.package }}
|
||||
|
||||
- name: setup authentication
|
||||
run: echo "//registry.npmjs.org/:_authToken=${NPM_TOKEN}" >> .npmrc
|
||||
env:
|
||||
NPM_TOKEN: ${{ secrets.TOKEN }}
|
||||
|
||||
- name: publish
|
||||
run: npm publish *.tgz
|
||||
|
||||
- name: notify slack on failure
|
||||
if: failure()
|
||||
run: |
|
||||
curl -X POST -H 'Content-type: application/json' --data '{"text":":pb__failed: Failed to publish a new version of ${{ github.event.inputs.package }}"}' $SLACK_WEBHOOK
|
||||
env:
|
||||
SLACK_WEBHOOK: ${{ secrets.SLACK }}
|
||||
|
||||
- name: notify slack on success
|
||||
if: success()
|
||||
run: |
|
||||
curl -X POST -H 'Content-type: application/json' --data '{"text":":dance: Successfully published a new version of ${{ github.event.inputs.package }}"}' $SLACK_WEBHOOK
|
||||
env:
|
||||
SLACK_WEBHOOK: ${{ secrets.SLACK }}
|
||||
|
||||
@@ -1,13 +1,11 @@
|
||||
name: toolkit-unit-tests
|
||||
on:
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- main
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
pull_request:
|
||||
paths-ignore:
|
||||
- '**.md'
|
||||
- '**.md'
|
||||
|
||||
jobs:
|
||||
|
||||
@@ -16,19 +14,19 @@ jobs:
|
||||
|
||||
strategy:
|
||||
matrix:
|
||||
runs-on: [ubuntu-latest, macos-latest, windows-latest]
|
||||
runs-on: [ubuntu-latest, macOS-latest, windows-latest]
|
||||
fail-fast: false
|
||||
|
||||
runs-on: ${{ matrix.runs-on }}
|
||||
|
||||
steps:
|
||||
- name: Checkout
|
||||
uses: actions/checkout@v3
|
||||
uses: actions/checkout@v1
|
||||
|
||||
- name: Set Node.js 16.x
|
||||
uses: actions/setup-node@v3
|
||||
- name: Set Node.js 12.x
|
||||
uses: actions/setup-node@master
|
||||
with:
|
||||
node-version: 16.x
|
||||
node-version: 12.x
|
||||
|
||||
- name: npm install
|
||||
run: npm install
|
||||
@@ -40,9 +38,7 @@ jobs:
|
||||
run: npm run build
|
||||
|
||||
- name: npm test
|
||||
run: npm test -- --runInBand
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ github.token }}
|
||||
run: npm test
|
||||
|
||||
- name: Lint
|
||||
run: npm run lint
|
||||
|
||||
@@ -1,45 +0,0 @@
|
||||
name: "UpdateOctokit"
|
||||
|
||||
on:
|
||||
workflow_dispatch:
|
||||
|
||||
jobs:
|
||||
UpdateOctokit:
|
||||
runs-on: ubuntu-latest
|
||||
if: ${{ github.repository_owner == 'actions' }}
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v3
|
||||
- name: Update Octokit
|
||||
working-directory: packages/github
|
||||
run: |
|
||||
npx npm-check-updates -u --dep prod
|
||||
npm install
|
||||
- name: Check Status
|
||||
id: status
|
||||
working-directory: packages/github
|
||||
run: |
|
||||
if [[ "$(git status --porcelain)" != "" ]]; then
|
||||
echo "::set-output name=createPR::true"
|
||||
git config --global user.email "github-actions@github.com"
|
||||
git config --global user.name "github-actions[bot]"
|
||||
git checkout -b bots/updateGitHubDependencies-${{github.run_number}}
|
||||
git add .
|
||||
git commit -m "Update Dependencies"
|
||||
git push --set-upstream origin bots/updateGitHubDependencies-${{github.run_number}}
|
||||
fi
|
||||
- name: Create PR
|
||||
if: ${{steps.status.outputs.createPR}}
|
||||
uses: actions/github-script@v6
|
||||
with:
|
||||
github-token: ${{secrets.GITHUB_TOKEN}}
|
||||
script: |
|
||||
github.pulls.create(
|
||||
{
|
||||
base: "main",
|
||||
owner: "${{github.repository_owner}}",
|
||||
repo: "toolkit",
|
||||
title: "Update Octokit dependencies",
|
||||
body: "Update Octokit dependencies",
|
||||
head: "bots/updateGitHubDependencies-${{github.run_number}}"
|
||||
})
|
||||
+1
-4
@@ -1,7 +1,4 @@
|
||||
node_modules/
|
||||
packages/*/node_modules/
|
||||
packages/*/lib/
|
||||
packages/*/__tests__/_temp/
|
||||
.DS_Store
|
||||
*.xar
|
||||
packages/*/audit.json
|
||||
packages/*/__tests__/_temp/
|
||||
@@ -1,4 +0,0 @@
|
||||
* @actions/actions-runtime
|
||||
|
||||
/packages/artifact/ @actions/artifacts-actions
|
||||
/packages/cache/ @actions/actions-cache
|
||||
@@ -1,5 +1,3 @@
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright 2019 GitHub
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
||||
|
||||
@@ -4,8 +4,7 @@
|
||||
</p>
|
||||
|
||||
<p align="center">
|
||||
<a href="https://github.com/actions/toolkit/actions?query=workflow%3Atoolkit-unit-tests"><img alt="Toolkit unit tests status" src="https://github.com/actions/toolkit/workflows/toolkit-unit-tests/badge.svg"></a>
|
||||
<a href="https://github.com/actions/toolkit/actions?query=workflow%3Atoolkit-audit"><img alt="Toolkit audit status" src="https://github.com/actions/toolkit/workflows/toolkit-audit/badge.svg"></a>
|
||||
<a href="https://github.com/actions/toolkit"><img alt="GitHub Actions status" src="https://github.com/actions/toolkit/workflows/toolkit-unit-tests/badge.svg"></a>
|
||||
</p>
|
||||
|
||||
|
||||
@@ -19,86 +18,48 @@ The GitHub Actions ToolKit provides a set of packages to make creating actions e
|
||||
|
||||
## Packages
|
||||
|
||||
:heavy_check_mark: [@actions/core](packages/core)
|
||||
:heavy_check_mark: [@actions/core](packages/core)
|
||||
|
||||
Provides functions for inputs, outputs, results, logging, secrets and variables. Read more [here](packages/core)
|
||||
|
||||
```bash
|
||||
$ npm install @actions/core
|
||||
$ npm install @actions/core --save
|
||||
```
|
||||
<br/>
|
||||
|
||||
:runner: [@actions/exec](packages/exec)
|
||||
:runner: [@actions/exec](packages/exec)
|
||||
|
||||
Provides functions to exec cli tools and process output. Read more [here](packages/exec)
|
||||
|
||||
```bash
|
||||
$ npm install @actions/exec
|
||||
$ npm install @actions/exec --save
|
||||
```
|
||||
<br/>
|
||||
|
||||
:ice_cream: [@actions/glob](packages/glob)
|
||||
:pencil2: [@actions/io](packages/io)
|
||||
|
||||
Provides functions to search for files matching glob patterns. Read more [here](packages/glob)
|
||||
Provides disk i/o functions like cp, mv, rmRF, find etc. Read more [here](packages/io)
|
||||
|
||||
```bash
|
||||
$ npm install @actions/glob
|
||||
$ npm install @actions/io --save
|
||||
```
|
||||
<br/>
|
||||
|
||||
:phone: [@actions/http-client](packages/http-client)
|
||||
|
||||
A lightweight HTTP client optimized for building actions. Read more [here](packages/http-client)
|
||||
|
||||
```bash
|
||||
$ npm install @actions/http-client
|
||||
```
|
||||
<br/>
|
||||
|
||||
:pencil2: [@actions/io](packages/io)
|
||||
|
||||
Provides disk i/o functions like cp, mv, rmRF, which etc. Read more [here](packages/io)
|
||||
|
||||
```bash
|
||||
$ npm install @actions/io
|
||||
```
|
||||
<br/>
|
||||
|
||||
:hammer: [@actions/tool-cache](packages/tool-cache)
|
||||
:hammer: [@actions/tool-cache](packages/tool-cache)
|
||||
|
||||
Provides functions for downloading and caching tools. e.g. setup-* actions. Read more [here](packages/tool-cache)
|
||||
|
||||
See @actions/cache for caching workflow dependencies.
|
||||
|
||||
```bash
|
||||
$ npm install @actions/tool-cache
|
||||
$ npm install @actions/tool-cache --save
|
||||
```
|
||||
<br/>
|
||||
|
||||
:octocat: [@actions/github](packages/github)
|
||||
:octocat: [@actions/github](packages/github)
|
||||
|
||||
Provides an Octokit client hydrated with the context that the current action is being run in. Read more [here](packages/github)
|
||||
|
||||
```bash
|
||||
$ npm install @actions/github
|
||||
```
|
||||
<br/>
|
||||
|
||||
:floppy_disk: [@actions/artifact](packages/artifact)
|
||||
|
||||
Provides functions to interact with actions artifacts. Read more [here](packages/artifact)
|
||||
|
||||
```bash
|
||||
$ npm install @actions/artifact
|
||||
```
|
||||
<br/>
|
||||
|
||||
:dart: [@actions/cache](packages/cache)
|
||||
|
||||
Provides functions to cache dependencies and build outputs to improve workflow execution time. Read more [here](packages/cache)
|
||||
|
||||
```bash
|
||||
$ npm install @actions/cache
|
||||
$ npm install @actions/github --save
|
||||
```
|
||||
<br/>
|
||||
|
||||
@@ -122,12 +83,6 @@ Problem Matchers are a way to scan the output of actions for a specified regex p
|
||||
<br/>
|
||||
<br/>
|
||||
|
||||
:warning: [Proxy Server Support](docs/proxy-support.md)
|
||||
|
||||
Self-hosted runners can be configured to run behind proxy servers.
|
||||
<br/>
|
||||
<br/>
|
||||
|
||||
<h3><a href="https://github.com/actions/hello-world-javascript-action">Hello World JavaScript Action</a></h3>
|
||||
|
||||
Illustrates how to create a simple hello world javascript action.
|
||||
@@ -141,23 +96,23 @@ Illustrates how to create a simple hello world javascript action.
|
||||
<br/>
|
||||
|
||||
<h3><a href="https://github.com/actions/javascript-action">JavaScript Action Walkthrough</a></h3>
|
||||
|
||||
|
||||
Walkthrough and template for creating a JavaScript Action with tests, linting, workflow, publishing, and versioning.
|
||||
|
||||
```javascript
|
||||
async function run() {
|
||||
try {
|
||||
try {
|
||||
const ms = core.getInput('milliseconds');
|
||||
console.log(`Waiting ${ms} milliseconds ...`)
|
||||
...
|
||||
```
|
||||
```javascript
|
||||
PASS ./index.test.js
|
||||
✓ throws invalid number
|
||||
✓ wait 500 ms
|
||||
✓ throws invalid number
|
||||
✓ wait 500 ms
|
||||
✓ test runs
|
||||
|
||||
Test Suites: 1 passed, 1 total
|
||||
Test Suites: 1 passed, 1 total
|
||||
Tests: 3 passed, 3 total
|
||||
```
|
||||
<br/>
|
||||
@@ -177,11 +132,11 @@ async function run() {
|
||||
```
|
||||
```javascript
|
||||
PASS ./index.test.js
|
||||
✓ throws invalid number
|
||||
✓ wait 500 ms
|
||||
✓ throws invalid number
|
||||
✓ wait 500 ms
|
||||
✓ test runs
|
||||
|
||||
Test Suites: 1 passed, 1 total
|
||||
Test Suites: 1 passed, 1 total
|
||||
Tests: 3 passed, 3 total
|
||||
```
|
||||
<br/>
|
||||
@@ -214,13 +169,13 @@ const myInput = core.getInput('myInput');
|
||||
core.debug(`Hello ${myInput} from inside a container`);
|
||||
|
||||
const context = github.context;
|
||||
console.log(`We can even get context data, like the repo: ${context.repo.repo}`)
|
||||
console.log(`We can even get context data, like the repo: ${context.repo.repo}`)
|
||||
```
|
||||
<br/>
|
||||
|
||||
## Contributing
|
||||
|
||||
We welcome contributions. See [how to contribute](.github/CONTRIBUTING.md).
|
||||
We welcome contributions. See [how to contribute](docs/contribute.md).
|
||||
|
||||
## Code of Conduct
|
||||
|
||||
|
||||
+11
-16
@@ -1,23 +1,9 @@
|
||||
# Debugging
|
||||
If the job logs do not provide enough detail on why a job may be failing, some other options exist to assist with troubleshooting.
|
||||
|
||||
## Step Debug Logs
|
||||
This is the primary way for customers to debug job failures caused by failed steps.
|
||||
|
||||
Step debug logs increase the verbosity of a job's logs during and after a job's execution to assist with troubleshooting.
|
||||
|
||||
Additional log events with the prefix `::debug::` will now also appear in the job's logs, these log events are provided by the Action's author and the runner process.
|
||||
|
||||
### How to Access Step Debug Logs
|
||||
This flag can be enabled by [setting the secret](https://help.github.com/en/actions/automating-your-workflow-with-github-actions/creating-and-using-encrypted-secrets#creating-encrypted-secrets) `ACTIONS_STEP_DEBUG` to `true`.
|
||||
|
||||
All actions ran while this secret is enabled will show debug events in the [Downloaded Logs](https://help.github.com/en/actions/automating-your-workflow-with-github-actions/managing-a-workflow-run#downloading-logs) and [Web Logs](https://help.github.com/en/actions/automating-your-workflow-with-github-actions/managing-a-workflow-run#viewing-logs-to-diagnose-failures).
|
||||
If the build logs do not provide enough detail on why a build may be failing, some other options exist to assist with troubleshooting.
|
||||
|
||||
## Runner Diagnostic Logs
|
||||
Runner Diagnostic Logs provide additional log files detailing how the Runner is executing an action.
|
||||
|
||||
You need the runner diagnostic logs only if you think there is an infrastructure problem with GitHub Actions and you want the product team to check the logs.
|
||||
|
||||
Each file contains different logging information that corresponds to that process:
|
||||
* The Runner process coordinates setting up workers to execute jobs.
|
||||
* The Worker process executes the job.
|
||||
@@ -27,5 +13,14 @@ These files contain the prefix `Runner_` or `Worker_` to indicate the log source
|
||||
### How to Access Runner Diagnostic Logs
|
||||
These log files are enabled by [setting the secret](https://help.github.com/en/actions/automating-your-workflow-with-github-actions/creating-and-using-encrypted-secrets#creating-encrypted-secrets) `ACTIONS_RUNNER_DEBUG` to `true`.
|
||||
|
||||
All actions ran while this secret is enabled contain additional diagnostic log files in the `runner-diagnostic-logs` folder of the [log archive](https://help.github.com/en/actions/automating-your-workflow-with-github-actions/managing-a-workflow-run#downloading-logs).
|
||||
All actions ran while this secret is enabled contain additional diagnostic log files in the `runner-diagnostic-logs` folder of the [log archive](https://help.github.com/en/actions/automating-your-workflow-with-github-actions/managing-a-workflow-run#downloading-logs-and-artifacts).
|
||||
|
||||
## Step Debug Logs
|
||||
Step debug logs increase the verbosity of a job's logs during and after a job's execution to assist with troubleshooting.
|
||||
|
||||
Additional log events with the prefix `::debug::` will now also appear in the job's logs.
|
||||
|
||||
### How to Access Step Debug Logs
|
||||
This flag can be enabled by [setting the secret](https://help.github.com/en/actions/automating-your-workflow-with-github-actions/creating-and-using-encrypted-secrets#creating-encrypted-secrets) `ACTIONS_STEP_DEBUG` to `true`.
|
||||
|
||||
All actions ran while this secret is enabled will show debug events in the [Downloaded Logs](https://help.github.com/en/actions/automating-your-workflow-with-github-actions/managing-a-workflow-run#downloading-logs-and-artifacts) and [Web Logs](https://help.github.com/en/actions/automating-your-workflow-with-github-actions/managing-a-workflow-run#viewing-logs-to-diagnose-failures).
|
||||
|
||||
@@ -32,14 +32,14 @@ jobs:
|
||||
os: [ubuntu-16.04, windows-2019]
|
||||
runs-on: ${{matrix.os}}
|
||||
actions:
|
||||
- uses: actions/setup-node@v3
|
||||
- uses: actions/setup-node@master
|
||||
with:
|
||||
version: ${{matrix.node}}
|
||||
- run: |
|
||||
npm install
|
||||
- run: |
|
||||
npm test
|
||||
- uses: actions/custom-action@v1
|
||||
- uses: actions/custom-action@master
|
||||
```
|
||||
|
||||
JavaScript actions work on any environment that host action runtime is supported on which is currently node 12. However, a host action that runs a toolset expects the environment that it's running on to have that toolset in its PATH or using a setup-* action to acquire it on demand.
|
||||
|
||||
@@ -8,25 +8,25 @@ Examples:
|
||||
steps:
|
||||
- uses: actions/javascript-action@v1 # recommended. starter workflows use this
|
||||
- uses: actions/javascript-action@v1.0.0 # if an action offers specific releases
|
||||
- uses: actions/javascript-action@41775a4da8ffae865553a738ab8ac1cd5a3c0044 # sha
|
||||
- uses: actions/javascript-action@41775a4 # binding to a specific sha
|
||||
```
|
||||
|
||||
# Compatibility
|
||||
|
||||
Binding to a major version is the latest of that major version ( e.g. `v1` == "1.*" )
|
||||
|
||||
Major versions should guarantee compatibility. A major version can add net new capabilities but should not break existing input compatibility or break existing workflows.
|
||||
Major versions should guarantee compatibility. A major version can add new capabilities but should not break existing input compatibility or break existing workflows.
|
||||
|
||||
Major version binding allows you to take advantage of bug fixes and critical functionality and security fixes. The `main` branch has the latest code and is unstable to bind to since changes get committed to main and released to the market place by creating a tag. In addition, a new major version carrying breaking changes will get implemented in main after branching off the previous major version.
|
||||
Major version binding allows you to take advantage of bug fixes and critical functionality and security fixes. The `master` branch has the latest code and is unstable to bind to. Changes are committed to master before the changes are ready to be released to the marketplace by creating a tag. In addition, a new major version may break compatibility will get implemented in master after branching off the previous major version.
|
||||
|
||||
> Warning: do not reference `main` since that is the latest code and can be carrying breaking changes of the next major version.
|
||||
> Warning: do not reference `master` since that is the latest code and may contain breaking changes of the next major version.
|
||||
|
||||
```yaml
|
||||
steps:
|
||||
- uses: actions/javascript-action@main # do not do this
|
||||
- uses: actions/javascript-action@master # do not do this
|
||||
```
|
||||
|
||||
Binding to the immutable full sha1 may offer more reliability. However, note that the hosted images toolsets (e.g. ubuntu-latest) move forward and if there is a tool breaking issue, actions may react with a patch to a major version to compensate so binding to a specific SHA may prevent you from getting fixes.
|
||||
Binding to the immutable sha1 may offer more reliability. However, note that the hosted images toolsets (e.g. ubuntu-latest) move forward and if there is a tool breaking issue, actions may react with a patch to a major version to compensate so binding to a specific SHA may prevent you from getting fixes.
|
||||
|
||||
> Recommendation: bind to major versions to get functionality and fixes but reserve binding to a specific release or SHA as a mitigation strategy for unforeseen breaks.
|
||||
|
||||
@@ -34,15 +34,13 @@ Binding to the immutable full sha1 may offer more reliability. However, note th
|
||||
|
||||
1. **Create a GitHub release for each specific version**: Creating a release like [ v1.0.0 ](https://github.com/actions/javascript-action/releases/tag/v1.0.0) allows users to bind back to a specific version if an issue is encountered with the latest major version.
|
||||
|
||||
2. **Publish the specific version to the marketplace**: When you release a specific version, choose the option to "Publish this Action to the GitHub Marketplace".
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/33549821/78670739-36f5ae00-78ac-11ea-9660-57d5687ce520.png" alt="screenshot" height="250"/>
|
||||
2. **Publish the specific version to the marketplace**: When you release a specific version, choose the option to "Publish this release to the GitHub Marketplace".
|
||||
|
||||
3. **Make the new release available to those binding to the major version tag**: Move the major version tag (v1, v2, etc.) to point to the ref of the current release. This will act as the stable release for that major version. You should keep this tag updated to the most recent stable minor/patch release.
|
||||
|
||||
```
|
||||
git tag -fa v1 -m "Update v1 tag"
|
||||
git push origin v1 --force
|
||||
git tag --force --annotate -m "Update v1 tag" v1
|
||||
git push --force origin v1
|
||||
```
|
||||
# Major Versions
|
||||
|
||||
|
||||
@@ -1,216 +0,0 @@
|
||||
# ADR 381: `glob` module
|
||||
|
||||
**Date**: 2019-12-05
|
||||
|
||||
**Status**: Accepted
|
||||
|
||||
## Context
|
||||
|
||||
This ADR proposes adding a `glob` function to the toolkit.
|
||||
|
||||
First party actions should have a consistent glob experience.
|
||||
|
||||
Related to artifact upload/download v2.
|
||||
|
||||
## Decision
|
||||
|
||||
### New module
|
||||
|
||||
Create a new module `@actions/glob` that can be versioned at it's own pace - not tied to `@actions/io`.
|
||||
|
||||
### Signature
|
||||
|
||||
```js
|
||||
/**
|
||||
* Constructs a globber from patterns
|
||||
*
|
||||
* @param patterns Patterns separated by newlines
|
||||
* @param options Glob options
|
||||
*/
|
||||
export function create(
|
||||
patterns: string,
|
||||
options?: GlobOptions
|
||||
): Promise<Globber> {}
|
||||
|
||||
/**
|
||||
* Used to match files and directories
|
||||
*/
|
||||
export interface Globber {
|
||||
/**
|
||||
* Returns the search path preceding the first glob segment, from each pattern.
|
||||
* Duplicates and descendants of other paths are filtered out.
|
||||
*
|
||||
* Example 1: The patterns `/foo/*` and `/bar/*` returns `/foo` and `/bar`.
|
||||
*
|
||||
* Example 2: The patterns `/foo/*` and `/foo/bar/*` returns `/foo`.
|
||||
*/
|
||||
getSearchPaths(): string[]
|
||||
|
||||
/**
|
||||
* Returns files and directories matching the glob patterns.
|
||||
*
|
||||
* Order of the results is not guaranteed.
|
||||
*/
|
||||
glob(): Promise<string[]>
|
||||
|
||||
/**
|
||||
* Returns files and directories matching the glob patterns.
|
||||
*
|
||||
* Order of the results is not guaranteed.
|
||||
*/
|
||||
globGenerator(): AsyncGenerator<string, void>
|
||||
}
|
||||
|
||||
/**
|
||||
* Options to control globbing behavior
|
||||
*/
|
||||
export interface GlobOptions {
|
||||
/**
|
||||
* Indicates whether to follow symbolic links. Generally should set to false
|
||||
* when deleting files.
|
||||
*
|
||||
* @default true
|
||||
*/
|
||||
followSymbolicLinks?: boolean
|
||||
|
||||
/**
|
||||
* Indicates whether directories that match a glob pattern, should implicitly
|
||||
* cause all descendant paths to be matched.
|
||||
*
|
||||
* For example, given the directory `my-dir`, the following glob patterns
|
||||
* would produce the same results: `my-dir/**`, `my-dir/`, `my-dir`
|
||||
*
|
||||
* @default true
|
||||
*/
|
||||
implicitDescendants?: boolean
|
||||
|
||||
/**
|
||||
* Indicates whether broken symbolic should be ignored and omitted from the
|
||||
* result set. Otherwise an error will be thrown.
|
||||
*
|
||||
* @default true
|
||||
*/
|
||||
omitBrokenSymbolicLinks?: boolean
|
||||
}
|
||||
```
|
||||
|
||||
### Toolkit usage
|
||||
|
||||
Example, do not follow symbolic links:
|
||||
|
||||
```js
|
||||
const patterns = core.getInput('path')
|
||||
const globber = glob.create(patterns, {followSymbolicLinks: false})
|
||||
const files = globber.glob()
|
||||
```
|
||||
|
||||
Example, iterator:
|
||||
|
||||
```js
|
||||
const patterns = core.getInput('path')
|
||||
const globber = glob.create(patterns)
|
||||
for await (const file of this.globGenerator()) {
|
||||
console.log(file)
|
||||
}
|
||||
```
|
||||
|
||||
### Action usage
|
||||
|
||||
Actions should follow symbolic links by default.
|
||||
|
||||
Users can opt-out.
|
||||
|
||||
Example:
|
||||
|
||||
```yaml
|
||||
jobs:
|
||||
build:
|
||||
steps:
|
||||
- uses: actions/upload-artifact@v1
|
||||
with:
|
||||
path: |
|
||||
**/*.tar.gz
|
||||
**/*.pkg
|
||||
follow-symbolic-links: false # opt out, should default to true
|
||||
```
|
||||
|
||||
### HashFiles function
|
||||
|
||||
Hash files should not follow symbolic links by default.
|
||||
|
||||
User can opt-in by specifying flag `--follow-symbolic-links`.
|
||||
|
||||
Example:
|
||||
|
||||
```yaml
|
||||
jobs:
|
||||
build:
|
||||
steps:
|
||||
- uses: actions/cache@v1
|
||||
with:
|
||||
hash: ${{ hashFiles('--follow-symbolic-links', '**/package-lock.json') }}
|
||||
```
|
||||
|
||||
### Glob behavior
|
||||
|
||||
Patterns `*`, `?`, `[...]`, `**` (globstar) are supported.
|
||||
|
||||
With the following behaviors:
|
||||
|
||||
- File names that begin with `.` may be included in the results
|
||||
- Case insensitive on Windows
|
||||
- Directory separator `/` and `\` both supported on Windows
|
||||
|
||||
Note:
|
||||
- Refer [here](https://www.gnu.org/software/bash/manual/html_node/Pattern-Matching.html#Pattern-Matching) for more information about Bash glob patterns.
|
||||
- Refer [here](https://www.gnu.org/software/bash/manual/html_node/The-Shopt-Builtin.html) for more information about Bash glob options.
|
||||
|
||||
### Tilde expansion
|
||||
|
||||
Support basic tilde expansion, for current user HOME replacement only.
|
||||
|
||||
For example, on macOS:
|
||||
- `~` may expand to `/Users/johndoe`
|
||||
- `~/foo` may expand to `/Users/johndoe/foo`
|
||||
|
||||
Note:
|
||||
- Refer [here](https://www.gnu.org/software/bash/manual/html_node/Tilde-Expansion.html) for more information about Bash tilde expansion.
|
||||
- All other forms of tilde expansion are not supported.
|
||||
- Use `os.homedir()` to resolve the HOME path
|
||||
|
||||
### Root and normalize paths
|
||||
|
||||
An unrooted pattern will be rooted using the current working directory, prior to searching. Additionally the search path will be normalized prior to searching (relative pathing removed, slashes normalized on Windows, extra slashes removed).
|
||||
|
||||
The two side effects are:
|
||||
1. Rooted and normalized paths are always returned
|
||||
2. The pattern `**` will include the working directory in the results
|
||||
|
||||
These side effects diverge from Bash behavior. Whereas Bash is designed to be a shell, we are designing an API. This decision is intended to improve predictability of the API results.
|
||||
|
||||
Note:
|
||||
- In Bash, the results are not rooted when the pattern is relative.
|
||||
- In Bash, the results are not normalized. For example, the results from `./*` may look like: `./foo ./bar`
|
||||
- In Bash, the results from the pattern `**` does not include the working directory. However the results from `/foo/**` would include the directory `/foo`. Also the results from `foo/**` would include the directory `foo`.
|
||||
|
||||
## Comments
|
||||
|
||||
Patterns that begin with `#` are treated as comments.
|
||||
|
||||
## Exclude patterns
|
||||
|
||||
Leading `!` changes the meaning of an include pattern to exclude.
|
||||
|
||||
Note:
|
||||
- Multiple leading `!` flips the meaning.
|
||||
|
||||
## Escaping
|
||||
|
||||
Wrapping special characters in `[]` can be used to escape literal glob characters in a file name. For example the literal file name `hello[a-z]` can be escaped as `hello[[]a-z]`.
|
||||
|
||||
On Linux/macOS `\` is also treated as an escape character.
|
||||
|
||||
## Consequences
|
||||
|
||||
- Publish new module `@actions/glob`
|
||||
- Publish docs for the module (add link from `./README.md` to new doc `./packages/glob/README.md`)
|
||||
@@ -1,19 +0,0 @@
|
||||
# ADRs
|
||||
|
||||
ADR, short for "Architecture Decision Record" is a way of capturing important architectural decisions, along with their context and consequences.
|
||||
|
||||
This folder includes ADRs for the actions toolkit. ADRs are proposed in the form of a pull request, and they commonly follow this format:
|
||||
|
||||
* **Title**: short present tense imperative phrase, less than 50 characters, like a git commit message.
|
||||
|
||||
* **Status**: proposed, accepted, rejected, deprecated, superseded, etc.
|
||||
|
||||
* **Context**: what is the issue that we're seeing that is motivating this decision or change.
|
||||
|
||||
* **Decision**: what is the change that we're actually proposing or doing.
|
||||
|
||||
* **Consequences**: what becomes easier or more difficult to do because of this change.
|
||||
|
||||
---
|
||||
|
||||
- More information about ADRs can be found [here](https://github.com/joelparkerhenderson/architecture_decision_record).
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 46 KiB |
+37
-117
@@ -1,12 +1,43 @@
|
||||
# :: Commands
|
||||
|
||||
The [core toolkit package](https://github.com/actions/toolkit/tree/main/packages/core) offers a number of convenience functions for
|
||||
The [core toolkit package](https://github.com/actions/toolkit/tree/master/packages/core) offers a number of convenience functions for
|
||||
setting results, logging, registering secrets and exporting variables across actions. Sometimes, however, its useful to be able to do
|
||||
these things in a script or other tool.
|
||||
|
||||
To allow this, we provide a special `::` syntax which, if logged to `stdout` on a new line, will allow the runner to perform special behavior on
|
||||
your commands. The following commands are all supported:
|
||||
|
||||
### Set an environment variable
|
||||
|
||||
To set an environment variable for future out of process steps, use `::set-env`:
|
||||
|
||||
```sh
|
||||
echo "::set-env name=FOO::BAR"
|
||||
```
|
||||
|
||||
Running `$FOO` in a future step will now return `BAR`
|
||||
|
||||
This is wrapped by the core exportVariable method which sets for future steps but also updates the variable for this step
|
||||
|
||||
```javascript
|
||||
export function exportVariable(name: string, val: string): void {}
|
||||
```
|
||||
|
||||
### PATH Manipulation
|
||||
|
||||
To prepend a string to PATH, use `::addPath`:
|
||||
|
||||
```sh
|
||||
echo "::add-path::BAR"
|
||||
```
|
||||
|
||||
Running `$PATH` in a future step will now return `BAR:{Previous Path}`;
|
||||
|
||||
This is wrapped by the core addPath method:
|
||||
```javascript
|
||||
export function addPath(inputPath: string): void {}
|
||||
```
|
||||
|
||||
### Set outputs
|
||||
|
||||
To set an output for the step, use `::set-output`:
|
||||
@@ -50,25 +81,14 @@ function setSecret(secret: string): void {}
|
||||
|
||||
Now, future logs containing BAR will be masked. E.g. running `echo "Hello FOO BAR World"` will now print `Hello FOO **** World`.
|
||||
|
||||
**WARNING** The add-mask and setSecret commands only support single-line
|
||||
secrets or multi-line secrets that have been escaped. `@actions/core`
|
||||
`setSecret` will escape the string you provide by default. When an escaped
|
||||
multi-line string is provided the whole string and each of its lines
|
||||
individually will be masked. For example you can mask `first\nsecond\r\nthird`
|
||||
using:
|
||||
|
||||
```sh
|
||||
echo "::add-mask::first%0Asecond%0D%0Athird"
|
||||
```
|
||||
|
||||
This will mask `first%0Asecond%0D%0Athird`, `first`, `second` and `third`.
|
||||
**WARNING** The add-mask and setSecret commands only support single line secrets. To register a multiline secrets you must register each line individually otherwise it will not be masked.
|
||||
|
||||
**WARNING** Do **not** mask short values if you can avoid it, it could render your output unreadable (and future steps' output as well).
|
||||
For example, if you mask the letter `l`, running `echo "Hello FOO BAR World"` will now print `He*********o FOO BAR Wor****d`
|
||||
|
||||
### Group and Ungroup Log Lines
|
||||
|
||||
Emitting a group with a title will instruct the logs to create a collapsible region up to the next endgroup command.
|
||||
Emitting a group with a title will instruct the logs to create a collapsable region up to the next ungroup command.
|
||||
|
||||
```bash
|
||||
echo "::group::my title"
|
||||
@@ -83,7 +103,6 @@ function endGroup(): void {}
|
||||
```
|
||||
|
||||
### Problem Matchers
|
||||
|
||||
Problems matchers can be used to scan a build's output to automatically surface lines to the user that matches the provided pattern. A file path to a .json Problem Matcher must be provided. See [Problem Matchers](problem-matchers.md) for more information on how to define a Problem Matcher.
|
||||
|
||||
```bash
|
||||
@@ -93,125 +112,26 @@ echo "::remove-matcher owner=eslint-compact::"
|
||||
|
||||
`add-matcher` takes a path to a Problem Matcher file
|
||||
`remove-matcher` removes a Problem Matcher by owner
|
||||
|
||||
### Save State
|
||||
|
||||
Save a state to an environmental variable that can later be used in the main or post action.
|
||||
Save state to be used in the corresponding wrapper (finally) post job entry point.
|
||||
|
||||
```bash
|
||||
echo "::save-state name=FOO::foovalue"
|
||||
```
|
||||
|
||||
Because `save-state` prepends the string `STATE_` to the name, the environment variable `STATE_FOO` will be available to use in the post or main action. See [Sending Values to the pre and post actions](https://help.github.com/en/actions/reference/workflow-commands-for-github-actions#sending-values-to-the-pre-and-post-actions) for more information.
|
||||
|
||||
### Log Level
|
||||
|
||||
There are several commands to emit different levels of log output:
|
||||
Finally, there are several commands to emit different levels of log output:
|
||||
|
||||
| log level | example usage |
|
||||
|---|---|
|
||||
| [debug](action-debugging.md) | `echo "::debug::My debug message"` |
|
||||
| notice | `echo "::notice::My notice message"` |
|
||||
| warning | `echo "::warning::My warning message"` |
|
||||
| error | `echo "::error::My error message"` |
|
||||
|
||||
Additional syntax options are described at [the workflow command documentation](https://docs.github.com/en/actions/reference/workflow-commands-for-github-actions#setting-a-debug-message).
|
||||
|
||||
### Command Echoing
|
||||
|
||||
By default, the echoing of commands to stdout only occurs if [Step Debugging is enabled](./action-debugging.md#How-to-Access-Step-Debug-Logs)
|
||||
|
||||
You can enable or disable this for the current step by using the `echo` command.
|
||||
|
||||
```bash
|
||||
echo "::echo::on"
|
||||
```
|
||||
|
||||
You can also disable echoing.
|
||||
|
||||
```bash
|
||||
echo "::echo::off"
|
||||
```
|
||||
|
||||
This is wrapped by the core method:
|
||||
|
||||
```javascript
|
||||
function setCommandEcho(enabled: boolean): void {}
|
||||
```
|
||||
|
||||
The `add-mask`, `debug`, `warning` and `error` commands do not support echoing.
|
||||
|
||||
### Command Prompt
|
||||
|
||||
### Command Prompt
|
||||
CMD processes the `"` character differently from other shells when echoing. In CMD, the above snippets should have the `"` characters removed in order to correctly process. For example, the set output command would be:
|
||||
|
||||
```cmd
|
||||
echo ::set-output name=FOO::BAR
|
||||
```
|
||||
|
||||
## Environment files
|
||||
|
||||
During the execution of a workflow, the runner generates temporary files that can be used to perform certain actions. The path to these files are exposed via environment variables. You will need to use the `utf-8` encoding when writing to these files to ensure proper processing of the commands. Multiple commands can be written to the same file, separated by newlines.
|
||||
|
||||
### Set an environment variable
|
||||
|
||||
To set an environment variable for future out of process steps, write to the file located at `GITHUB_ENV` or use the equivalent `actions/core` function
|
||||
|
||||
```sh
|
||||
echo "FOO=BAR" >> $GITHUB_ENV
|
||||
```
|
||||
|
||||
Running `$FOO` in a future step will now return `BAR`
|
||||
|
||||
For multiline strings, you may use a heredoc style syntax with your choice of delimeter. In the below example, we use `EOF`.
|
||||
|
||||
```
|
||||
steps:
|
||||
- name: Set the value
|
||||
id: step_one
|
||||
run: |
|
||||
echo 'JSON_RESPONSE<<EOF' >> $GITHUB_ENV
|
||||
curl https://httpbin.org/json >> $GITHUB_ENV
|
||||
echo 'EOF' >> $GITHUB_ENV
|
||||
```
|
||||
|
||||
This would set the value of the `JSON_RESPONSE` env variable to the value of the curl response.
|
||||
|
||||
The expected syntax for the heredoc style is:
|
||||
|
||||
```
|
||||
{VARIABLE_NAME}<<{DELIMETER}
|
||||
{VARIABLE_VALUE}
|
||||
{DELIMETER}
|
||||
```
|
||||
|
||||
This is wrapped by the core `exportVariable` method which sets for future steps but also updates the variable for this step.
|
||||
|
||||
```javascript
|
||||
export function exportVariable(name: string, val: string): void {}
|
||||
```
|
||||
|
||||
### PATH Manipulation
|
||||
|
||||
To prepend a string to PATH write to the file located at `GITHUB_PATH` or use the equivalent `actions/core` function
|
||||
|
||||
```sh
|
||||
echo "/Users/test/.nvm/versions/node/v12.18.3/bin" >> $GITHUB_PATH
|
||||
```
|
||||
|
||||
Running `$PATH` in a future step will now return `/Users/test/.nvm/versions/node/v12.18.3/bin:{Previous Path}`;
|
||||
|
||||
This is wrapped by the core addPath method:
|
||||
|
||||
```javascript
|
||||
export function addPath(inputPath: string): void {}
|
||||
```
|
||||
|
||||
### Powershell
|
||||
|
||||
Powershell does not use UTF8 by default. You will want to make sure you write in the correct encoding. For example, to set the path:
|
||||
|
||||
```
|
||||
steps:
|
||||
- run: echo "mypath" | Out-File -FilePath $env:GITHUB_PATH -Encoding utf8 -Append
|
||||
```
|
||||
|
||||
@@ -18,7 +18,7 @@ e.g. To use https://github.com/actions/setup-node, users will author:
|
||||
|
||||
```yaml
|
||||
steps:
|
||||
using: actions/setup-node@v3
|
||||
using: actions/setup-node@master
|
||||
```
|
||||
|
||||
# Define Metadata
|
||||
|
||||
@@ -1,23 +1,4 @@
|
||||
# Contributions
|
||||
|
||||
We welcome contributions in the form of issues and pull requests. We view the contributions and process as the same for internal and external contributors.
|
||||
|
||||
## Issues
|
||||
|
||||
Log issues for both bugs and enhancement requests. Logging issues are important for the open community.
|
||||
|
||||
Issues in this repository should be for the toolkit packages. General feedback for GitHub Actions should be filed in the [community forums.](https://github.community/t5/GitHub-Actions/bd-p/actions) Runner specific issues can be filed [in the runner repository](https://github.com/actions/runner).
|
||||
|
||||
## Enhancements and Feature Requests
|
||||
|
||||
We ask that before significant effort is put into code changes, that we have agreement on taking the change before time is invested in code changes.
|
||||
|
||||
1. Create a feature request.
|
||||
2. When we agree to take the enhancement, create an ADR to agree on the details of the change.
|
||||
|
||||
An ADR is an Architectural Decision Record. This allows consensus on the direction forward and also serves as a record of the change and motivation. [Read more here](../docs/adrs/README.md).
|
||||
|
||||
## Development Life Cycle
|
||||
## Development
|
||||
|
||||
This repository uses [Lerna](https://github.com/lerna/lerna#readme) to manage multiple packages. Read the documentation there to begin contributing.
|
||||
|
||||
@@ -56,4 +37,4 @@ This will ask you some questions about the new package. Start with `0.0.0` as th
|
||||
}
|
||||
```
|
||||
|
||||
3. Start developing 😄.
|
||||
3. Start developing 😄 and open a pull request.
|
||||
@@ -8,7 +8,7 @@ Note that a complete version of this action can be found at https://github.com/d
|
||||
|
||||
## Prerequisites
|
||||
|
||||
This walkthrough assumes that you have gone through the basic [javascript action walkthrough](https://github.com/actions/javascript-action) and have a basic action set up. If not, we recommend you go through that first.
|
||||
This walkthrough assumes that you have gone through the basic [javascript action walkthrough](./javascript-action.md) and have a basic action set up. If not, we recommend you go through that first.
|
||||
|
||||
## Installing dependencies
|
||||
|
||||
@@ -159,7 +159,7 @@ run();
|
||||
|
||||
## Writing unit tests for your action
|
||||
|
||||
Next, we're going to write a basic unit test for our action using jest. If you followed the [javascript walkthrough](https://github.com/actions/javascript-action), you should have a file `__tests__/main.test.ts` that runs tests when `npm test` is called. We're going to start by populating that with one test:
|
||||
Next, we're going to write a basic unit test for our action using jest. If you followed the [javascript walkthrough](./javascript-action.md), you should have a file `__tests__/main.test.ts` that runs tests when `npm test` is called. We're going to start by populating that with one test:
|
||||
|
||||
```ts
|
||||
const nock = require('nock');
|
||||
|
||||
@@ -1,27 +1,13 @@
|
||||
# Problem Matchers
|
||||
|
||||
Problem Matchers are a way to scan the output of actions for a specified regex pattern and surface that information prominently in the UI. Both [GitHub Annotations](https://developer.github.com/v3/checks/runs/#annotations-object-1) and log file decorations are created when a match is detected.
|
||||
|
||||
## Limitations
|
||||
|
||||
Currently, GitHub Actions limit the annotation count in a workflow run.
|
||||
|
||||
- 10 warning annotations, 10 error annotations, and 10 notice annotations per step
|
||||
- 50 annotations per job (sum of annotations from all the steps)
|
||||
- 50 annotations per run (separate from the job annotations, these annotations aren’t created by users)
|
||||
|
||||
If your workflow may exceed these annotation counts, consider filtering of the log messages which the Problem Matcher is exposed to (e.g. by PR touched files, lines, or other).
|
||||
|
||||
## Single Line Matchers
|
||||
|
||||
Let's consider the ESLint compact output:
|
||||
|
||||
```
|
||||
badFile.js: line 50, col 11, Error - 'myVar' is defined but never used. (no-unused-vars)
|
||||
```
|
||||
|
||||
We can define a problem matcher in json that detects input in that format:
|
||||
|
||||
```json
|
||||
{
|
||||
"problemMatcher": [
|
||||
@@ -47,34 +33,31 @@ The following fields are available for problem matchers:
|
||||
|
||||
```
|
||||
{
|
||||
owner: an ID field that can be used to remove or replace the problem matcher. **required**
|
||||
severity: indicates the default severity, either 'warning' or 'error' case-insensitive. Defaults to 'error'
|
||||
owner: An ID field that can be used to remove or replace the problem matcher. **required**
|
||||
pattern: [
|
||||
{
|
||||
regexp: the regex pattern that provides the groups to match against **required**
|
||||
regexp: The regex pattern that provides the groups to match against **required**
|
||||
file: a group number containing the file name
|
||||
fromPath: a group number containing a filepath used to root the file (e.g. a project file)
|
||||
line: a group number containing the line number
|
||||
column: a group number containing the column information
|
||||
severity: a group number containing either 'warning' or 'error' case-insensitive. Defaults to `error`
|
||||
code: a group number containing the error code
|
||||
message: a group number containing the error message. **required** at least one pattern must set the message
|
||||
loop: whether to loop until a match is not found, only valid on the last pattern of a multipattern matcher
|
||||
loop: loops until a match is not found, only valid on the last pattern of a multipattern matcher
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## Multiline Matching
|
||||
Consider the following output:
|
||||
|
||||
```
|
||||
test.js
|
||||
1:0 error Missing "use strict" statement strict
|
||||
5:10 error 'addOne' is defined but never used no-unused-vars
|
||||
✖ 2 problems (2 errors, 0 warnings)
|
||||
```
|
||||
|
||||
The file name is printed once, yet multiple error lines are printed. The `loop` keyword provides a way to discover multiple errors in outputs.
|
||||
|
||||
The eslint-stylish problem matcher defined below catches that output, and creates two annotations from it.
|
||||
@@ -110,40 +93,15 @@ The eslint-stylish problem matcher defined below catches that output, and create
|
||||
The first pattern matches the `test.js` line and records the file information. This line is not decorated in the UI.
|
||||
The second pattern loops through the remaining lines with `loop: true` until it fails to find a match, and surfaces these lines prominently in the UI.
|
||||
|
||||
Note that the pattern matches must be on consecutive lines. The following would not result in any match findings.
|
||||
|
||||
```
|
||||
test.js
|
||||
extraneous log line of no interest
|
||||
1:0 error Missing "use strict" statement strict
|
||||
5:10 error 'addOne' is defined but never used no-unused-vars
|
||||
✖ 2 problems (2 errors, 0 warnings)
|
||||
```
|
||||
|
||||
## Adding and Removing Problem Matchers
|
||||
|
||||
Problem Matchers are enabled and removed via the toolkit [commands](commands.md#problem-matchers).
|
||||
|
||||
## Duplicate Problem Matchers
|
||||
|
||||
Registering two problem-matchers with the same owner will result in only the problem matcher registered last running.
|
||||
|
||||
## Examples
|
||||
|
||||
Some of the starter actions are already using problem matchers, for example:
|
||||
- [setup-node](https://github.com/actions/setup-node/tree/main/.github)
|
||||
- [setup-python](https://github.com/actions/setup-python/tree/main/.github)
|
||||
- [setup-go](https://github.com/actions/setup-go/tree/main/.github)
|
||||
- [setup-dotnet](https://github.com/actions/setup-dotnet/tree/main/.github)
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
### Regular expression not matching
|
||||
|
||||
Use ECMAScript regular expression syntax when testing patterns.
|
||||
|
||||
### File property getting dropped
|
||||
|
||||
[Enable debug logging](https://docs.github.com/en/actions/managing-workflow-runs/enabling-debug-logging) to determine why the file is getting dropped.
|
||||
|
||||
This usually happens when the file does not exist or is not under the workflow repo.
|
||||
- [setup-node](https://github.com/actions/setup-node/tree/master/.github)
|
||||
- [setup-python](https://github.com/actions/setup-python/tree/master/.github)
|
||||
- [setup-go](https://github.com/actions/setup-go/tree/master/.github)
|
||||
- [setup-dotnet](https://github.com/actions/setup-dotnet/tree/master/.github)
|
||||
|
||||
@@ -1,10 +0,0 @@
|
||||
# Proxy Server Support
|
||||
|
||||
Self-hosted runners [can be configured](https://help.github.com/en/actions/hosting-your-own-runners/using-a-proxy-server-with-self-hosted-runners) to run behind a proxy server in enterprises.
|
||||
|
||||
For actions to **just work** behind a proxy server:
|
||||
|
||||
1. Use [tool-cache](/packages/tool-cache) version >= 1.3.1
|
||||
2. Optionally use [actions/http-client](/packages/http-client)
|
||||
|
||||
If you are using other http clients, refer to the [environment variables set by the runner](https://help.github.com/en/actions/hosting-your-own-runners/using-a-proxy-server-with-self-hosted-runners).
|
||||
@@ -4,6 +4,7 @@ module.exports = {
|
||||
roots: ['<rootDir>/packages'],
|
||||
testEnvironment: 'node',
|
||||
testMatch: ['**/__tests__/*.test.ts'],
|
||||
testRunner: 'jest-circus/runner',
|
||||
transform: {
|
||||
'^.+\\.ts$': 'ts-jest'
|
||||
},
|
||||
|
||||
Generated
+9911
-26106
File diff suppressed because it is too large
Load Diff
+15
-17
@@ -2,31 +2,29 @@
|
||||
"name": "root",
|
||||
"private": true,
|
||||
"scripts": {
|
||||
"audit-all": "lerna run audit-moderate",
|
||||
"bootstrap": "lerna bootstrap",
|
||||
"build": "lerna run tsc",
|
||||
"check-all": "concurrently \"npm:format-check\" \"npm:lint\" \"npm:test\" \"npm:build -- -- --noEmit\"",
|
||||
"format": "prettier --write packages/**/*.ts",
|
||||
"format-check": "prettier --check packages/**/*.ts",
|
||||
"lint": "eslint packages/**/*.ts",
|
||||
"lint-fix": "eslint packages/**/*.ts --fix",
|
||||
"new-package": "scripts/create-package",
|
||||
"test": "jest --testTimeout 10000"
|
||||
"test": "jest"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@types/jest": "^27.0.2",
|
||||
"@types/node": "^16.18.1",
|
||||
"@types/signale": "^1.4.1",
|
||||
"@typescript-eslint/parser": "^4.0.0",
|
||||
"concurrently": "^6.1.0",
|
||||
"eslint": "^7.23.0",
|
||||
"eslint-plugin-github": "^4.1.3",
|
||||
"eslint-plugin-jest": "^22.21.0",
|
||||
"flow-bin": "^0.115.0",
|
||||
"jest": "^27.2.5",
|
||||
"lerna": "^5.4.0",
|
||||
"prettier": "^1.19.1",
|
||||
"ts-jest": "^27.0.5",
|
||||
"typescript": "^3.9.9"
|
||||
"@types/jest": "^24.0.11",
|
||||
"@types/node": "^11.13.5",
|
||||
"@types/signale": "^1.2.1",
|
||||
"@typescript-eslint/parser": "^1.9.0",
|
||||
"concurrently": "^4.1.0",
|
||||
"eslint": "^5.16.0",
|
||||
"eslint-plugin-github": "^2.0.0",
|
||||
"eslint-plugin-jest": "^22.5.1",
|
||||
"jest": "^24.9.0",
|
||||
"jest-circus": "^24.7.1",
|
||||
"lerna": "^3.18.4",
|
||||
"prettier": "^1.17.0",
|
||||
"ts-jest": "^24.0.2",
|
||||
"typescript": "^3.6.2"
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,30 +0,0 @@
|
||||
# Contributions
|
||||
|
||||
This package is used internally by the v2+ versions of [upload-artifact](https://github.com/actions/upload-artifact) and [download-artifact](https://github.com/actions/download-artifact). This package can also be used by other actions to interact with artifacts. Any changes or updates to this package will propagate updates to these actions so it is important that major changes or updates get properly tested.
|
||||
|
||||
Any issues or feature requests that are related to the artifact actions should be filled in the appropriate repo.
|
||||
|
||||
A limited range of unit tests run as part of each PR when making changes to the artifact packages. For small contributions and fixes, they should be sufficient.
|
||||
|
||||
If making large changes, there are a few scenarios that should be tested.
|
||||
|
||||
- Uploading very large artifacts (large artifacts get compressed using gzip so compression/decompression must be tested)
|
||||
- Uploading artifacts with lots of small files (each file is uploaded with its own HTTP call, timeouts and non-success HTTP responses can be expected so they must be properly handled)
|
||||
- Uploading artifacts using a self-hosted runner (uploads and downloads behave differently due to extra latency)
|
||||
- Downloading a single artifact (large and small, if lots of small files are part of an artifact, timeouts and non-success HTTP responses can be expected)
|
||||
- Downloading all artifacts at once
|
||||
|
||||
Large architectural changes can impact upload/download performance so it is important to separately run extra tests. We request that any large contributions/changes have extra detailed testing so we can verify performance and possible regressions.
|
||||
|
||||
It is not possible to run end-to-end tests for artifacts as part of a PR in this repo because certain env variables such as `ACTIONS_RUNTIME_URL` are only available from the context of an action as opposed to a shell script. These env variables are needed in order to make the necessary API calls.
|
||||
|
||||
# Testing
|
||||
|
||||
Any easy way to test changes is to fork the artifact actions and to use `npm link` to test your changes.
|
||||
|
||||
1. Fork the [upload-artifact](https://github.com/actions/upload-artifact) and [download-artifact](https://github.com/actions/download-artifact) repos
|
||||
2. Clone the forks locally
|
||||
3. With your local changes to the toolkit repo, type `npm link` after ensuring there are no errors when running `tsc`
|
||||
4. In the locally cloned fork, type `npm link @actions/artifact`
|
||||
4. Create a new release for your local fork using `tsc` and `npm run release` (this will create a new `dist/index.js` file using `@vercel/ncc`)
|
||||
5. Commit and push your local changes, you will then be able to test your changes with your forked action
|
||||
@@ -1,9 +0,0 @@
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright 2019 GitHub
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
||||
@@ -1,213 +0,0 @@
|
||||
# `@actions/artifact`
|
||||
|
||||
## Usage
|
||||
|
||||
You can use this package to interact with the actions artifacts.
|
||||
- [Upload an Artifact](#Upload-an-Artifact)
|
||||
- [Download a Single Artifact](#Download-a-Single-Artifact)
|
||||
- [Download All Artifacts](#Download-all-Artifacts)
|
||||
- [Additional Documentation](#Additional-Documentation)
|
||||
- [Contributions](#Contributions)
|
||||
|
||||
Relative paths and absolute paths are both allowed. Relative paths are rooted against the current working directory.
|
||||
|
||||
## Upload an Artifact
|
||||
|
||||
Method Name: `uploadArtifact`
|
||||
|
||||
#### Inputs
|
||||
- `name`
|
||||
- The name of the artifact that is being uploaded
|
||||
- Required
|
||||
- `files`
|
||||
- A list of file paths that describe what should be uploaded as part of the artifact
|
||||
- If a path is provided that does not exist, an error will be thrown
|
||||
- Can be absolute or relative. Internally everything is normalized and resolved
|
||||
- Required
|
||||
- `rootDirectory`
|
||||
- A file path that denotes the root directory of the files being uploaded. This path is used to strip the paths provided in `files` to control how they are uploaded and structured
|
||||
- If a file specified in `files` is not in the `rootDirectory`, an error will be thrown
|
||||
- Required
|
||||
- `options`
|
||||
- Extra options that allow for the customization of the upload behavior
|
||||
- Optional
|
||||
|
||||
#### Available Options
|
||||
|
||||
- `continueOnError`
|
||||
- Indicates if the artifact upload should continue in the event a file fails to upload. If there is a error during upload, a partial artifact will always be created and available for download at the end. The `size` reported will be the amount of storage that the user or org will be charged for the partial artifact.
|
||||
- If set to `false`, and an error is encountered, all other uploads will stop and any files that were queued will not be attempted to be uploaded. The partial artifact available will only include files up until the failure.
|
||||
- If set to `true` and an error is encountered, the failed file will be skipped and ignored and all other queued files will be attempted to be uploaded. There will be an artifact available for download at the end with everything excluding the file that failed to upload
|
||||
- Optional, defaults to `true` if not specified
|
||||
- `retentionDays`
|
||||
- Duration after which artifact will expire in days
|
||||
- Minimum value: 1
|
||||
- Maximum value: 90 unless changed by repository setting
|
||||
- If this is set to a greater value than the retention settings allowed, the retention on artifacts will be reduced to match the max value allowed on the server, and the upload process will continue. An input of 0 assumes default retention value.
|
||||
|
||||
#### Example using Absolute File Paths
|
||||
|
||||
```js
|
||||
const artifact = require('@actions/artifact');
|
||||
const artifactClient = artifact.create()
|
||||
const artifactName = 'my-artifact';
|
||||
const files = [
|
||||
'/home/user/files/plz-upload/file1.txt',
|
||||
'/home/user/files/plz-upload/file2.txt',
|
||||
'/home/user/files/plz-upload/dir/file3.txt'
|
||||
]
|
||||
const rootDirectory = '/home/user/files/plz-upload'
|
||||
const options = {
|
||||
continueOnError: true
|
||||
}
|
||||
|
||||
const uploadResult = await artifactClient.uploadArtifact(artifactName, files, rootDirectory, options)
|
||||
```
|
||||
|
||||
#### Example using Relative File Paths
|
||||
```js
|
||||
// Assuming the current working directory is /home/user/files/plz-upload
|
||||
const artifact = require('@actions/artifact');
|
||||
const artifactClient = artifact.create()
|
||||
const artifactName = 'my-artifact';
|
||||
const files = [
|
||||
'file1.txt',
|
||||
'file2.txt',
|
||||
'dir/file3.txt'
|
||||
]
|
||||
|
||||
const rootDirectory = '.' // Also possible to use __dirname
|
||||
const options = {
|
||||
continueOnError: false
|
||||
}
|
||||
|
||||
const uploadResponse = await artifactClient.uploadArtifact(artifactName, files, rootDirectory, options)
|
||||
```
|
||||
|
||||
#### Upload Result
|
||||
|
||||
The returned `UploadResponse` will contain the following information
|
||||
|
||||
- `artifactName`
|
||||
- The name of the artifact that was uploaded
|
||||
- `artifactItems`
|
||||
- A list of all files that describe what is uploaded if there are no errors encountered. Usually this will be equal to the inputted `files` with the exception of empty directories (will not be uploaded)
|
||||
- `size`
|
||||
- Total size of the artifact that was uploaded in bytes
|
||||
- `failedItems`
|
||||
- A list of items that were not uploaded successfully (this will include queued items that were not uploaded if `continueOnError` is set to false). This is a subset of `artifactItems`
|
||||
|
||||
## Download a Single Artifact
|
||||
|
||||
Method Name: `downloadArtifact`
|
||||
|
||||
#### Inputs
|
||||
- `name`
|
||||
- The name of the artifact to download
|
||||
- Required
|
||||
- `path`
|
||||
- Path that denotes where the artifact will be downloaded to
|
||||
- Optional. Defaults to the GitHub workspace directory(`$GITHUB_WORKSPACE`) if not specified
|
||||
- `options`
|
||||
- Extra options that allow for the customization of the download behavior
|
||||
- Optional
|
||||
|
||||
|
||||
#### Available Options
|
||||
|
||||
- `createArtifactFolder`
|
||||
- Specifies if a folder (the artifact name) is created for the artifact that is downloaded (contents downloaded into this folder),
|
||||
- Optional. Defaults to false if not specified
|
||||
|
||||
#### Example
|
||||
|
||||
```js
|
||||
const artifact = require('@actions/artifact');
|
||||
const artifactClient = artifact.create()
|
||||
const artifactName = 'my-artifact';
|
||||
const path = 'some/directory'
|
||||
const options = {
|
||||
createArtifactFolder: false
|
||||
}
|
||||
|
||||
const downloadResponse = await artifactClient.downloadArtifact(artifactName, path, options)
|
||||
|
||||
// Post download, the directory structure will look like this
|
||||
/some
|
||||
/directory
|
||||
/file1.txt
|
||||
/file2.txt
|
||||
/dir
|
||||
/file3.txt
|
||||
|
||||
// If createArtifactFolder is set to true, the directory structure will look like this
|
||||
/some
|
||||
/directory
|
||||
/my-artifact
|
||||
/file1.txt
|
||||
/file2.txt
|
||||
/dir
|
||||
/file3.txt
|
||||
```
|
||||
|
||||
#### Download Response
|
||||
|
||||
The returned `DownloadResponse` will contain the following information
|
||||
|
||||
- `artifactName`
|
||||
- The name of the artifact that was downloaded
|
||||
- `downloadPath`
|
||||
- The full Path to where the artifact was downloaded
|
||||
|
||||
|
||||
## Download All Artifacts
|
||||
|
||||
Method Name: `downloadAllArtifacts`
|
||||
|
||||
#### Inputs
|
||||
- `path`
|
||||
- Path that denotes where the artifact will be downloaded to
|
||||
- Optional. Defaults to the GitHub workspace directory(`$GITHUB_WORKSPACE`) if not specified
|
||||
|
||||
```js
|
||||
const artifact = require('@actions/artifact');
|
||||
const artifactClient = artifact.create();
|
||||
const downloadResponse = await artifactClient.downloadAllArtifacts();
|
||||
|
||||
// output result
|
||||
for (response in downloadResponse) {
|
||||
console.log(response.artifactName);
|
||||
console.log(response.downloadPath);
|
||||
}
|
||||
```
|
||||
|
||||
Because there are multiple artifacts, an extra directory (denoted by the name of the artifact) will be created for each artifact in the path. With 2 artifacts(`my-artifact-1` and `my-artifact-2` for example) and the default path, the directory structure will be as follows:
|
||||
```js
|
||||
/GITHUB_WORKSPACE
|
||||
/my-artifact-1
|
||||
/ .. contents of `my-artifact-1`
|
||||
/my-artifact-2
|
||||
/ .. contents of `my-artifact-2`
|
||||
```
|
||||
|
||||
#### Download Result
|
||||
|
||||
An array will be returned that describes the results for downloading all artifacts. The number of items in the array indicates the number of artifacts that were downloaded.
|
||||
|
||||
Each artifact will have the same `DownloadResponse` as if it was individually downloaded
|
||||
- `artifactName`
|
||||
- The name of the artifact that was downloaded
|
||||
- `downloadPath`
|
||||
- The full Path to where the artifact was downloaded
|
||||
|
||||
## Additional Documentation
|
||||
|
||||
Check out [additional-information](docs/additional-information.md) for extra documentation around usage, restrictions and behavior.
|
||||
|
||||
Check out [implementation-details](docs/implementation-details.md) for extra information about the implementation of this package.
|
||||
|
||||
## Contributions
|
||||
|
||||
See [contributor guidelines](https://github.com/actions/toolkit/blob/main/.github/CONTRIBUTING.md) for general guidelines and information about toolkit contributions.
|
||||
|
||||
For contributions related to this package, see [artifact contributions](CONTRIBUTIONS.md) for more information.
|
||||
@@ -1,96 +0,0 @@
|
||||
# @actions/artifact Releases
|
||||
|
||||
### 0.1.0
|
||||
|
||||
- Initial release
|
||||
|
||||
### 0.2.0
|
||||
|
||||
- Fixes to TCP connections not closing
|
||||
- GZip file compression to speed up downloads
|
||||
- Improved logging and output
|
||||
- Extra documentation
|
||||
|
||||
### 0.3.0
|
||||
|
||||
- Fixes to gzip decompression when downloading artifacts
|
||||
- Support handling 429 response codes
|
||||
- Improved download experience when dealing with empty files
|
||||
- Exponential backoff when retryable status codes are encountered
|
||||
- Clearer error message if storage quota has been reached
|
||||
- Improved logging and output during artifact download
|
||||
|
||||
### 0.3.1
|
||||
|
||||
- Fix to ensure temporary gzip files get correctly deleted during artifact upload
|
||||
- Remove spaces as a forbidden character during upload
|
||||
|
||||
### 0.3.2
|
||||
|
||||
- Fix to ensure readstreams get correctly reset in the event of a retry
|
||||
|
||||
### 0.3.3
|
||||
|
||||
- Increase chunk size during upload from 4MB to 8MB
|
||||
- Improve user-agent strings during API calls to help internally diagnose issues
|
||||
|
||||
### 0.3.5
|
||||
|
||||
- Retry in the event of a 413 response
|
||||
|
||||
### 0.4.0
|
||||
|
||||
- Add option to specify custom retentions on artifacts
|
||||
|
||||
### 0.4.1
|
||||
|
||||
- Update to latest @actions/core version
|
||||
|
||||
### 0.4.2
|
||||
|
||||
- Improved retry-ability when a partial artifact download is encountered
|
||||
|
||||
### 0.5.0
|
||||
|
||||
- Improved retry-ability for all http calls during artifact upload and download if an error is encountered
|
||||
|
||||
### 0.5.1
|
||||
|
||||
- Bump @actions/http-client to version 1.0.11 to fix proxy related issues during artifact upload and download
|
||||
|
||||
### 0.5.2
|
||||
|
||||
- Add HTTP 500 as a retryable status code for artifact upload and download.
|
||||
|
||||
### 0.6.0
|
||||
|
||||
- Support upload from named pipes [#748](https://github.com/actions/toolkit/pull/748)
|
||||
- Fixes to percentage values being greater than 100% when downloading all artifacts [#889](https://github.com/actions/toolkit/pull/889)
|
||||
- Improved logging and output during artifact upload [#949](https://github.com/actions/toolkit/pull/949)
|
||||
- Improvements to client-side validation for certain invalid characters not allowed during upload: [#951](https://github.com/actions/toolkit/pull/951)
|
||||
- Faster upload speeds for certain types of large files by exempting gzip compression [#956](https://github.com/actions/toolkit/pull/956)
|
||||
- More detailed logging when dealing with chunked uploads [#957](https://github.com/actions/toolkit/pull/957)
|
||||
|
||||
### 0.6.1
|
||||
|
||||
- Fix for failing 0 byte file uploads on Windows [#962](https://github.com/actions/toolkit/pull/962)
|
||||
|
||||
### 1.0.0
|
||||
|
||||
- Update `lockfileVersion` to `v2` in `package-lock.json` [#1009](https://github.com/actions/toolkit/pull/1009)
|
||||
|
||||
### 1.0.1
|
||||
|
||||
- Update to v2.0.0 of `@actions/http-client`
|
||||
|
||||
### 1.0.2
|
||||
|
||||
- Update to v2.0.1 of `@actions/http-client` [#1087](https://github.com/actions/toolkit/pull/1087)
|
||||
|
||||
### 1.1.0
|
||||
|
||||
- Add `x-actions-results-crc64` and `x-actions-results-md5` checksum headers on upload [#1063](https://github.com/actions/toolkit/pull/1063)
|
||||
|
||||
### 1.1.1
|
||||
|
||||
- Fixed a bug in Node16 where if an HTTP download finished too quickly (<1ms, e.g. when it's mocked) we attempt to delete a temp file that has not been created yet [#1278](https://github.com/actions/toolkit/pull/1278/commits/b9de68a590daf37c6747e38d3cb4f1dd2cfb791c)
|
||||
@@ -1,5 +0,0 @@
|
||||
name: 'Set env variables'
|
||||
description: 'Sets certain env variables so that e2e artifact upload and download can be tested in a shell'
|
||||
runs:
|
||||
using: 'node12'
|
||||
main: 'index.js'
|
||||
@@ -1,14 +0,0 @@
|
||||
// Certain env variables are not set by default in a shell context and are only available in a node context from a running action
|
||||
// In order to be able to upload and download artifacts e2e in a shell when running CI tests, we need these env variables set
|
||||
const fs = require('fs');
|
||||
const os = require('os');
|
||||
const filePath = process.env[`GITHUB_ENV`]
|
||||
fs.appendFileSync(filePath, `ACTIONS_RUNTIME_URL=${process.env.ACTIONS_RUNTIME_URL}${os.EOL}`, {
|
||||
encoding: 'utf8'
|
||||
})
|
||||
fs.appendFileSync(filePath, `ACTIONS_RUNTIME_TOKEN=${process.env.ACTIONS_RUNTIME_TOKEN}${os.EOL}`, {
|
||||
encoding: 'utf8'
|
||||
})
|
||||
fs.appendFileSync(filePath, `GITHUB_RUN_ID=${process.env.GITHUB_RUN_ID}${os.EOL}`, {
|
||||
encoding: 'utf8'
|
||||
})
|
||||
@@ -1,57 +0,0 @@
|
||||
import CRC64, {CRC64DigestEncoding} from '../src/internal/crc64'
|
||||
|
||||
const fixtures = {
|
||||
data:
|
||||
'🚀 👉😎👉 Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.\nUt enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.\nDuis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.\nExcepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n',
|
||||
expected: {
|
||||
hex: '846CE4ADAD6223ED',
|
||||
base64: '7SNira3kbIQ=',
|
||||
buffer: Buffer.from([0xed, 0x23, 0x62, 0xad, 0xad, 0xe4, 0x6c, 0x84])
|
||||
}
|
||||
}
|
||||
|
||||
function assertEncodings(crc: CRC64): void {
|
||||
const encodings = Object.keys(fixtures.expected) as CRC64DigestEncoding[]
|
||||
for (const encoding of encodings) {
|
||||
expect(crc.digest(encoding)).toEqual(fixtures.expected[encoding])
|
||||
}
|
||||
}
|
||||
|
||||
describe('@actions/artifact/src/internal/crc64', () => {
|
||||
it('CRC64 from string', async () => {
|
||||
const crc = new CRC64()
|
||||
crc.update(fixtures.data)
|
||||
|
||||
assertEncodings(crc)
|
||||
})
|
||||
|
||||
it('CRC64 from buffer', async () => {
|
||||
const crc = new CRC64()
|
||||
const buf = Buffer.from(fixtures.data)
|
||||
crc.update(buf)
|
||||
|
||||
assertEncodings(crc)
|
||||
})
|
||||
|
||||
it('CRC64 from split data', async () => {
|
||||
const crc = new CRC64()
|
||||
const splits = fixtures.data.split('\n').slice(0, -1)
|
||||
for (const split of splits) {
|
||||
crc.update(`${split}\n`)
|
||||
}
|
||||
|
||||
assertEncodings(crc)
|
||||
})
|
||||
|
||||
it('flips 64 bits', async () => {
|
||||
const tests = [
|
||||
[BigInt(0), BigInt('0xffffffffffffffff')],
|
||||
[BigInt('0xffffffffffffffff'), BigInt(0)],
|
||||
[BigInt('0xdeadbeef'), BigInt('0xffffffff21524110')]
|
||||
]
|
||||
|
||||
for (const [input, expected] of tests) {
|
||||
expect(CRC64.flip64Bits(input)).toEqual(expected)
|
||||
}
|
||||
})
|
||||
})
|
||||
@@ -1,552 +0,0 @@
|
||||
import * as path from 'path'
|
||||
import * as core from '@actions/core'
|
||||
import {URL} from 'url'
|
||||
import {getDownloadSpecification} from '../src/internal/download-specification'
|
||||
import {ContainerEntry} from '../src/internal/contracts'
|
||||
|
||||
const artifact1Name = 'my-artifact'
|
||||
const artifact2Name = 'my-artifact-extra'
|
||||
|
||||
// Populating with only the information that is necessary
|
||||
function getPartialContainerEntry(): ContainerEntry {
|
||||
return {
|
||||
containerId: 10,
|
||||
scopeIdentifier: '00000000-0000-0000-0000-000000000000',
|
||||
path: 'ADD_INFORMATION',
|
||||
itemType: 'ADD_INFORMATION',
|
||||
status: 'created',
|
||||
dateCreated: '2020-02-06T22:13:35.373Z',
|
||||
dateLastModified: '2020-02-06T22:13:35.453Z',
|
||||
createdBy: '82f0bf89-6e55-4e5a-b8b6-f75eb992578c',
|
||||
lastModifiedBy: '82f0bf89-6e55-4e5a-b8b6-f75eb992578c',
|
||||
itemLocation: 'ADD_INFORMATION',
|
||||
contentLocation: 'ADD_INFORMATION',
|
||||
contentId: '',
|
||||
fileLength: 100
|
||||
}
|
||||
}
|
||||
|
||||
function createFileEntry(entryPath: string): ContainerEntry {
|
||||
const newFileEntry = getPartialContainerEntry()
|
||||
newFileEntry.path = entryPath
|
||||
newFileEntry.itemType = 'file'
|
||||
newFileEntry.itemLocation = createItemLocation(entryPath)
|
||||
newFileEntry.contentLocation = createContentLocation(entryPath)
|
||||
return newFileEntry
|
||||
}
|
||||
|
||||
function createDirectoryEntry(directoryPath: string): ContainerEntry {
|
||||
const newDirectoryEntry = getPartialContainerEntry()
|
||||
newDirectoryEntry.path = directoryPath
|
||||
newDirectoryEntry.itemType = 'folder'
|
||||
newDirectoryEntry.itemLocation = createItemLocation(directoryPath)
|
||||
newDirectoryEntry.contentLocation = createContentLocation(directoryPath)
|
||||
return newDirectoryEntry
|
||||
}
|
||||
|
||||
function createItemLocation(relativePath: string): string {
|
||||
const itemLocation = new URL(
|
||||
'https://testing/_apis/resources/Containers/10000'
|
||||
)
|
||||
itemLocation.searchParams.append('itemPath', relativePath)
|
||||
itemLocation.searchParams.append('metadata', 'true')
|
||||
return itemLocation.toString()
|
||||
}
|
||||
|
||||
function createContentLocation(relativePath: string): string {
|
||||
const itemLocation = new URL(
|
||||
'https://testing/_apis/resources/Containers/10000'
|
||||
)
|
||||
itemLocation.searchParams.append('itemPath', relativePath)
|
||||
return itemLocation.toString()
|
||||
}
|
||||
|
||||
/*
|
||||
Represents a set of container entries for two artifacts with the following directory structure
|
||||
|
||||
/my-artifact
|
||||
/file1.txt
|
||||
/file2.txt
|
||||
/dir1
|
||||
/file3.txt
|
||||
/dir2
|
||||
/dir3
|
||||
/dir4
|
||||
file4.txt
|
||||
file5.txt (no length property)
|
||||
file6.txt (empty file)
|
||||
/my-artifact-extra
|
||||
/file1.txt
|
||||
*/
|
||||
|
||||
// main artifact
|
||||
const file1Path = path.join(artifact1Name, 'file1.txt')
|
||||
const file2Path = path.join(artifact1Name, 'file2.txt')
|
||||
const dir1Path = path.join(artifact1Name, 'dir1')
|
||||
const file3Path = path.join(dir1Path, 'file3.txt')
|
||||
const dir2Path = path.join(dir1Path, 'dir2')
|
||||
const dir3Path = path.join(dir2Path, 'dir3')
|
||||
const dir4Path = path.join(dir3Path, 'dir4')
|
||||
const file4Path = path.join(dir4Path, 'file4.txt')
|
||||
const file5Path = path.join(dir4Path, 'file5.txt')
|
||||
const file6Path = path.join(dir4Path, 'file6.txt')
|
||||
|
||||
const rootDirectoryEntry = createDirectoryEntry(artifact1Name)
|
||||
const directoryEntry1 = createDirectoryEntry(dir1Path)
|
||||
const directoryEntry2 = createDirectoryEntry(dir2Path)
|
||||
const directoryEntry3 = createDirectoryEntry(dir3Path)
|
||||
const directoryEntry4 = createDirectoryEntry(dir4Path)
|
||||
const fileEntry1 = createFileEntry(file1Path)
|
||||
const fileEntry2 = createFileEntry(file2Path)
|
||||
const fileEntry3 = createFileEntry(file3Path)
|
||||
const fileEntry4 = createFileEntry(file4Path)
|
||||
|
||||
const missingLengthFileEntry = createFileEntry(file5Path)
|
||||
missingLengthFileEntry.fileLength = undefined // one file does not have a fileLength
|
||||
const emptyLengthFileEntry = createFileEntry(file6Path)
|
||||
emptyLengthFileEntry.fileLength = 0 // empty file path
|
||||
|
||||
// extra artifact
|
||||
const artifact2File1Path = path.join(artifact2Name, 'file1.txt')
|
||||
const rootDirectoryEntry2 = createDirectoryEntry(artifact2Name)
|
||||
const extraFileEntry = createFileEntry(artifact2File1Path)
|
||||
|
||||
const artifactContainerEntries: ContainerEntry[] = [
|
||||
rootDirectoryEntry,
|
||||
fileEntry1,
|
||||
fileEntry2,
|
||||
directoryEntry1,
|
||||
fileEntry3,
|
||||
directoryEntry2,
|
||||
directoryEntry3,
|
||||
directoryEntry4,
|
||||
fileEntry4,
|
||||
missingLengthFileEntry,
|
||||
emptyLengthFileEntry,
|
||||
rootDirectoryEntry2,
|
||||
extraFileEntry
|
||||
]
|
||||
|
||||
describe('Search', () => {
|
||||
beforeAll(async () => {
|
||||
// mock all output so that there is less noise when running tests
|
||||
jest.spyOn(console, 'log').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'debug').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'info').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'warning').mockImplementation(() => {})
|
||||
})
|
||||
|
||||
it('Download Specification - Absolute Path with no root directory', () => {
|
||||
const testDownloadPath = path.join(
|
||||
__dirname,
|
||||
'some',
|
||||
'destination',
|
||||
'folder'
|
||||
)
|
||||
|
||||
const specification = getDownloadSpecification(
|
||||
artifact1Name,
|
||||
artifactContainerEntries,
|
||||
testDownloadPath,
|
||||
false
|
||||
)
|
||||
|
||||
expect(specification.rootDownloadLocation).toEqual(testDownloadPath)
|
||||
expect(specification.filesToDownload.length).toEqual(5)
|
||||
|
||||
const item1ExpectedTargetPath = path.join(testDownloadPath, 'file1.txt')
|
||||
const item2ExpectedTargetPath = path.join(testDownloadPath, 'file2.txt')
|
||||
const item3ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
'dir1',
|
||||
'file3.txt'
|
||||
)
|
||||
const item4ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
'dir1',
|
||||
'dir2',
|
||||
'dir3',
|
||||
'dir4',
|
||||
'file4.txt'
|
||||
)
|
||||
const item5ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
'dir1',
|
||||
'dir2',
|
||||
'dir3',
|
||||
'dir4',
|
||||
'file5.txt'
|
||||
)
|
||||
const item6ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
'dir1',
|
||||
'dir2',
|
||||
'dir3',
|
||||
'dir4',
|
||||
'file6.txt'
|
||||
)
|
||||
|
||||
const targetLocations = specification.filesToDownload.map(
|
||||
item => item.targetPath
|
||||
)
|
||||
expect(targetLocations).toContain(item1ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item2ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item3ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item4ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item5ExpectedTargetPath)
|
||||
|
||||
for (const downloadItem of specification.filesToDownload) {
|
||||
if (downloadItem.targetPath === item1ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file1Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item2ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file2Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item3ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file3Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item4ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file4Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item5ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file5Path)
|
||||
)
|
||||
} else {
|
||||
throw new Error('this should never be reached')
|
||||
}
|
||||
}
|
||||
|
||||
expect(specification.directoryStructure.length).toEqual(3)
|
||||
expect(specification.directoryStructure).toContain(testDownloadPath)
|
||||
expect(specification.directoryStructure).toContain(
|
||||
path.join(testDownloadPath, 'dir1')
|
||||
)
|
||||
expect(specification.directoryStructure).toContain(
|
||||
path.join(testDownloadPath, 'dir1', 'dir2', 'dir3', 'dir4')
|
||||
)
|
||||
|
||||
expect(specification.emptyFilesToCreate.length).toEqual(1)
|
||||
expect(specification.emptyFilesToCreate).toContain(item6ExpectedTargetPath)
|
||||
})
|
||||
|
||||
it('Download Specification - Relative Path with no root directory', () => {
|
||||
const testDownloadPath = path.join('some', 'destination', 'folder')
|
||||
|
||||
const specification = getDownloadSpecification(
|
||||
artifact1Name,
|
||||
artifactContainerEntries,
|
||||
testDownloadPath,
|
||||
false
|
||||
)
|
||||
|
||||
expect(specification.rootDownloadLocation).toEqual(testDownloadPath)
|
||||
expect(specification.filesToDownload.length).toEqual(5)
|
||||
|
||||
const item1ExpectedTargetPath = path.join(testDownloadPath, 'file1.txt')
|
||||
const item2ExpectedTargetPath = path.join(testDownloadPath, 'file2.txt')
|
||||
const item3ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
'dir1',
|
||||
'file3.txt'
|
||||
)
|
||||
const item4ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
'dir1',
|
||||
'dir2',
|
||||
'dir3',
|
||||
'dir4',
|
||||
'file4.txt'
|
||||
)
|
||||
const item5ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
'dir1',
|
||||
'dir2',
|
||||
'dir3',
|
||||
'dir4',
|
||||
'file5.txt'
|
||||
)
|
||||
const item6ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
'dir1',
|
||||
'dir2',
|
||||
'dir3',
|
||||
'dir4',
|
||||
'file6.txt'
|
||||
)
|
||||
|
||||
const targetLocations = specification.filesToDownload.map(
|
||||
item => item.targetPath
|
||||
)
|
||||
expect(targetLocations).toContain(item1ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item2ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item3ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item4ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item5ExpectedTargetPath)
|
||||
|
||||
for (const downloadItem of specification.filesToDownload) {
|
||||
if (downloadItem.targetPath === item1ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file1Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item2ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file2Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item3ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file3Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item4ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file4Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item5ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file5Path)
|
||||
)
|
||||
} else {
|
||||
throw new Error('this should never be reached')
|
||||
}
|
||||
}
|
||||
|
||||
expect(specification.directoryStructure.length).toEqual(3)
|
||||
expect(specification.directoryStructure).toContain(testDownloadPath)
|
||||
expect(specification.directoryStructure).toContain(
|
||||
path.join(testDownloadPath, 'dir1')
|
||||
)
|
||||
expect(specification.directoryStructure).toContain(
|
||||
path.join(testDownloadPath, 'dir1', 'dir2', 'dir3', 'dir4')
|
||||
)
|
||||
|
||||
expect(specification.emptyFilesToCreate.length).toEqual(1)
|
||||
expect(specification.emptyFilesToCreate).toContain(item6ExpectedTargetPath)
|
||||
})
|
||||
|
||||
it('Download Specification - Absolute Path with root directory', () => {
|
||||
const testDownloadPath = path.join(
|
||||
__dirname,
|
||||
'some',
|
||||
'destination',
|
||||
'folder'
|
||||
)
|
||||
|
||||
const specification = getDownloadSpecification(
|
||||
artifact1Name,
|
||||
artifactContainerEntries,
|
||||
testDownloadPath,
|
||||
true
|
||||
)
|
||||
|
||||
expect(specification.rootDownloadLocation).toEqual(
|
||||
path.join(testDownloadPath, artifact1Name)
|
||||
)
|
||||
expect(specification.filesToDownload.length).toEqual(5)
|
||||
|
||||
const item1ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
artifact1Name,
|
||||
'file1.txt'
|
||||
)
|
||||
const item2ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
artifact1Name,
|
||||
'file2.txt'
|
||||
)
|
||||
const item3ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
artifact1Name,
|
||||
'dir1',
|
||||
'file3.txt'
|
||||
)
|
||||
const item4ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
artifact1Name,
|
||||
'dir1',
|
||||
'dir2',
|
||||
'dir3',
|
||||
'dir4',
|
||||
'file4.txt'
|
||||
)
|
||||
const item5ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
artifact1Name,
|
||||
'dir1',
|
||||
'dir2',
|
||||
'dir3',
|
||||
'dir4',
|
||||
'file5.txt'
|
||||
)
|
||||
const item6ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
artifact1Name,
|
||||
'dir1',
|
||||
'dir2',
|
||||
'dir3',
|
||||
'dir4',
|
||||
'file6.txt'
|
||||
)
|
||||
|
||||
const targetLocations = specification.filesToDownload.map(
|
||||
item => item.targetPath
|
||||
)
|
||||
expect(targetLocations).toContain(item1ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item2ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item3ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item4ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item5ExpectedTargetPath)
|
||||
|
||||
for (const downloadItem of specification.filesToDownload) {
|
||||
if (downloadItem.targetPath === item1ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file1Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item2ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file2Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item3ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file3Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item4ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file4Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item5ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file5Path)
|
||||
)
|
||||
} else {
|
||||
throw new Error('this should never be reached')
|
||||
}
|
||||
}
|
||||
|
||||
expect(specification.directoryStructure.length).toEqual(3)
|
||||
expect(specification.directoryStructure).toContain(
|
||||
path.join(testDownloadPath, artifact1Name)
|
||||
)
|
||||
expect(specification.directoryStructure).toContain(
|
||||
path.join(testDownloadPath, dir1Path)
|
||||
)
|
||||
expect(specification.directoryStructure).toContain(
|
||||
path.join(testDownloadPath, dir4Path)
|
||||
)
|
||||
|
||||
expect(specification.emptyFilesToCreate.length).toEqual(1)
|
||||
expect(specification.emptyFilesToCreate).toContain(item6ExpectedTargetPath)
|
||||
})
|
||||
|
||||
it('Download Specification - Relative Path with root directory', () => {
|
||||
const testDownloadPath = path.join('some', 'destination', 'folder')
|
||||
|
||||
const specification = getDownloadSpecification(
|
||||
artifact1Name,
|
||||
artifactContainerEntries,
|
||||
testDownloadPath,
|
||||
true
|
||||
)
|
||||
|
||||
expect(specification.rootDownloadLocation).toEqual(
|
||||
path.join(testDownloadPath, artifact1Name)
|
||||
)
|
||||
expect(specification.filesToDownload.length).toEqual(5)
|
||||
|
||||
const item1ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
artifact1Name,
|
||||
'file1.txt'
|
||||
)
|
||||
const item2ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
artifact1Name,
|
||||
'file2.txt'
|
||||
)
|
||||
const item3ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
artifact1Name,
|
||||
'dir1',
|
||||
'file3.txt'
|
||||
)
|
||||
const item4ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
artifact1Name,
|
||||
'dir1',
|
||||
'dir2',
|
||||
'dir3',
|
||||
'dir4',
|
||||
'file4.txt'
|
||||
)
|
||||
const item5ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
artifact1Name,
|
||||
'dir1',
|
||||
'dir2',
|
||||
'dir3',
|
||||
'dir4',
|
||||
'file5.txt'
|
||||
)
|
||||
const item6ExpectedTargetPath = path.join(
|
||||
testDownloadPath,
|
||||
artifact1Name,
|
||||
'dir1',
|
||||
'dir2',
|
||||
'dir3',
|
||||
'dir4',
|
||||
'file6.txt'
|
||||
)
|
||||
|
||||
const targetLocations = specification.filesToDownload.map(
|
||||
item => item.targetPath
|
||||
)
|
||||
expect(targetLocations).toContain(item1ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item2ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item3ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item4ExpectedTargetPath)
|
||||
expect(targetLocations).toContain(item5ExpectedTargetPath)
|
||||
|
||||
for (const downloadItem of specification.filesToDownload) {
|
||||
if (downloadItem.targetPath === item1ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file1Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item2ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file2Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item3ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file3Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item4ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file4Path)
|
||||
)
|
||||
} else if (downloadItem.targetPath === item5ExpectedTargetPath) {
|
||||
expect(downloadItem.sourceLocation).toEqual(
|
||||
createContentLocation(file5Path)
|
||||
)
|
||||
} else {
|
||||
throw new Error('this should never be reached')
|
||||
}
|
||||
}
|
||||
|
||||
expect(specification.directoryStructure.length).toEqual(3)
|
||||
expect(specification.directoryStructure).toContain(
|
||||
path.join(testDownloadPath, artifact1Name)
|
||||
)
|
||||
expect(specification.directoryStructure).toContain(
|
||||
path.join(testDownloadPath, dir1Path)
|
||||
)
|
||||
expect(specification.directoryStructure).toContain(
|
||||
path.join(testDownloadPath, dir4Path)
|
||||
)
|
||||
|
||||
expect(specification.emptyFilesToCreate.length).toEqual(1)
|
||||
expect(specification.emptyFilesToCreate).toContain(item6ExpectedTargetPath)
|
||||
})
|
||||
})
|
||||
@@ -1,490 +0,0 @@
|
||||
import * as core from '@actions/core'
|
||||
import * as http from 'http'
|
||||
import * as io from '../../io/src/io'
|
||||
import * as net from 'net'
|
||||
import * as path from 'path'
|
||||
import * as configVariables from '../src/internal/config-variables'
|
||||
import {promises as fs} from 'fs'
|
||||
import {DownloadItem} from '../src/internal/download-specification'
|
||||
import {HttpClient, HttpClientResponse} from '@actions/http-client'
|
||||
import {DownloadHttpClient} from '../src/internal/download-http-client'
|
||||
import {
|
||||
ListArtifactsResponse,
|
||||
QueryArtifactResponse
|
||||
} from '../src/internal/contracts'
|
||||
import * as stream from 'stream'
|
||||
import {gzip} from 'zlib'
|
||||
import {promisify} from 'util'
|
||||
|
||||
const root = path.join(__dirname, '_temp', 'artifact-download-tests')
|
||||
const defaultEncoding = 'utf8'
|
||||
|
||||
jest.mock('../src/internal/config-variables')
|
||||
jest.mock('@actions/http-client')
|
||||
|
||||
describe('Download Tests', () => {
|
||||
beforeAll(async () => {
|
||||
await io.rmRF(root)
|
||||
await fs.mkdir(path.join(root), {
|
||||
recursive: true
|
||||
})
|
||||
|
||||
// mock all output so that there is less noise when running tests
|
||||
jest.spyOn(console, 'log').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'debug').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'info').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'warning').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'error').mockImplementation(() => {})
|
||||
})
|
||||
|
||||
/**
|
||||
* Test Listing Artifacts
|
||||
*/
|
||||
it('List Artifacts - Success', async () => {
|
||||
setupSuccessfulListArtifactsResponse()
|
||||
const downloadHttpClient = new DownloadHttpClient()
|
||||
const artifacts = await downloadHttpClient.listArtifacts()
|
||||
expect(artifacts.count).toEqual(2)
|
||||
|
||||
const artifactNames = artifacts.value.map(item => item.name)
|
||||
expect(artifactNames).toContain('artifact1-name')
|
||||
expect(artifactNames).toContain('artifact2-name')
|
||||
|
||||
for (const artifact of artifacts.value) {
|
||||
if (artifact.name === 'artifact1-name') {
|
||||
expect(artifact.url).toEqual(
|
||||
`${configVariables.getRuntimeUrl()}_apis/pipelines/1/runs/1/artifacts?artifactName=artifact1-name`
|
||||
)
|
||||
} else if (artifact.name === 'artifact2-name') {
|
||||
expect(artifact.url).toEqual(
|
||||
`${configVariables.getRuntimeUrl()}_apis/pipelines/1/runs/1/artifacts?artifactName=artifact2-name`
|
||||
)
|
||||
} else {
|
||||
throw new Error(
|
||||
'Invalid artifact combination. This should never be reached'
|
||||
)
|
||||
}
|
||||
}
|
||||
})
|
||||
|
||||
it('List Artifacts - Failure', async () => {
|
||||
setupFailedResponse()
|
||||
const downloadHttpClient = new DownloadHttpClient()
|
||||
expect(downloadHttpClient.listArtifacts()).rejects.toThrow(
|
||||
'List Artifacts failed: Artifact service responded with 400'
|
||||
)
|
||||
})
|
||||
|
||||
/**
|
||||
* Test Container Items
|
||||
*/
|
||||
it('Container Items - Success', async () => {
|
||||
setupSuccessfulContainerItemsResponse()
|
||||
const downloadHttpClient = new DownloadHttpClient()
|
||||
const response = await downloadHttpClient.getContainerItems(
|
||||
'artifact-name',
|
||||
configVariables.getRuntimeUrl()
|
||||
)
|
||||
expect(response.count).toEqual(2)
|
||||
|
||||
const itemPaths = response.value.map(item => item.path)
|
||||
expect(itemPaths).toContain('artifact-name')
|
||||
expect(itemPaths).toContain('artifact-name/file1.txt')
|
||||
|
||||
for (const containerEntry of response.value) {
|
||||
if (containerEntry.path === 'artifact-name') {
|
||||
expect(containerEntry.itemType).toEqual('folder')
|
||||
} else if (containerEntry.path === 'artifact-name/file1.txt') {
|
||||
expect(containerEntry.itemType).toEqual('file')
|
||||
} else {
|
||||
throw new Error(
|
||||
'Invalid container combination. This should never be reached'
|
||||
)
|
||||
}
|
||||
}
|
||||
})
|
||||
|
||||
it('Container Items - Failure', async () => {
|
||||
setupFailedResponse()
|
||||
const downloadHttpClient = new DownloadHttpClient()
|
||||
expect(
|
||||
downloadHttpClient.getContainerItems(
|
||||
'artifact-name',
|
||||
configVariables.getRuntimeUrl()
|
||||
)
|
||||
).rejects.toThrow(
|
||||
`Get Container Items failed: Artifact service responded with 400`
|
||||
)
|
||||
})
|
||||
|
||||
it('Test downloading an individual artifact with gzip', async () => {
|
||||
const fileContents = Buffer.from(
|
||||
'gzip worked on the first try\n',
|
||||
defaultEncoding
|
||||
)
|
||||
const targetPath = path.join(root, 'FileA.txt')
|
||||
|
||||
setupDownloadItemResponse(fileContents, true, 200, false, false)
|
||||
const downloadHttpClient = new DownloadHttpClient()
|
||||
|
||||
const items: DownloadItem[] = []
|
||||
items.push({
|
||||
sourceLocation: `${configVariables.getRuntimeUrl()}_apis/resources/Containers/13?itemPath=my-artifact%2FFileA.txt`,
|
||||
targetPath
|
||||
})
|
||||
|
||||
await expect(
|
||||
downloadHttpClient.downloadSingleArtifact(items)
|
||||
).resolves.not.toThrow()
|
||||
|
||||
await checkDestinationFile(targetPath, fileContents)
|
||||
})
|
||||
|
||||
it('Test downloading an individual artifact without gzip', async () => {
|
||||
const fileContents = Buffer.from(
|
||||
'plaintext worked on the first try\n',
|
||||
defaultEncoding
|
||||
)
|
||||
const targetPath = path.join(root, 'FileB.txt')
|
||||
|
||||
setupDownloadItemResponse(fileContents, false, 200, false, false)
|
||||
const downloadHttpClient = new DownloadHttpClient()
|
||||
|
||||
const items: DownloadItem[] = []
|
||||
items.push({
|
||||
sourceLocation: `${configVariables.getRuntimeUrl()}_apis/resources/Containers/13?itemPath=my-artifact%2FFileB.txt`,
|
||||
targetPath
|
||||
})
|
||||
|
||||
await expect(
|
||||
downloadHttpClient.downloadSingleArtifact(items)
|
||||
).resolves.not.toThrow()
|
||||
|
||||
await checkDestinationFile(targetPath, fileContents)
|
||||
})
|
||||
|
||||
it('Test retryable status codes during artifact download', async () => {
|
||||
// The first http response should return a retryable status call while the subsequent call should return a 200 so
|
||||
// the download should successfully finish
|
||||
const retryableStatusCodes = [429, 500, 502, 503, 504]
|
||||
for (const statusCode of retryableStatusCodes) {
|
||||
const fileContents = Buffer.from('try, try again\n', defaultEncoding)
|
||||
const targetPath = path.join(root, `FileC-${statusCode}.txt`)
|
||||
|
||||
setupDownloadItemResponse(fileContents, false, statusCode, false, true)
|
||||
const downloadHttpClient = new DownloadHttpClient()
|
||||
|
||||
const items: DownloadItem[] = []
|
||||
items.push({
|
||||
sourceLocation: `${configVariables.getRuntimeUrl()}_apis/resources/Containers/13?itemPath=my-artifact%2FFileC.txt`,
|
||||
targetPath
|
||||
})
|
||||
|
||||
await expect(
|
||||
downloadHttpClient.downloadSingleArtifact(items)
|
||||
).resolves.not.toThrow()
|
||||
|
||||
await checkDestinationFile(targetPath, fileContents)
|
||||
}
|
||||
})
|
||||
|
||||
it('Test retry on truncated response with gzip', async () => {
|
||||
const fileContents = Buffer.from(
|
||||
'Sometimes gunzip fails on the first try\n',
|
||||
defaultEncoding
|
||||
)
|
||||
const targetPath = path.join(root, 'FileD.txt')
|
||||
|
||||
setupDownloadItemResponse(fileContents, true, 200, true, true)
|
||||
const downloadHttpClient = new DownloadHttpClient()
|
||||
|
||||
const items: DownloadItem[] = []
|
||||
items.push({
|
||||
sourceLocation: `${configVariables.getRuntimeUrl()}_apis/resources/Containers/13?itemPath=my-artifact%2FFileD.txt`,
|
||||
targetPath
|
||||
})
|
||||
|
||||
await expect(
|
||||
downloadHttpClient.downloadSingleArtifact(items)
|
||||
).resolves.not.toThrow()
|
||||
|
||||
await checkDestinationFile(targetPath, fileContents)
|
||||
})
|
||||
|
||||
it('Test retry on truncated response without gzip', async () => {
|
||||
const fileContents = Buffer.from(
|
||||
'You have to inspect the content-length header to know if you got everything\n',
|
||||
defaultEncoding
|
||||
)
|
||||
const targetPath = path.join(root, 'FileE.txt')
|
||||
|
||||
setupDownloadItemResponse(fileContents, false, 200, true, true)
|
||||
const downloadHttpClient = new DownloadHttpClient()
|
||||
|
||||
const items: DownloadItem[] = []
|
||||
items.push({
|
||||
sourceLocation: `${configVariables.getRuntimeUrl()}_apis/resources/Containers/13?itemPath=my-artifact%2FFileD.txt`,
|
||||
targetPath
|
||||
})
|
||||
|
||||
await expect(
|
||||
downloadHttpClient.downloadSingleArtifact(items)
|
||||
).resolves.not.toThrow()
|
||||
|
||||
await checkDestinationFile(targetPath, fileContents)
|
||||
})
|
||||
|
||||
/**
|
||||
* Helper used to setup mocking for the HttpClient
|
||||
*/
|
||||
async function emptyMockReadBody(): Promise<string> {
|
||||
return new Promise(resolve => {
|
||||
resolve()
|
||||
})
|
||||
}
|
||||
|
||||
/**
|
||||
* Setups up HTTP GET response for a successful listArtifacts() call
|
||||
*/
|
||||
function setupSuccessfulListArtifactsResponse(): void {
|
||||
jest.spyOn(HttpClient.prototype, 'get').mockImplementationOnce(async () => {
|
||||
const mockMessage = new http.IncomingMessage(new net.Socket())
|
||||
let mockReadBody = emptyMockReadBody
|
||||
|
||||
mockMessage.statusCode = 201
|
||||
const response: ListArtifactsResponse = {
|
||||
count: 2,
|
||||
value: [
|
||||
{
|
||||
containerId: '13',
|
||||
size: -1,
|
||||
signedContent: 'false',
|
||||
fileContainerResourceUrl: `${configVariables.getRuntimeUrl()}_apis/resources/Containers/13`,
|
||||
type: 'actions_storage',
|
||||
name: 'artifact1-name',
|
||||
url: `${configVariables.getRuntimeUrl()}_apis/pipelines/1/runs/1/artifacts?artifactName=artifact1-name`
|
||||
},
|
||||
{
|
||||
containerId: '13',
|
||||
size: -1,
|
||||
signedContent: 'false',
|
||||
fileContainerResourceUrl: `${configVariables.getRuntimeUrl()}_apis/resources/Containers/13`,
|
||||
type: 'actions_storage',
|
||||
name: 'artifact2-name',
|
||||
url: `${configVariables.getRuntimeUrl()}_apis/pipelines/1/runs/1/artifacts?artifactName=artifact2-name`
|
||||
}
|
||||
]
|
||||
}
|
||||
const returnData: string = JSON.stringify(response, null, 2)
|
||||
mockReadBody = async function(): Promise<string> {
|
||||
return new Promise(resolve => {
|
||||
resolve(returnData)
|
||||
})
|
||||
}
|
||||
|
||||
return new Promise<HttpClientResponse>(resolve => {
|
||||
resolve({
|
||||
message: mockMessage,
|
||||
readBody: mockReadBody
|
||||
})
|
||||
})
|
||||
})
|
||||
}
|
||||
|
||||
/**
|
||||
* Setups up HTTP GET response for downloading items
|
||||
* @param isGzip is the downloaded item gzip encoded
|
||||
* @param firstHttpResponseCode the http response code that should be returned
|
||||
*/
|
||||
function setupDownloadItemResponse(
|
||||
fileContents: Buffer,
|
||||
isGzip: boolean,
|
||||
firstHttpResponseCode: number,
|
||||
truncateFirstResponse: boolean,
|
||||
retryExpected: boolean
|
||||
): void {
|
||||
const spyInstance = jest
|
||||
.spyOn(HttpClient.prototype, 'get')
|
||||
.mockImplementationOnce(async () => {
|
||||
if (firstHttpResponseCode === 200) {
|
||||
const fullResponse = await constructResponse(isGzip, fileContents)
|
||||
const actualResponse = truncateFirstResponse
|
||||
? fullResponse.subarray(0, 3)
|
||||
: fullResponse
|
||||
|
||||
return {
|
||||
message: getDownloadResponseMessage(
|
||||
firstHttpResponseCode,
|
||||
isGzip,
|
||||
fullResponse.length,
|
||||
actualResponse
|
||||
),
|
||||
readBody: emptyMockReadBody
|
||||
}
|
||||
} else {
|
||||
return {
|
||||
message: getDownloadResponseMessage(
|
||||
firstHttpResponseCode,
|
||||
false,
|
||||
0,
|
||||
null
|
||||
),
|
||||
readBody: emptyMockReadBody
|
||||
}
|
||||
}
|
||||
})
|
||||
|
||||
// set up a second mock only if we expect a retry. Otherwise this mock will affect other tests.
|
||||
if (retryExpected) {
|
||||
spyInstance.mockImplementationOnce(async () => {
|
||||
// chained response, if the HTTP GET function gets called again, return a successful response
|
||||
const fullResponse = await constructResponse(isGzip, fileContents)
|
||||
return {
|
||||
message: getDownloadResponseMessage(
|
||||
200,
|
||||
isGzip,
|
||||
fullResponse.length,
|
||||
fullResponse
|
||||
),
|
||||
readBody: emptyMockReadBody
|
||||
}
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
async function constructResponse(
|
||||
isGzip: boolean,
|
||||
plaintext: Buffer | string
|
||||
): Promise<Buffer> {
|
||||
if (isGzip) {
|
||||
return await promisify(gzip)(plaintext)
|
||||
} else if (typeof plaintext === 'string') {
|
||||
return Buffer.from(plaintext, defaultEncoding)
|
||||
} else {
|
||||
return plaintext
|
||||
}
|
||||
}
|
||||
|
||||
function getDownloadResponseMessage(
|
||||
httpResponseCode: number,
|
||||
isGzip: boolean,
|
||||
contentLength: number,
|
||||
response: Buffer | null
|
||||
): http.IncomingMessage {
|
||||
let readCallCount = 0
|
||||
const mockMessage = <http.IncomingMessage>new stream.Readable({
|
||||
read(size) {
|
||||
switch (readCallCount++) {
|
||||
case 0:
|
||||
if (!!response && response.byteLength > size) {
|
||||
throw new Error(
|
||||
`test response larger than requested size (${size})`
|
||||
)
|
||||
}
|
||||
this.push(response)
|
||||
break
|
||||
|
||||
default:
|
||||
// end the stream
|
||||
this.push(null)
|
||||
break
|
||||
}
|
||||
}
|
||||
})
|
||||
|
||||
mockMessage.statusCode = httpResponseCode
|
||||
mockMessage.headers = {
|
||||
'content-length': contentLength.toString()
|
||||
}
|
||||
|
||||
if (isGzip) {
|
||||
mockMessage.headers['content-encoding'] = 'gzip'
|
||||
}
|
||||
|
||||
return mockMessage
|
||||
}
|
||||
|
||||
/**
|
||||
* Setups up HTTP GET response when querying for container items
|
||||
*/
|
||||
function setupSuccessfulContainerItemsResponse(): void {
|
||||
jest.spyOn(HttpClient.prototype, 'get').mockImplementationOnce(async () => {
|
||||
const mockMessage = new http.IncomingMessage(new net.Socket())
|
||||
let mockReadBody = emptyMockReadBody
|
||||
|
||||
mockMessage.statusCode = 201
|
||||
const response: QueryArtifactResponse = {
|
||||
count: 2,
|
||||
value: [
|
||||
{
|
||||
containerId: 10000,
|
||||
scopeIdentifier: '00000000-0000-0000-0000-000000000000',
|
||||
path: 'artifact-name',
|
||||
itemType: 'folder',
|
||||
status: 'created',
|
||||
dateCreated: '2020-02-06T22:13:35.373Z',
|
||||
dateLastModified: '2020-02-06T22:13:35.453Z',
|
||||
createdBy: '82f0bf89-6e55-4e5a-b8b6-f75eb992578c',
|
||||
lastModifiedBy: '82f0bf89-6e55-4e5a-b8b6-f75eb992578c',
|
||||
itemLocation: `${configVariables.getRuntimeUrl()}/_apis/resources/Containers/10000?itemPath=artifact-name&metadata=True`,
|
||||
contentLocation: `${configVariables.getRuntimeUrl()}/_apis/resources/Containers/10000?itemPath=artifact-name`,
|
||||
contentId: ''
|
||||
},
|
||||
{
|
||||
containerId: 10000,
|
||||
scopeIdentifier: '00000000-0000-0000-0000-000000000000',
|
||||
path: 'artifact-name/file1.txt',
|
||||
itemType: 'file',
|
||||
status: 'created',
|
||||
dateCreated: '2020-02-06T22:13:35.373Z',
|
||||
dateLastModified: '2020-02-06T22:13:35.453Z',
|
||||
createdBy: '82f0bf89-6e55-4e5a-b8b6-f75eb992578c',
|
||||
lastModifiedBy: '82f0bf89-6e55-4e5a-b8b6-f75eb992578c',
|
||||
itemLocation: `${configVariables.getRuntimeUrl()}/_apis/resources/Containers/10000?itemPath=artifact-name%2Ffile1.txt&metadata=True`,
|
||||
contentLocation: `${configVariables.getRuntimeUrl()}/_apis/resources/Containers/10000?itemPath=artifact-name%2Ffile1.txt`,
|
||||
contentId: ''
|
||||
}
|
||||
]
|
||||
}
|
||||
const returnData: string = JSON.stringify(response, null, 2)
|
||||
mockReadBody = async function(): Promise<string> {
|
||||
return new Promise(resolve => {
|
||||
resolve(returnData)
|
||||
})
|
||||
}
|
||||
|
||||
return new Promise<HttpClientResponse>(resolve => {
|
||||
resolve({
|
||||
message: mockMessage,
|
||||
readBody: mockReadBody
|
||||
})
|
||||
})
|
||||
})
|
||||
}
|
||||
|
||||
/**
|
||||
* Setups up HTTP GET response for a generic failed request
|
||||
*/
|
||||
function setupFailedResponse(): void {
|
||||
jest.spyOn(HttpClient.prototype, 'get').mockImplementationOnce(async () => {
|
||||
const mockMessage = new http.IncomingMessage(new net.Socket())
|
||||
mockMessage.statusCode = 400
|
||||
return new Promise<HttpClientResponse>(resolve => {
|
||||
resolve({
|
||||
message: mockMessage,
|
||||
readBody: emptyMockReadBody
|
||||
})
|
||||
})
|
||||
})
|
||||
}
|
||||
|
||||
async function checkDestinationFile(
|
||||
targetPath: string,
|
||||
expectedContents: Buffer
|
||||
): Promise<void> {
|
||||
const fileContents = await fs.readFile(targetPath)
|
||||
|
||||
expect(fileContents.byteLength).toEqual(expectedContents.byteLength)
|
||||
expect(fileContents.equals(expectedContents)).toBeTruthy()
|
||||
}
|
||||
})
|
||||
@@ -1,78 +0,0 @@
|
||||
import {
|
||||
checkArtifactName,
|
||||
checkArtifactFilePath
|
||||
} from '../src/internal/path-and-artifact-name-validation'
|
||||
import * as core from '@actions/core'
|
||||
|
||||
describe('Path and artifact name validation', () => {
|
||||
beforeAll(() => {
|
||||
// mock all output so that there is less noise when running tests
|
||||
jest.spyOn(console, 'log').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'debug').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'info').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'warning').mockImplementation(() => {})
|
||||
})
|
||||
|
||||
it('Check Artifact Name for any invalid characters', () => {
|
||||
const invalidNames = [
|
||||
'my\\artifact',
|
||||
'my/artifact',
|
||||
'my"artifact',
|
||||
'my:artifact',
|
||||
'my<artifact',
|
||||
'my>artifact',
|
||||
'my|artifact',
|
||||
'my*artifact',
|
||||
'my?artifact',
|
||||
''
|
||||
]
|
||||
for (const invalidName of invalidNames) {
|
||||
expect(() => {
|
||||
checkArtifactName(invalidName)
|
||||
}).toThrow()
|
||||
}
|
||||
|
||||
const validNames = [
|
||||
'my-normal-artifact',
|
||||
'myNormalArtifact',
|
||||
'm¥ñðrmålÄr†ï£å¢†'
|
||||
]
|
||||
for (const validName of validNames) {
|
||||
expect(() => {
|
||||
checkArtifactName(validName)
|
||||
}).not.toThrow()
|
||||
}
|
||||
})
|
||||
|
||||
it('Check Artifact File Path for any invalid characters', () => {
|
||||
const invalidNames = [
|
||||
'some/invalid"artifact/path',
|
||||
'some/invalid:artifact/path',
|
||||
'some/invalid<artifact/path',
|
||||
'some/invalid>artifact/path',
|
||||
'some/invalid|artifact/path',
|
||||
'some/invalid*artifact/path',
|
||||
'some/invalid?artifact/path',
|
||||
'some/invalid\rartifact/path',
|
||||
'some/invalid\nartifact/path',
|
||||
'some/invalid\r\nartifact/path',
|
||||
''
|
||||
]
|
||||
for (const invalidName of invalidNames) {
|
||||
expect(() => {
|
||||
checkArtifactFilePath(invalidName)
|
||||
}).toThrow()
|
||||
}
|
||||
|
||||
const validNames = [
|
||||
'my/perfectly-normal/artifact-path',
|
||||
'my/perfectly\\Normal/Artifact-path',
|
||||
'm¥/ñðrmål/Är†ï£å¢†'
|
||||
]
|
||||
for (const validName of validNames) {
|
||||
expect(() => {
|
||||
checkArtifactFilePath(validName)
|
||||
}).not.toThrow()
|
||||
}
|
||||
})
|
||||
})
|
||||
@@ -1,113 +0,0 @@
|
||||
import * as http from 'http'
|
||||
import * as net from 'net'
|
||||
import * as core from '@actions/core'
|
||||
import * as configVariables from '../src/internal/config-variables'
|
||||
import {retry} from '../src/internal/requestUtils'
|
||||
import {HttpClientResponse} from '@actions/http-client'
|
||||
|
||||
jest.mock('../src/internal/config-variables')
|
||||
|
||||
interface ITestResult {
|
||||
responseCode: number
|
||||
errorMessage: string | null
|
||||
}
|
||||
|
||||
async function testRetry(
|
||||
responseCodes: number[],
|
||||
expectedResult: ITestResult
|
||||
): Promise<void> {
|
||||
const reverse = responseCodes.reverse() // Reverse responses since we pop from end
|
||||
if (expectedResult.errorMessage) {
|
||||
// we expect some exception to be thrown
|
||||
expect(
|
||||
retry(
|
||||
'test',
|
||||
async () => handleResponse(reverse.pop()),
|
||||
new Map(), // extra error message for any particular http codes
|
||||
configVariables.getRetryLimit()
|
||||
)
|
||||
).rejects.toThrow(expectedResult.errorMessage)
|
||||
} else {
|
||||
// we expect a correct status code to be returned
|
||||
const actualResult = await retry(
|
||||
'test',
|
||||
async () => handleResponse(reverse.pop()),
|
||||
new Map(), // extra error message for any particular http codes
|
||||
configVariables.getRetryLimit()
|
||||
)
|
||||
expect(actualResult.message.statusCode).toEqual(expectedResult.responseCode)
|
||||
}
|
||||
}
|
||||
|
||||
async function handleResponse(
|
||||
testResponseCode: number | undefined
|
||||
): Promise<HttpClientResponse> {
|
||||
if (!testResponseCode) {
|
||||
throw new Error(
|
||||
'Test incorrectly set up. reverse.pop() was called too many times so not enough test response codes were supplied'
|
||||
)
|
||||
}
|
||||
|
||||
return setupSingleMockResponse(testResponseCode)
|
||||
}
|
||||
|
||||
beforeAll(async () => {
|
||||
// mock all output so that there is less noise when running tests
|
||||
jest.spyOn(console, 'log').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'debug').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'info').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'warning').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'error').mockImplementation(() => {})
|
||||
})
|
||||
|
||||
/**
|
||||
* Helpers used to setup mocking for the HttpClient
|
||||
*/
|
||||
async function emptyMockReadBody(): Promise<string> {
|
||||
return new Promise(resolve => {
|
||||
resolve()
|
||||
})
|
||||
}
|
||||
|
||||
async function setupSingleMockResponse(
|
||||
statusCode: number
|
||||
): Promise<HttpClientResponse> {
|
||||
const mockMessage = new http.IncomingMessage(new net.Socket())
|
||||
const mockReadBody = emptyMockReadBody
|
||||
mockMessage.statusCode = statusCode
|
||||
return new Promise<HttpClientResponse>(resolve => {
|
||||
resolve({
|
||||
message: mockMessage,
|
||||
readBody: mockReadBody
|
||||
})
|
||||
})
|
||||
}
|
||||
|
||||
test('retry works on successful response', async () => {
|
||||
await testRetry([200], {
|
||||
responseCode: 200,
|
||||
errorMessage: null
|
||||
})
|
||||
})
|
||||
|
||||
test('retry works after retryable status code', async () => {
|
||||
await testRetry([503, 200], {
|
||||
responseCode: 200,
|
||||
errorMessage: null
|
||||
})
|
||||
})
|
||||
|
||||
test('retry fails after exhausting retries', async () => {
|
||||
// __mocks__/config-variables caps the max retry count in tests to 2
|
||||
await testRetry([503, 503, 200], {
|
||||
responseCode: 200,
|
||||
errorMessage: 'test failed: Artifact service responded with 503'
|
||||
})
|
||||
})
|
||||
|
||||
test('retry fails after non-retryable status code', async () => {
|
||||
await testRetry([400, 200], {
|
||||
responseCode: 400,
|
||||
errorMessage: 'test failed: Artifact service responded with 400'
|
||||
})
|
||||
})
|
||||
@@ -1,27 +0,0 @@
|
||||
#!/bin/bash
|
||||
|
||||
path="$1"
|
||||
expectedContent="$2"
|
||||
|
||||
if [ "$path" == "" ]; then
|
||||
echo "File path not provided"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ "$expectedContent" == "" ]; then
|
||||
echo "Expected file contents not provided"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ ! -f "$path" ]; then
|
||||
echo "Expected file $path does not exist"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
actualContent=$(cat "$path")
|
||||
if [ "$expectedContent" == "_EMPTY_" ] && [ ! -s "$path" ]; then
|
||||
exit 0
|
||||
elif [ "$actualContent" != "$expectedContent" ]; then
|
||||
echo "File contents are not correct, expected $expectedContent, received $actualContent"
|
||||
exit 1
|
||||
fi
|
||||
@@ -1,154 +0,0 @@
|
||||
import * as core from '@actions/core'
|
||||
import * as tmp from 'tmp-promise'
|
||||
import * as path from 'path'
|
||||
import * as io from '../../io/src/io'
|
||||
import {promises as fs} from 'fs'
|
||||
import {createGZipFileOnDisk} from '../src/internal/upload-gzip'
|
||||
|
||||
const root = path.join(__dirname, '_temp', 'upload-gzip')
|
||||
const tempGzFilePath = path.join(root, 'file.gz')
|
||||
const tempGzipFilePath = path.join(root, 'file.gzip')
|
||||
const tempTgzFilePath = path.join(root, 'file.tgz')
|
||||
const tempTazFilePath = path.join(root, 'file.taz')
|
||||
const tempZFilePath = path.join(root, 'file.Z')
|
||||
const tempTaZFilePath = path.join(root, 'file.taZ')
|
||||
const tempBz2FilePath = path.join(root, 'file.bz2')
|
||||
const tempTbzFilePath = path.join(root, 'file.tbz')
|
||||
const tempTbz2FilePath = path.join(root, 'file.tbz2')
|
||||
const tempTz2FilePath = path.join(root, 'file.tz2')
|
||||
const tempLzFilePath = path.join(root, 'file.lz')
|
||||
const tempLzmaFilePath = path.join(root, 'file.lzma')
|
||||
const tempTlzFilePath = path.join(root, 'file.tlz')
|
||||
const tempLzoFilePath = path.join(root, 'file.lzo')
|
||||
const tempXzFilePath = path.join(root, 'file.xz')
|
||||
const tempTxzFilePath = path.join(root, 'file.txz')
|
||||
const tempZstFilePath = path.join(root, 'file.zst')
|
||||
const tempZstdFilePath = path.join(root, 'file.zstd')
|
||||
const tempTzstFilePath = path.join(root, 'file.tzst')
|
||||
const tempZipFilePath = path.join(root, 'file.zip')
|
||||
const temp7zFilePath = path.join(root, 'file.7z')
|
||||
const tempNormalFilePath = path.join(root, 'file.txt')
|
||||
|
||||
jest.mock('../src/internal/config-variables')
|
||||
|
||||
beforeAll(async () => {
|
||||
// mock all output so that there is less noise when running tests
|
||||
jest.spyOn(console, 'log').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'debug').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'info').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'warning').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'error').mockImplementation(() => {})
|
||||
|
||||
// clear temp directory and create files that will be "uploaded"
|
||||
await io.rmRF(root)
|
||||
await fs.mkdir(path.join(root))
|
||||
await fs.writeFile(tempGzFilePath, 'a file with a .gz file extension')
|
||||
await fs.writeFile(tempGzipFilePath, 'a file with a .gzip file extension')
|
||||
await fs.writeFile(tempTgzFilePath, 'a file with a .tgz file extension')
|
||||
await fs.writeFile(tempTazFilePath, 'a file with a .taz file extension')
|
||||
await fs.writeFile(tempZFilePath, 'a file with a .Z file extension')
|
||||
await fs.writeFile(tempTaZFilePath, 'a file with a .taZ file extension')
|
||||
await fs.writeFile(tempBz2FilePath, 'a file with a .bz2 file extension')
|
||||
await fs.writeFile(tempTbzFilePath, 'a file with a .tbz file extension')
|
||||
await fs.writeFile(tempTbz2FilePath, 'a file with a .tbz2 file extension')
|
||||
await fs.writeFile(tempTz2FilePath, 'a file with a .tz2 file extension')
|
||||
await fs.writeFile(tempLzFilePath, 'a file with a .lz file extension')
|
||||
await fs.writeFile(tempLzmaFilePath, 'a file with a .lzma file extension')
|
||||
await fs.writeFile(tempTlzFilePath, 'a file with a .tlz file extension')
|
||||
await fs.writeFile(tempLzoFilePath, 'a file with a .lzo file extension')
|
||||
await fs.writeFile(tempXzFilePath, 'a file with a .xz file extension')
|
||||
await fs.writeFile(tempTxzFilePath, 'a file with a .txz file extension')
|
||||
await fs.writeFile(tempZstFilePath, 'a file with a .zst file extension')
|
||||
await fs.writeFile(tempZstdFilePath, 'a file with a .zstd file extension')
|
||||
await fs.writeFile(tempTzstFilePath, 'a file with a .tzst file extension')
|
||||
await fs.writeFile(tempZipFilePath, 'a file with a .zip file extension')
|
||||
await fs.writeFile(temp7zFilePath, 'a file with a .7z file extension')
|
||||
await fs.writeFile(tempNormalFilePath, 'a file with a .txt file extension')
|
||||
})
|
||||
|
||||
test('Number.MAX_SAFE_INTEGER is returned when an existing compressed file is used', async () => {
|
||||
// create temporary file
|
||||
const tempFile = await tmp.file()
|
||||
|
||||
expect(await createGZipFileOnDisk(tempGzFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempGzipFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempTgzFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempTazFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempZFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempTaZFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempBz2FilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempTbzFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempTbz2FilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempTz2FilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempLzFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempLzmaFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempTlzFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempLzoFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempXzFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempTxzFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempZstFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempZstdFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempTzstFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(tempZipFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(await createGZipFileOnDisk(temp7zFilePath, tempFile.path)).toEqual(
|
||||
Number.MAX_SAFE_INTEGER
|
||||
)
|
||||
expect(
|
||||
await createGZipFileOnDisk(tempNormalFilePath, tempFile.path)
|
||||
).not.toEqual(Number.MAX_SAFE_INTEGER)
|
||||
})
|
||||
|
||||
test('gzip file on disk gets successfully created', async () => {
|
||||
// create temporary file
|
||||
const tempFile = await tmp.file()
|
||||
|
||||
const gzipFileSize = await createGZipFileOnDisk(
|
||||
tempNormalFilePath,
|
||||
tempFile.path
|
||||
)
|
||||
const fileStat = await fs.stat(tempNormalFilePath)
|
||||
const totalFileSize = fileStat.size
|
||||
|
||||
// original file and gzip file should not be equal in size
|
||||
expect(gzipFileSize).not.toEqual(totalFileSize)
|
||||
})
|
||||
@@ -1,353 +0,0 @@
|
||||
import * as io from '../../io/src/io'
|
||||
import * as path from 'path'
|
||||
import {promises as fs} from 'fs'
|
||||
import * as core from '@actions/core'
|
||||
import {getUploadSpecification} from '../src/internal/upload-specification'
|
||||
|
||||
const artifactName = 'my-artifact'
|
||||
const root = path.join(__dirname, '_temp', 'upload-specification')
|
||||
const goodItem1Path = path.join(
|
||||
root,
|
||||
'folder-a',
|
||||
'folder-b',
|
||||
'folder-c',
|
||||
'good-item1.txt'
|
||||
)
|
||||
const goodItem2Path = path.join(root, 'folder-d', 'good-item2.txt')
|
||||
const goodItem3Path = path.join(root, 'folder-d', 'good-item3.txt')
|
||||
const goodItem4Path = path.join(root, 'folder-d', 'good-item4.txt')
|
||||
const goodItem5Path = path.join(root, 'good-item5.txt')
|
||||
const badItem1Path = path.join(
|
||||
root,
|
||||
'folder-a',
|
||||
'folder-b',
|
||||
'folder-c',
|
||||
'bad-item1.txt'
|
||||
)
|
||||
const badItem2Path = path.join(root, 'folder-d', 'bad-item2.txt')
|
||||
const badItem3Path = path.join(root, 'folder-f', 'bad-item3.txt')
|
||||
const badItem4Path = path.join(root, 'folder-h', 'folder-i', 'bad-item4.txt')
|
||||
const badItem5Path = path.join(root, 'folder-h', 'folder-i', 'bad-item5.txt')
|
||||
const extraFileInFolderCPath = path.join(
|
||||
root,
|
||||
'folder-a',
|
||||
'folder-b',
|
||||
'folder-c',
|
||||
'extra-file-in-folder-c.txt'
|
||||
)
|
||||
const amazingFileInFolderHPath = path.join(root, 'folder-h', 'amazing-item.txt')
|
||||
|
||||
const artifactFilesToUpload = [
|
||||
goodItem1Path,
|
||||
goodItem2Path,
|
||||
goodItem3Path,
|
||||
goodItem4Path,
|
||||
goodItem5Path,
|
||||
extraFileInFolderCPath,
|
||||
amazingFileInFolderHPath
|
||||
]
|
||||
|
||||
describe('Search', () => {
|
||||
beforeAll(async () => {
|
||||
// mock all output so that there is less noise when running tests
|
||||
jest.spyOn(console, 'log').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'debug').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'info').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'warning').mockImplementation(() => {})
|
||||
|
||||
// clear temp directory
|
||||
await io.rmRF(root)
|
||||
await fs.mkdir(path.join(root, 'folder-a', 'folder-b', 'folder-c'), {
|
||||
recursive: true
|
||||
})
|
||||
await fs.mkdir(path.join(root, 'folder-a', 'folder-b', 'folder-e'), {
|
||||
recursive: true
|
||||
})
|
||||
await fs.mkdir(path.join(root, 'folder-d'), {
|
||||
recursive: true
|
||||
})
|
||||
await fs.mkdir(path.join(root, 'folder-f'), {
|
||||
recursive: true
|
||||
})
|
||||
await fs.mkdir(path.join(root, 'folder-g'), {
|
||||
recursive: true
|
||||
})
|
||||
await fs.mkdir(path.join(root, 'folder-h', 'folder-i'), {
|
||||
recursive: true
|
||||
})
|
||||
|
||||
await fs.writeFile(goodItem1Path, 'good item1 file')
|
||||
await fs.writeFile(goodItem2Path, 'good item2 file')
|
||||
await fs.writeFile(goodItem3Path, 'good item3 file')
|
||||
await fs.writeFile(goodItem4Path, 'good item4 file')
|
||||
await fs.writeFile(goodItem5Path, 'good item5 file')
|
||||
|
||||
await fs.writeFile(badItem1Path, 'bad item1 file')
|
||||
await fs.writeFile(badItem2Path, 'bad item2 file')
|
||||
await fs.writeFile(badItem3Path, 'bad item3 file')
|
||||
await fs.writeFile(badItem4Path, 'bad item4 file')
|
||||
await fs.writeFile(badItem5Path, 'bad item5 file')
|
||||
|
||||
await fs.writeFile(extraFileInFolderCPath, 'extra file')
|
||||
|
||||
await fs.writeFile(amazingFileInFolderHPath, 'amazing file')
|
||||
/*
|
||||
Directory structure of files that get created:
|
||||
root/
|
||||
folder-a/
|
||||
folder-b/
|
||||
folder-c/
|
||||
good-item1.txt
|
||||
bad-item1.txt
|
||||
extra-file-in-folder-c.txt
|
||||
folder-e/
|
||||
folder-d/
|
||||
good-item2.txt
|
||||
good-item3.txt
|
||||
good-item4.txt
|
||||
bad-item2.txt
|
||||
folder-f/
|
||||
bad-item3.txt
|
||||
folder-g/
|
||||
folder-h/
|
||||
amazing-item.txt
|
||||
folder-i/
|
||||
bad-item4.txt
|
||||
bad-item5.txt
|
||||
good-item5.txt
|
||||
*/
|
||||
})
|
||||
|
||||
it('Upload Specification - Fail non-existent rootDirectory', async () => {
|
||||
const invalidRootDirectory = path.join(
|
||||
__dirname,
|
||||
'_temp',
|
||||
'upload-specification-invalid'
|
||||
)
|
||||
expect(() => {
|
||||
getUploadSpecification(
|
||||
artifactName,
|
||||
invalidRootDirectory,
|
||||
artifactFilesToUpload
|
||||
)
|
||||
}).toThrow(`Provided rootDirectory ${invalidRootDirectory} does not exist`)
|
||||
})
|
||||
|
||||
it('Upload Specification - Fail invalid rootDirectory', async () => {
|
||||
expect(() => {
|
||||
getUploadSpecification(artifactName, goodItem1Path, artifactFilesToUpload)
|
||||
}).toThrow(
|
||||
`Provided rootDirectory ${goodItem1Path} is not a valid directory`
|
||||
)
|
||||
})
|
||||
|
||||
it('Upload Specification - File does not exist', async () => {
|
||||
const fakeFilePath = path.join(
|
||||
artifactName,
|
||||
'folder-a',
|
||||
'folder-b',
|
||||
'non-existent-file.txt'
|
||||
)
|
||||
expect(() => {
|
||||
getUploadSpecification(artifactName, root, [fakeFilePath])
|
||||
}).toThrow(`File ${fakeFilePath} does not exist`)
|
||||
})
|
||||
|
||||
it('Upload Specification - Non parent directory', async () => {
|
||||
const folderADirectory = path.join(root, 'folder-a')
|
||||
const artifactFiles = [
|
||||
goodItem1Path,
|
||||
badItem1Path,
|
||||
extraFileInFolderCPath,
|
||||
goodItem5Path
|
||||
]
|
||||
expect(() => {
|
||||
getUploadSpecification(artifactName, folderADirectory, artifactFiles)
|
||||
}).toThrow(
|
||||
`The rootDirectory: ${folderADirectory} is not a parent directory of the file: ${goodItem5Path}`
|
||||
)
|
||||
})
|
||||
|
||||
it('Upload Specification - Success', async () => {
|
||||
const specifications = getUploadSpecification(
|
||||
artifactName,
|
||||
root,
|
||||
artifactFilesToUpload
|
||||
)
|
||||
expect(specifications.length).toEqual(7)
|
||||
|
||||
const absolutePaths = specifications.map(item => item.absoluteFilePath)
|
||||
expect(absolutePaths).toContain(goodItem1Path)
|
||||
expect(absolutePaths).toContain(goodItem2Path)
|
||||
expect(absolutePaths).toContain(goodItem3Path)
|
||||
expect(absolutePaths).toContain(goodItem4Path)
|
||||
expect(absolutePaths).toContain(goodItem5Path)
|
||||
expect(absolutePaths).toContain(extraFileInFolderCPath)
|
||||
expect(absolutePaths).toContain(amazingFileInFolderHPath)
|
||||
|
||||
for (const specification of specifications) {
|
||||
if (specification.absoluteFilePath === goodItem1Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(
|
||||
artifactName,
|
||||
'folder-a',
|
||||
'folder-b',
|
||||
'folder-c',
|
||||
'good-item1.txt'
|
||||
)
|
||||
)
|
||||
} else if (specification.absoluteFilePath === goodItem2Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'folder-d', 'good-item2.txt')
|
||||
)
|
||||
} else if (specification.absoluteFilePath === goodItem3Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'folder-d', 'good-item3.txt')
|
||||
)
|
||||
} else if (specification.absoluteFilePath === goodItem4Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'folder-d', 'good-item4.txt')
|
||||
)
|
||||
} else if (specification.absoluteFilePath === goodItem5Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'good-item5.txt')
|
||||
)
|
||||
} else if (specification.absoluteFilePath === extraFileInFolderCPath) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(
|
||||
artifactName,
|
||||
'folder-a',
|
||||
'folder-b',
|
||||
'folder-c',
|
||||
'extra-file-in-folder-c.txt'
|
||||
)
|
||||
)
|
||||
} else if (specification.absoluteFilePath === amazingFileInFolderHPath) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'folder-h', 'amazing-item.txt')
|
||||
)
|
||||
} else {
|
||||
throw new Error(
|
||||
'Invalid specification found. This should never be reached'
|
||||
)
|
||||
}
|
||||
}
|
||||
})
|
||||
|
||||
it('Upload Specification - Success with extra slash', async () => {
|
||||
const rootWithSlash = `${root}/`
|
||||
const specifications = getUploadSpecification(
|
||||
artifactName,
|
||||
rootWithSlash,
|
||||
artifactFilesToUpload
|
||||
)
|
||||
expect(specifications.length).toEqual(7)
|
||||
|
||||
const absolutePaths = specifications.map(item => item.absoluteFilePath)
|
||||
expect(absolutePaths).toContain(goodItem1Path)
|
||||
expect(absolutePaths).toContain(goodItem2Path)
|
||||
expect(absolutePaths).toContain(goodItem3Path)
|
||||
expect(absolutePaths).toContain(goodItem4Path)
|
||||
expect(absolutePaths).toContain(goodItem5Path)
|
||||
expect(absolutePaths).toContain(extraFileInFolderCPath)
|
||||
expect(absolutePaths).toContain(amazingFileInFolderHPath)
|
||||
|
||||
for (const specification of specifications) {
|
||||
if (specification.absoluteFilePath === goodItem1Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(
|
||||
artifactName,
|
||||
'folder-a',
|
||||
'folder-b',
|
||||
'folder-c',
|
||||
'good-item1.txt'
|
||||
)
|
||||
)
|
||||
} else if (specification.absoluteFilePath === goodItem2Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'folder-d', 'good-item2.txt')
|
||||
)
|
||||
} else if (specification.absoluteFilePath === goodItem3Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'folder-d', 'good-item3.txt')
|
||||
)
|
||||
} else if (specification.absoluteFilePath === goodItem4Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'folder-d', 'good-item4.txt')
|
||||
)
|
||||
} else if (specification.absoluteFilePath === goodItem5Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'good-item5.txt')
|
||||
)
|
||||
} else if (specification.absoluteFilePath === extraFileInFolderCPath) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(
|
||||
artifactName,
|
||||
'folder-a',
|
||||
'folder-b',
|
||||
'folder-c',
|
||||
'extra-file-in-folder-c.txt'
|
||||
)
|
||||
)
|
||||
} else if (specification.absoluteFilePath === amazingFileInFolderHPath) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'folder-h', 'amazing-item.txt')
|
||||
)
|
||||
} else {
|
||||
throw new Error(
|
||||
'Invalid specification found. This should never be reached'
|
||||
)
|
||||
}
|
||||
}
|
||||
})
|
||||
|
||||
it('Upload Specification - Directories should not be included', async () => {
|
||||
const folderEPath = path.join(root, 'folder-a', 'folder-b', 'folder-e')
|
||||
const filesWithDirectory = [
|
||||
goodItem1Path,
|
||||
goodItem4Path,
|
||||
folderEPath,
|
||||
badItem3Path
|
||||
]
|
||||
const specifications = getUploadSpecification(
|
||||
artifactName,
|
||||
root,
|
||||
filesWithDirectory
|
||||
)
|
||||
expect(specifications.length).toEqual(3)
|
||||
const absolutePaths = specifications.map(item => item.absoluteFilePath)
|
||||
expect(absolutePaths).toContain(goodItem1Path)
|
||||
expect(absolutePaths).toContain(goodItem4Path)
|
||||
expect(absolutePaths).toContain(badItem3Path)
|
||||
|
||||
for (const specification of specifications) {
|
||||
if (specification.absoluteFilePath === goodItem1Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(
|
||||
artifactName,
|
||||
'folder-a',
|
||||
'folder-b',
|
||||
'folder-c',
|
||||
'good-item1.txt'
|
||||
)
|
||||
)
|
||||
} else if (specification.absoluteFilePath === goodItem2Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'folder-d', 'good-item2.txt')
|
||||
)
|
||||
} else if (specification.absoluteFilePath === goodItem4Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'folder-d', 'good-item4.txt')
|
||||
)
|
||||
} else if (specification.absoluteFilePath === badItem3Path) {
|
||||
expect(specification.uploadFilePath).toEqual(
|
||||
path.join(artifactName, 'folder-f', 'bad-item3.txt')
|
||||
)
|
||||
} else {
|
||||
throw new Error(
|
||||
'Invalid specification found. This should never be reached'
|
||||
)
|
||||
}
|
||||
}
|
||||
})
|
||||
})
|
||||
@@ -1,551 +0,0 @@
|
||||
import * as http from 'http'
|
||||
import * as io from '../../io/src/io'
|
||||
import * as net from 'net'
|
||||
import * as path from 'path'
|
||||
import {mocked} from 'ts-jest/utils'
|
||||
import {exec, execSync} from 'child_process'
|
||||
import {createGunzip} from 'zlib'
|
||||
import {promisify} from 'util'
|
||||
import {UploadHttpClient} from '../src/internal/upload-http-client'
|
||||
import * as core from '@actions/core'
|
||||
import {promises as fs} from 'fs'
|
||||
import {getRuntimeUrl} from '../src/internal/config-variables'
|
||||
import {HttpClient, HttpClientResponse} from '@actions/http-client'
|
||||
import {
|
||||
ArtifactResponse,
|
||||
PatchArtifactSizeSuccessResponse
|
||||
} from '../src/internal/contracts'
|
||||
import {UploadSpecification} from '../src/internal/upload-specification'
|
||||
import {getArtifactUrl} from '../src/internal/utils'
|
||||
import {UploadOptions} from '../src/internal/upload-options'
|
||||
|
||||
const root = path.join(__dirname, '_temp', 'artifact-upload')
|
||||
const file1Path = path.join(root, 'file1.txt')
|
||||
const file2Path = path.join(root, 'file2.txt')
|
||||
const file3Path = path.join(root, 'folder1', 'file3.txt')
|
||||
const file4Path = path.join(root, 'folder1', 'file4.txt')
|
||||
const file5Path = path.join(root, 'folder1', 'folder2', 'folder3', 'file5.txt')
|
||||
|
||||
let file1Size = 0
|
||||
let file2Size = 0
|
||||
let file3Size = 0
|
||||
let file4Size = 0
|
||||
let file5Size = 0
|
||||
|
||||
jest.mock('../src/internal/config-variables')
|
||||
jest.mock('@actions/http-client')
|
||||
|
||||
describe('Upload Tests', () => {
|
||||
beforeAll(async () => {
|
||||
// mock all output so that there is less noise when running tests
|
||||
jest.spyOn(console, 'log').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'debug').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'info').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'warning').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'error').mockImplementation(() => {})
|
||||
|
||||
// setup mocking for calls that got through the HttpClient
|
||||
setupHttpClientMock()
|
||||
|
||||
// clear temp directory and create files that will be "uploaded"
|
||||
await io.rmRF(root)
|
||||
await fs.mkdir(path.join(root, 'folder1', 'folder2', 'folder3'), {
|
||||
recursive: true
|
||||
})
|
||||
await fs.writeFile(file1Path, 'this is file 1')
|
||||
await fs.writeFile(file2Path, 'this is file 2')
|
||||
await fs.writeFile(file3Path, 'this is file 3')
|
||||
await fs.writeFile(file4Path, 'this is file 4')
|
||||
await fs.writeFile(file5Path, 'this is file 5')
|
||||
/*
|
||||
Directory structure for files that get created:
|
||||
root/
|
||||
file1.txt
|
||||
file2.txt
|
||||
folder1/
|
||||
file3.txt
|
||||
file4.txt
|
||||
folder2/
|
||||
folder3/
|
||||
file5.txt
|
||||
*/
|
||||
|
||||
file1Size = (await fs.stat(file1Path)).size
|
||||
file2Size = (await fs.stat(file2Path)).size
|
||||
file3Size = (await fs.stat(file3Path)).size
|
||||
file4Size = (await fs.stat(file4Path)).size
|
||||
file5Size = (await fs.stat(file5Path)).size
|
||||
})
|
||||
|
||||
/**
|
||||
* Artifact Creation Tests
|
||||
*/
|
||||
it('Create Artifact - Success', async () => {
|
||||
const artifactName = 'valid-artifact-name'
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
const response = await uploadHttpClient.createArtifactInFileContainer(
|
||||
artifactName
|
||||
)
|
||||
expect(response.containerId).toEqual('13')
|
||||
expect(response.size).toEqual(-1)
|
||||
expect(response.signedContent).toEqual('false')
|
||||
expect(response.fileContainerResourceUrl).toEqual(
|
||||
`${getRuntimeUrl()}_apis/resources/Containers/13`
|
||||
)
|
||||
expect(response.type).toEqual('actions_storage')
|
||||
expect(response.name).toEqual(artifactName)
|
||||
expect(response.url).toEqual(
|
||||
`${getRuntimeUrl()}_apis/pipelines/1/runs/1/artifacts?artifactName=${artifactName}`
|
||||
)
|
||||
})
|
||||
|
||||
it('Create Artifact - Failure', async () => {
|
||||
const artifactName = 'invalid-artifact-name'
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
expect(
|
||||
uploadHttpClient.createArtifactInFileContainer(artifactName)
|
||||
).rejects.toEqual(
|
||||
new Error(
|
||||
`Create Artifact Container failed: The artifact name invalid-artifact-name is not valid. Request URL ${getArtifactUrl()}`
|
||||
)
|
||||
)
|
||||
})
|
||||
|
||||
it('Create Artifact - Retention Less Than Min Value Error', async () => {
|
||||
const artifactName = 'valid-artifact-name'
|
||||
const options: UploadOptions = {
|
||||
retentionDays: -1
|
||||
}
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
expect(
|
||||
uploadHttpClient.createArtifactInFileContainer(artifactName, options)
|
||||
).rejects.toEqual(new Error('Invalid retention, minimum value is 1.'))
|
||||
})
|
||||
|
||||
it('Create Artifact - Storage Quota Error', async () => {
|
||||
const artifactName = 'storage-quota-hit'
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
expect(
|
||||
uploadHttpClient.createArtifactInFileContainer(artifactName)
|
||||
).rejects.toEqual(
|
||||
new Error(
|
||||
'Create Artifact Container failed: Artifact storage quota has been hit. Unable to upload any new artifacts'
|
||||
)
|
||||
)
|
||||
})
|
||||
|
||||
/**
|
||||
* Artifact Upload Tests
|
||||
*/
|
||||
it('Upload Artifact - Success', async () => {
|
||||
/**
|
||||
* Normally search.findFilesToUpload() would be used for providing information about what to upload. These tests however
|
||||
* focuses solely on the upload APIs so searchResult[] will be hard-coded
|
||||
*/
|
||||
const artifactName = 'successful-artifact'
|
||||
const uploadSpecification: UploadSpecification[] = [
|
||||
{
|
||||
absoluteFilePath: file1Path,
|
||||
uploadFilePath: `${artifactName}/file1.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file2Path,
|
||||
uploadFilePath: `${artifactName}/file2.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file3Path,
|
||||
uploadFilePath: `${artifactName}/folder1/file3.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file4Path,
|
||||
uploadFilePath: `${artifactName}/folder1/file4.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file5Path,
|
||||
uploadFilePath: `${artifactName}/folder1/folder2/folder3/file5.txt`
|
||||
}
|
||||
]
|
||||
|
||||
const expectedTotalSize =
|
||||
file1Size + file2Size + file3Size + file4Size + file5Size
|
||||
const uploadUrl = `${getRuntimeUrl()}_apis/resources/Containers/13`
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
const uploadResult = await uploadHttpClient.uploadArtifactToFileContainer(
|
||||
uploadUrl,
|
||||
uploadSpecification
|
||||
)
|
||||
expect(uploadResult.failedItems.length).toEqual(0)
|
||||
expect(uploadResult.uploadSize).toEqual(expectedTotalSize)
|
||||
})
|
||||
|
||||
function hasMkfifo(): boolean {
|
||||
try {
|
||||
// make sure we drain the stdout
|
||||
return (
|
||||
process.platform !== 'win32' &&
|
||||
execSync('which mkfifo').toString().length > 0
|
||||
)
|
||||
} catch (e) {
|
||||
return false
|
||||
}
|
||||
}
|
||||
const withMkfifoIt = hasMkfifo() ? it : it.skip
|
||||
withMkfifoIt(
|
||||
'Upload Artifact with content from named pipe - Success',
|
||||
async () => {
|
||||
// create a named pipe 'pipe' with content 'hello pipe'
|
||||
const content = Buffer.from('hello pipe')
|
||||
const pipeFilePath = path.join(root, 'pipe')
|
||||
await promisify(exec)('mkfifo pipe', {cwd: root})
|
||||
// don't want to await here as that would block until read
|
||||
fs.writeFile(pipeFilePath, content)
|
||||
|
||||
const artifactName = 'successful-artifact'
|
||||
const uploadSpecification: UploadSpecification[] = [
|
||||
{
|
||||
absoluteFilePath: pipeFilePath,
|
||||
uploadFilePath: `${artifactName}/pipe`
|
||||
}
|
||||
]
|
||||
|
||||
const uploadUrl = `${getRuntimeUrl()}_apis/resources/Containers/13`
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
const uploadResult = await uploadHttpClient.uploadArtifactToFileContainer(
|
||||
uploadUrl,
|
||||
uploadSpecification
|
||||
)
|
||||
|
||||
// accesses the ReadableStream that was passed into sendStream
|
||||
// eslint-disable-next-line @typescript-eslint/unbound-method
|
||||
const stream = mocked(HttpClient.prototype.sendStream).mock.calls[0][2]
|
||||
expect(stream).not.toBeNull()
|
||||
// decompresses the passed stream
|
||||
const data: Buffer[] = []
|
||||
for await (const chunk of stream.pipe(createGunzip())) {
|
||||
data.push(Buffer.isBuffer(chunk) ? chunk : Buffer.from(chunk as string))
|
||||
}
|
||||
const uploaded = Buffer.concat(data)
|
||||
|
||||
expect(uploadResult.failedItems.length).toEqual(0)
|
||||
expect(uploaded).toEqual(content)
|
||||
}
|
||||
)
|
||||
|
||||
it('Upload Artifact - Failed Single File Upload', async () => {
|
||||
const uploadSpecification: UploadSpecification[] = [
|
||||
{
|
||||
absoluteFilePath: file1Path,
|
||||
uploadFilePath: `this-file-upload-will-fail`
|
||||
}
|
||||
]
|
||||
|
||||
const uploadUrl = `${getRuntimeUrl()}_apis/resources/Containers/13`
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
const uploadResult = await uploadHttpClient.uploadArtifactToFileContainer(
|
||||
uploadUrl,
|
||||
uploadSpecification
|
||||
)
|
||||
expect(uploadResult.failedItems.length).toEqual(1)
|
||||
expect(uploadResult.uploadSize).toEqual(0)
|
||||
})
|
||||
|
||||
it('Upload Artifact - Partial Upload Continue On Error', async () => {
|
||||
const artifactName = 'partial-artifact'
|
||||
const uploadSpecification: UploadSpecification[] = [
|
||||
{
|
||||
absoluteFilePath: file1Path,
|
||||
uploadFilePath: `${artifactName}/file1.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file2Path,
|
||||
uploadFilePath: `${artifactName}/file2.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file3Path,
|
||||
uploadFilePath: `${artifactName}/folder1/file3.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file4Path,
|
||||
uploadFilePath: `this-file-upload-will-fail`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file5Path,
|
||||
uploadFilePath: `${artifactName}/folder1/folder2/folder3/file5.txt`
|
||||
}
|
||||
]
|
||||
|
||||
const expectedPartialSize = file1Size + file2Size + file4Size + file5Size
|
||||
const uploadUrl = `${getRuntimeUrl()}_apis/resources/Containers/13`
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
const uploadResult = await uploadHttpClient.uploadArtifactToFileContainer(
|
||||
uploadUrl,
|
||||
uploadSpecification,
|
||||
{continueOnError: true}
|
||||
)
|
||||
expect(uploadResult.failedItems.length).toEqual(1)
|
||||
expect(uploadResult.uploadSize).toEqual(expectedPartialSize)
|
||||
})
|
||||
|
||||
it('Upload Artifact - Partial Upload Fail Fast', async () => {
|
||||
const artifactName = 'partial-artifact'
|
||||
const uploadSpecification: UploadSpecification[] = [
|
||||
{
|
||||
absoluteFilePath: file1Path,
|
||||
uploadFilePath: `${artifactName}/file1.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file2Path,
|
||||
uploadFilePath: `${artifactName}/file2.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file3Path,
|
||||
uploadFilePath: `${artifactName}/folder1/file3.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file4Path,
|
||||
uploadFilePath: `this-file-upload-will-fail`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file5Path,
|
||||
uploadFilePath: `${artifactName}/folder1/folder2/folder3/file5.txt`
|
||||
}
|
||||
]
|
||||
|
||||
const expectedPartialSize = file1Size + file2Size + file3Size
|
||||
const uploadUrl = `${getRuntimeUrl()}_apis/resources/Containers/13`
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
const uploadResult = await uploadHttpClient.uploadArtifactToFileContainer(
|
||||
uploadUrl,
|
||||
uploadSpecification,
|
||||
{continueOnError: false}
|
||||
)
|
||||
expect(uploadResult.failedItems.length).toEqual(2)
|
||||
expect(uploadResult.uploadSize).toEqual(expectedPartialSize)
|
||||
})
|
||||
|
||||
it('Upload Artifact - Failed upload with no options', async () => {
|
||||
const artifactName = 'partial-artifact'
|
||||
const uploadSpecification: UploadSpecification[] = [
|
||||
{
|
||||
absoluteFilePath: file1Path,
|
||||
uploadFilePath: `${artifactName}/file1.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file2Path,
|
||||
uploadFilePath: `${artifactName}/file2.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file3Path,
|
||||
uploadFilePath: `${artifactName}/folder1/file3.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file4Path,
|
||||
uploadFilePath: `this-file-upload-will-fail`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file5Path,
|
||||
uploadFilePath: `${artifactName}/folder1/folder2/folder3/file5.txt`
|
||||
}
|
||||
]
|
||||
|
||||
const expectedPartialSize = file1Size + file2Size + file3Size + file5Size
|
||||
const uploadUrl = `${getRuntimeUrl()}_apis/resources/Containers/13`
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
const uploadResult = await uploadHttpClient.uploadArtifactToFileContainer(
|
||||
uploadUrl,
|
||||
uploadSpecification
|
||||
)
|
||||
expect(uploadResult.failedItems.length).toEqual(1)
|
||||
expect(uploadResult.uploadSize).toEqual(expectedPartialSize)
|
||||
})
|
||||
|
||||
it('Upload Artifact - Failed upload with empty options', async () => {
|
||||
const artifactName = 'partial-artifact'
|
||||
const uploadSpecification: UploadSpecification[] = [
|
||||
{
|
||||
absoluteFilePath: file1Path,
|
||||
uploadFilePath: `${artifactName}/file1.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file2Path,
|
||||
uploadFilePath: `${artifactName}/file2.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file3Path,
|
||||
uploadFilePath: `${artifactName}/folder1/file3.txt`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file4Path,
|
||||
uploadFilePath: `this-file-upload-will-fail`
|
||||
},
|
||||
{
|
||||
absoluteFilePath: file5Path,
|
||||
uploadFilePath: `${artifactName}/folder1/folder2/folder3/file5.txt`
|
||||
}
|
||||
]
|
||||
|
||||
const expectedPartialSize = file1Size + file2Size + file3Size + file5Size
|
||||
const uploadUrl = `${getRuntimeUrl()}_apis/resources/Containers/13`
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
const uploadResult = await uploadHttpClient.uploadArtifactToFileContainer(
|
||||
uploadUrl,
|
||||
uploadSpecification,
|
||||
{}
|
||||
)
|
||||
expect(uploadResult.failedItems.length).toEqual(1)
|
||||
expect(uploadResult.uploadSize).toEqual(expectedPartialSize)
|
||||
})
|
||||
|
||||
/**
|
||||
* Artifact Association Tests
|
||||
*/
|
||||
it('Associate Artifact - Success', async () => {
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
expect(async () => {
|
||||
uploadHttpClient.patchArtifactSize(130, 'my-artifact')
|
||||
}).not.toThrow()
|
||||
})
|
||||
|
||||
it('Associate Artifact - Not Found', async () => {
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
expect(
|
||||
uploadHttpClient.patchArtifactSize(100, 'non-existent-artifact')
|
||||
).rejects.toThrow(
|
||||
'An Artifact with the name non-existent-artifact was not found'
|
||||
)
|
||||
})
|
||||
|
||||
it('Associate Artifact - Error', async () => {
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
expect(
|
||||
uploadHttpClient.patchArtifactSize(-2, 'my-artifact')
|
||||
).rejects.toThrow(
|
||||
'Finalize artifact upload failed: Artifact service responded with 400'
|
||||
)
|
||||
})
|
||||
|
||||
/**
|
||||
* Helpers used to setup mocking for the HttpClient
|
||||
*/
|
||||
async function emptyMockReadBody(): Promise<string> {
|
||||
return new Promise(resolve => {
|
||||
resolve()
|
||||
})
|
||||
}
|
||||
|
||||
function setupHttpClientMock(): void {
|
||||
/**
|
||||
* Mocks Post calls that are used during Artifact Creation tests
|
||||
*
|
||||
* Simulates success and non-success status codes depending on the artifact name along with an appropriate
|
||||
* payload that represents an expected response
|
||||
*/
|
||||
jest
|
||||
.spyOn(HttpClient.prototype, 'post')
|
||||
.mockImplementation(async (requestdata, data) => {
|
||||
// parse the input data and use the provided artifact name as part of the response
|
||||
const inputData = JSON.parse(data)
|
||||
const mockMessage = new http.IncomingMessage(new net.Socket())
|
||||
let mockReadBody = emptyMockReadBody
|
||||
|
||||
if (inputData.Name === 'invalid-artifact-name') {
|
||||
mockMessage.statusCode = 400
|
||||
} else if (inputData.Name === 'storage-quota-hit') {
|
||||
mockMessage.statusCode = 403
|
||||
} else {
|
||||
mockMessage.statusCode = 201
|
||||
const response: ArtifactResponse = {
|
||||
containerId: '13',
|
||||
size: -1,
|
||||
signedContent: 'false',
|
||||
fileContainerResourceUrl: `${getRuntimeUrl()}_apis/resources/Containers/13`,
|
||||
type: 'actions_storage',
|
||||
name: inputData.Name,
|
||||
url: `${getRuntimeUrl()}_apis/pipelines/1/runs/1/artifacts?artifactName=${
|
||||
inputData.Name
|
||||
}`
|
||||
}
|
||||
const returnData: string = JSON.stringify(response, null, 2)
|
||||
mockReadBody = async function(): Promise<string> {
|
||||
return new Promise(resolve => {
|
||||
resolve(returnData)
|
||||
})
|
||||
}
|
||||
}
|
||||
return new Promise<HttpClientResponse>(resolve => {
|
||||
resolve({
|
||||
message: mockMessage,
|
||||
readBody: mockReadBody
|
||||
})
|
||||
})
|
||||
})
|
||||
|
||||
/**
|
||||
* Mocks SendStream calls that are made during Artifact Upload tests
|
||||
*
|
||||
* A 500 response is used to simulate a failed upload stream. The uploadUrl can be set to
|
||||
* include 'fail' to specify that the upload should fail
|
||||
*/
|
||||
jest
|
||||
.spyOn(HttpClient.prototype, 'sendStream')
|
||||
.mockImplementation(async (verb, requestUrl) => {
|
||||
const mockMessage = new http.IncomingMessage(new net.Socket())
|
||||
mockMessage.statusCode = 200
|
||||
if (requestUrl.includes('fail')) {
|
||||
mockMessage.statusCode = 500
|
||||
}
|
||||
|
||||
return new Promise<HttpClientResponse>(resolve => {
|
||||
resolve({
|
||||
message: mockMessage,
|
||||
readBody: emptyMockReadBody
|
||||
})
|
||||
})
|
||||
})
|
||||
|
||||
/**
|
||||
* Mocks Patch calls that are made during Artifact Association tests
|
||||
*
|
||||
* Simulates success and non-success status codes depending on the input size along with an appropriate
|
||||
* payload that represents an expected response
|
||||
*/
|
||||
jest
|
||||
.spyOn(HttpClient.prototype, 'patch')
|
||||
.mockImplementation(async (requestdata, data) => {
|
||||
const inputData = JSON.parse(data)
|
||||
const mockMessage = new http.IncomingMessage(new net.Socket())
|
||||
|
||||
// Get the name from the end of requestdata. Will be something like https://www.example.com/_apis/pipelines/workflows/15/artifacts?api-version=6.0-preview&artifactName=my-artifact
|
||||
const artifactName = requestdata.split('=')[2]
|
||||
let mockReadBody = emptyMockReadBody
|
||||
if (inputData.Size < 1) {
|
||||
mockMessage.statusCode = 400
|
||||
} else if (artifactName === 'non-existent-artifact') {
|
||||
mockMessage.statusCode = 404
|
||||
} else {
|
||||
mockMessage.statusCode = 200
|
||||
const response: PatchArtifactSizeSuccessResponse = {
|
||||
containerId: 13,
|
||||
size: inputData.Size,
|
||||
signedContent: 'false',
|
||||
type: 'actions_storage',
|
||||
name: artifactName,
|
||||
url: `${getRuntimeUrl()}_apis/pipelines/1/runs/1/artifacts?artifactName=${artifactName}`,
|
||||
uploadUrl: `${getRuntimeUrl()}_apis/resources/Containers/13`
|
||||
}
|
||||
const returnData: string = JSON.stringify(response, null, 2)
|
||||
mockReadBody = async function(): Promise<string> {
|
||||
return new Promise(resolve => {
|
||||
resolve(returnData)
|
||||
})
|
||||
}
|
||||
}
|
||||
return new Promise<HttpClientResponse>(resolve => {
|
||||
resolve({
|
||||
message: mockMessage,
|
||||
readBody: mockReadBody
|
||||
})
|
||||
})
|
||||
})
|
||||
}
|
||||
})
|
||||
@@ -1,239 +0,0 @@
|
||||
import * as fs from 'fs'
|
||||
import * as io from '../../io/src/io'
|
||||
import * as path from 'path'
|
||||
import * as utils from '../src/internal/utils'
|
||||
import * as core from '@actions/core'
|
||||
import {HttpCodes} from '@actions/http-client'
|
||||
import {
|
||||
getRuntimeUrl,
|
||||
getWorkFlowRunId,
|
||||
getInitialRetryIntervalInMilliseconds,
|
||||
getRetryMultiplier
|
||||
} from '../src/internal/config-variables'
|
||||
import {Readable} from 'stream'
|
||||
|
||||
jest.mock('../src/internal/config-variables')
|
||||
|
||||
describe('Utils', () => {
|
||||
beforeAll(() => {
|
||||
// mock all output so that there is less noise when running tests
|
||||
jest.spyOn(console, 'log').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'debug').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'info').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'warning').mockImplementation(() => {})
|
||||
})
|
||||
|
||||
it('Check exponential retry range', () => {
|
||||
// No retries should return the initial retry interval
|
||||
const retryWaitTime0 = utils.getExponentialRetryTimeInMilliseconds(0)
|
||||
expect(retryWaitTime0).toEqual(getInitialRetryIntervalInMilliseconds())
|
||||
|
||||
const testMinMaxRange = (retryCount: number): void => {
|
||||
const retryWaitTime = utils.getExponentialRetryTimeInMilliseconds(
|
||||
retryCount
|
||||
)
|
||||
const minRange =
|
||||
getInitialRetryIntervalInMilliseconds() *
|
||||
getRetryMultiplier() *
|
||||
retryCount
|
||||
const maxRange = minRange * getRetryMultiplier()
|
||||
|
||||
expect(retryWaitTime).toBeGreaterThanOrEqual(minRange)
|
||||
expect(retryWaitTime).toBeLessThan(maxRange)
|
||||
}
|
||||
|
||||
for (let i = 1; i < 10; i++) {
|
||||
testMinMaxRange(i)
|
||||
}
|
||||
})
|
||||
|
||||
it('Test negative artifact retention throws', () => {
|
||||
expect(() => {
|
||||
utils.getProperRetention(-1, undefined)
|
||||
}).toThrow()
|
||||
})
|
||||
|
||||
it('Test no setting specified takes artifact retention input', () => {
|
||||
expect(utils.getProperRetention(180, undefined)).toEqual(180)
|
||||
})
|
||||
|
||||
it('Test artifact retention must conform to max allowed', () => {
|
||||
expect(utils.getProperRetention(180, '45')).toEqual(45)
|
||||
})
|
||||
|
||||
it('Test constructing artifact URL', () => {
|
||||
const runtimeUrl = getRuntimeUrl()
|
||||
const runId = getWorkFlowRunId()
|
||||
const artifactUrl = utils.getArtifactUrl()
|
||||
expect(artifactUrl).toEqual(
|
||||
`${runtimeUrl}_apis/pipelines/workflows/${runId}/artifacts?api-version=${utils.getApiVersion()}`
|
||||
)
|
||||
})
|
||||
|
||||
it('Test constructing upload headers with all optional parameters', () => {
|
||||
const contentType = 'application/octet-stream'
|
||||
const size = 24
|
||||
const uncompressedLength = 100
|
||||
const range = 'bytes 0-199/200'
|
||||
const digest = {
|
||||
crc64: 'bSzITYnW/P8=',
|
||||
md5: 'Xiv1fT9AxLbfadrxk2y3ZvgyN0tPwCWafL/wbi9w8mk='
|
||||
}
|
||||
const headers = utils.getUploadHeaders(
|
||||
contentType,
|
||||
true,
|
||||
true,
|
||||
uncompressedLength,
|
||||
size,
|
||||
range,
|
||||
digest
|
||||
)
|
||||
expect(Object.keys(headers).length).toEqual(10)
|
||||
expect(headers['Accept']).toEqual(
|
||||
`application/json;api-version=${utils.getApiVersion()}`
|
||||
)
|
||||
expect(headers['Content-Type']).toEqual(contentType)
|
||||
expect(headers['Connection']).toEqual('Keep-Alive')
|
||||
expect(headers['Keep-Alive']).toEqual('10')
|
||||
expect(headers['Content-Encoding']).toEqual('gzip')
|
||||
expect(headers['x-tfs-filelength']).toEqual(uncompressedLength)
|
||||
expect(headers['Content-Length']).toEqual(size)
|
||||
expect(headers['Content-Range']).toEqual(range)
|
||||
expect(headers['x-actions-results-crc64']).toEqual(digest.crc64)
|
||||
expect(headers['x-actions-results-md5']).toEqual(digest.md5)
|
||||
})
|
||||
|
||||
it('Test constructing upload headers with only required parameter', () => {
|
||||
const headers = utils.getUploadHeaders('application/octet-stream')
|
||||
expect(Object.keys(headers).length).toEqual(2)
|
||||
expect(headers['Accept']).toEqual(
|
||||
`application/json;api-version=${utils.getApiVersion()}`
|
||||
)
|
||||
expect(headers['Content-Type']).toEqual('application/octet-stream')
|
||||
})
|
||||
|
||||
it('Test constructing download headers with all optional parameters', () => {
|
||||
const contentType = 'application/json'
|
||||
const headers = utils.getDownloadHeaders(contentType, true, true)
|
||||
expect(Object.keys(headers).length).toEqual(5)
|
||||
expect(headers['Content-Type']).toEqual(contentType)
|
||||
expect(headers['Connection']).toEqual('Keep-Alive')
|
||||
expect(headers['Keep-Alive']).toEqual('10')
|
||||
expect(headers['Accept-Encoding']).toEqual('gzip')
|
||||
expect(headers['Accept']).toEqual(
|
||||
`application/octet-stream;api-version=${utils.getApiVersion()}`
|
||||
)
|
||||
})
|
||||
|
||||
it('Test constructing download headers with only required parameter', () => {
|
||||
const headers = utils.getDownloadHeaders('application/octet-stream')
|
||||
expect(Object.keys(headers).length).toEqual(2)
|
||||
expect(headers['Content-Type']).toEqual('application/octet-stream')
|
||||
// check for default accept type
|
||||
expect(headers['Accept']).toEqual(
|
||||
`application/json;api-version=${utils.getApiVersion()}`
|
||||
)
|
||||
})
|
||||
|
||||
it('Test Success Status Code', () => {
|
||||
expect(utils.isSuccessStatusCode(HttpCodes.OK)).toEqual(true)
|
||||
expect(utils.isSuccessStatusCode(201)).toEqual(true)
|
||||
expect(utils.isSuccessStatusCode(299)).toEqual(true)
|
||||
expect(utils.isSuccessStatusCode(HttpCodes.NotFound)).toEqual(false)
|
||||
expect(utils.isSuccessStatusCode(HttpCodes.BadGateway)).toEqual(false)
|
||||
expect(utils.isSuccessStatusCode(HttpCodes.Forbidden)).toEqual(false)
|
||||
})
|
||||
|
||||
it('Test Retry Status Code', () => {
|
||||
expect(utils.isRetryableStatusCode(HttpCodes.BadGateway)).toEqual(true)
|
||||
expect(utils.isRetryableStatusCode(HttpCodes.ServiceUnavailable)).toEqual(
|
||||
true
|
||||
)
|
||||
expect(utils.isRetryableStatusCode(HttpCodes.GatewayTimeout)).toEqual(true)
|
||||
expect(utils.isRetryableStatusCode(HttpCodes.TooManyRequests)).toEqual(true)
|
||||
expect(utils.isRetryableStatusCode(HttpCodes.OK)).toEqual(false)
|
||||
expect(utils.isRetryableStatusCode(HttpCodes.NotFound)).toEqual(false)
|
||||
expect(utils.isRetryableStatusCode(HttpCodes.Forbidden)).toEqual(false)
|
||||
expect(utils.isRetryableStatusCode(413)).toEqual(true) // Payload Too Large
|
||||
})
|
||||
|
||||
it('Test Throttled Status Code', () => {
|
||||
expect(utils.isThrottledStatusCode(HttpCodes.TooManyRequests)).toEqual(true)
|
||||
expect(utils.isThrottledStatusCode(HttpCodes.InternalServerError)).toEqual(
|
||||
false
|
||||
)
|
||||
expect(utils.isThrottledStatusCode(HttpCodes.BadGateway)).toEqual(false)
|
||||
expect(utils.isThrottledStatusCode(HttpCodes.ServiceUnavailable)).toEqual(
|
||||
false
|
||||
)
|
||||
})
|
||||
|
||||
it('Test Forbidden Status Code', () => {
|
||||
expect(utils.isForbiddenStatusCode(HttpCodes.Forbidden)).toEqual(true)
|
||||
expect(utils.isForbiddenStatusCode(HttpCodes.InternalServerError)).toEqual(
|
||||
false
|
||||
)
|
||||
expect(utils.isForbiddenStatusCode(HttpCodes.TooManyRequests)).toEqual(
|
||||
false
|
||||
)
|
||||
expect(utils.isForbiddenStatusCode(HttpCodes.OK)).toEqual(false)
|
||||
})
|
||||
|
||||
it('Test Creating Artifact Directories', async () => {
|
||||
const root = path.join(__dirname, '_temp', 'artifact-download')
|
||||
// remove directory before starting
|
||||
await io.rmRF(root)
|
||||
|
||||
const directory1 = path.join(root, 'folder2', 'folder3')
|
||||
const directory2 = path.join(directory1, 'folder1')
|
||||
|
||||
// Initially should not exist
|
||||
await expect(fs.promises.access(directory1)).rejects.not.toBeUndefined()
|
||||
await expect(fs.promises.access(directory2)).rejects.not.toBeUndefined()
|
||||
const directoryStructure = [directory1, directory2]
|
||||
await utils.createDirectoriesForArtifact(directoryStructure)
|
||||
// directories should now be created
|
||||
await expect(fs.promises.access(directory1)).resolves.toEqual(undefined)
|
||||
await expect(fs.promises.access(directory2)).resolves.toEqual(undefined)
|
||||
})
|
||||
|
||||
it('Test Creating Empty Files', async () => {
|
||||
const root = path.join(__dirname, '_temp', 'empty-files')
|
||||
await io.rmRF(root)
|
||||
|
||||
const emptyFile1 = path.join(root, 'emptyFile1')
|
||||
const directoryToCreate = path.join(root, 'folder1')
|
||||
const emptyFile2 = path.join(directoryToCreate, 'emptyFile2')
|
||||
|
||||
// empty files should only be created after the directory structure is fully setup
|
||||
// ensure they are first created by using the createDirectoriesForArtifact method
|
||||
const directoryStructure = [root, directoryToCreate]
|
||||
await utils.createDirectoriesForArtifact(directoryStructure)
|
||||
await expect(fs.promises.access(root)).resolves.toEqual(undefined)
|
||||
await expect(fs.promises.access(directoryToCreate)).resolves.toEqual(
|
||||
undefined
|
||||
)
|
||||
|
||||
await expect(fs.promises.access(emptyFile1)).rejects.not.toBeUndefined()
|
||||
await expect(fs.promises.access(emptyFile2)).rejects.not.toBeUndefined()
|
||||
|
||||
const emptyFilesToCreate = [emptyFile1, emptyFile2]
|
||||
await utils.createEmptyFilesForArtifact(emptyFilesToCreate)
|
||||
|
||||
await expect(fs.promises.access(emptyFile1)).resolves.toEqual(undefined)
|
||||
const size1 = (await fs.promises.stat(emptyFile1)).size
|
||||
expect(size1).toEqual(0)
|
||||
await expect(fs.promises.access(emptyFile2)).resolves.toEqual(undefined)
|
||||
const size2 = (await fs.promises.stat(emptyFile2)).size
|
||||
expect(size2).toEqual(0)
|
||||
})
|
||||
|
||||
it('Creates a digest from a readable stream', async () => {
|
||||
const data = 'lorem ipsum'
|
||||
const stream = Readable.from(data)
|
||||
const digest = await utils.digestForStream(stream)
|
||||
|
||||
expect(digest.crc64).toBe('bSzITYnW/P8=')
|
||||
expect(digest.md5).toBe('gKdR/eV3AoZAxBkADjPrpg==')
|
||||
})
|
||||
})
|
||||
@@ -1,53 +0,0 @@
|
||||
# Additional Information
|
||||
|
||||
Extra information
|
||||
- [Non-Supported Characters](#Non-Supported-Characters)
|
||||
- [Permission loss](#Permission-Loss)
|
||||
- [Considerations](#Considerations)
|
||||
- [Compression](#Is-my-artifact-compressed)
|
||||
|
||||
## Non-Supported Characters
|
||||
|
||||
When uploading an artifact, the inputted `name` parameter along with the files specified in `files` cannot contain any of the following characters. They will be rejected by the server if attempted to be sent over and the upload will fail. These characters are not allowed due to limitations and restrictions with certain file systems such as NTFS. To maintain platform-agnostic behavior, all characters that are not supported by an individual filesystem/platform will not be supported on all filesystems/platforms.
|
||||
|
||||
- "
|
||||
- :
|
||||
- <
|
||||
- \>
|
||||
- |
|
||||
- \*
|
||||
- ?
|
||||
|
||||
In addition to the aforementioned characters, the inputted `name` also cannot include the following
|
||||
- \
|
||||
- /
|
||||
|
||||
|
||||
## Permission Loss
|
||||
|
||||
File permissions are not maintained between uploaded and downloaded artifacts. If file permissions are something that need to be maintained (such as an executable), consider archiving all of the files using something like `tar` and then uploading the single archive. After downloading the artifact, you can `un-tar` the individual file and permissions will be preserved.
|
||||
|
||||
```js
|
||||
const artifact = require('@actions/artifact');
|
||||
const artifactClient = artifact.create()
|
||||
const artifactName = 'my-artifact';
|
||||
const files = [
|
||||
'/home/user/files/plz-upload/my-archive.tgz',
|
||||
]
|
||||
const rootDirectory = '/home/user/files/plz-upload'
|
||||
const uploadResult = await artifactClient.uploadArtifact(artifactName, files, rootDirectory)
|
||||
```
|
||||
|
||||
## Considerations
|
||||
|
||||
During upload, each file is uploaded concurrently in 4MB chunks using a separate HTTPS connection per file. Chunked uploads are used so that in the event of a failure (which is entirely possible because the internet is not perfect), the upload can be retried. If there is an error, a retry will be attempted after a certain period of time.
|
||||
|
||||
Uploading will be generally be faster if there are fewer files that are larger in size vs if there are lots of smaller files. Depending on the types and quantities of files being uploaded, it might be beneficial to separately compress and archive everything into a single archive (using something like `tar` or `zip`) before starting and artifact upload to speed things up.
|
||||
|
||||
## Is my artifact compressed?
|
||||
|
||||
GZip is used internally to compress individual files before starting an upload. Compression helps reduce the total amount of data that must be uploaded and stored while helping to speed up uploads (this performance benefit is significant especially on self hosted runners). If GZip does not reduce the size of the file that is being uploaded, the original file is uploaded as-is.
|
||||
|
||||
Compression using GZip also helps speed up artifact download as part of a workflow. Header information is used to determine if an individual file was uploaded using GZip and if necessary, decompression is used.
|
||||
|
||||
When downloading an artifact from the GitHub UI (this differs from downloading an artifact during a workflow), a single Zip file is dynamically created that contains all of the files uploaded as part of an artifact. Any files that were uploaded using GZip will be decompressed on the server before being added to the Zip file with the remaining files.
|
||||
@@ -1,57 +0,0 @@
|
||||
# Implementation Details
|
||||
|
||||
Warning: Implementation details may change at any time without notice. This is meant to serve as a reference to help users understand the package.
|
||||
|
||||
## Upload/Compression flow
|
||||
|
||||
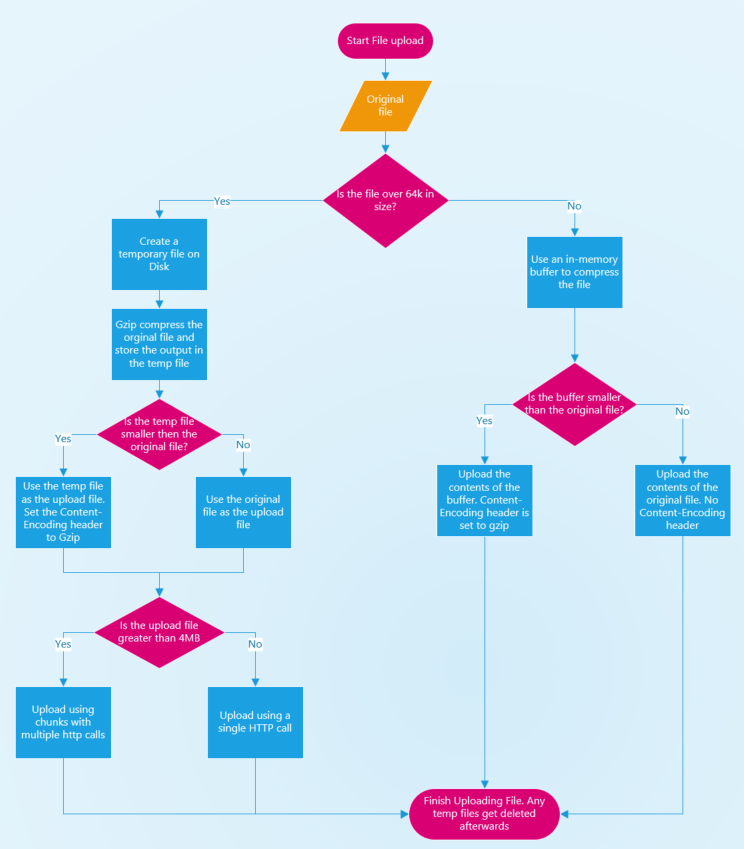
|
||||
|
||||
During artifact upload, gzip is used to compress individual files that then get uploaded. This is used to minimize the amount of data that gets uploaded which reduces the total amount of HTTP calls (upload happens in 4MB chunks). This results in considerably faster uploads with huge performance implications especially on self-hosted runners.
|
||||
|
||||
If a file is less than 64KB in size, a passthrough stream (readable and writable) is used to convert an in-memory buffer into a readable stream without any extra streams or pipping.
|
||||
|
||||
## Retry Logic when downloading an individual file
|
||||
|
||||

|
||||
|
||||
## Proxy support
|
||||
|
||||
This package uses the `@actions/http-client` NPM package internally which supports proxied requests out of the box.
|
||||
|
||||
## HttpManager
|
||||
|
||||
### `keep-alive` header
|
||||
|
||||
When an HTTP call is made to upload or download an individual file, the server will close the HTTP connection after the upload/download is complete and respond with a header indicating `Connection: close`.
|
||||
|
||||
[HTTP closed connection header information](https://tools.ietf.org/html/rfc2616#section-14.10)
|
||||
|
||||
TCP connections are sometimes not immediately closed by the node client (Windows might hold on to the port for an extra period of time before actually releasing it for example) and a large amount of closed connections can cause port exhaustion before ports get released and are available again.
|
||||
|
||||
VMs hosted by GitHub Actions have 1024 available ports so uploading 1000+ files very quickly can cause port exhaustion if connections get closed immediately. This can start to cause strange undefined behavior and timeouts.
|
||||
|
||||
In order for connections to not close immediately, the `keep-alive` header is used to indicate to the server that the connection should stay open. If a `keep-alive` header is used, the connection needs to be disposed of by calling `dispose()` in the `HttpClient`.
|
||||
|
||||
[`keep-alive` header information](https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Keep-Alive)
|
||||
[@actions/http-client client disposal](https://github.com/actions/http-client/blob/04e5ad73cd3fd1f5610a32116b0759eddf6570d2/index.ts#L292)
|
||||
|
||||
|
||||
### Multiple HTTP clients
|
||||
|
||||
During an artifact upload or download, files are concurrently uploaded or downloaded using `async/await`. When an error or retry is encountered, the `HttpClient` that made a call is disposed of and a new one is created. If a single `HttpClient` was used for all HTTP calls and it had to be disposed, it could inadvertently effect any other calls that could be concurrently happening.
|
||||
|
||||
Any other concurrent uploads or downloads should be left untouched. Because of this, each concurrent upload or download gets its own `HttpClient`. The `http-manager` is used to manage all available clients and each concurrent upload or download maintains a `httpClientIndex` that keep track of which client should be used (and potentially disposed and recycled if necessary)
|
||||
|
||||
### Potential resource leaks
|
||||
|
||||
When an HTTP response is received, it consists of two parts
|
||||
- `message`
|
||||
- `body`
|
||||
|
||||
The `message` contains information such as the response code and header information and it is available immediately. The body however is not available immediately and it can be read by calling `await response.readBody()`.
|
||||
|
||||
TCP connections consist of an input and output buffer to manage what is sent and received across a connection. If the body is not read (even if its contents are not needed) the buffers can stay in use even after `dispose()` gets called on the `HttpClient`. The buffers get released automatically after a certain period of time, but in order for them to be explicitly cleared, `readBody()` is always called.
|
||||
|
||||
### Non Concurrent calls
|
||||
|
||||
Both `upload-http-client` and `download-http-client` do not instantiate or create any HTTP clients (the `HttpManager` has that responsibility). If an HTTP call has to be made that does not require the `keep-alive` header (such as when calling `listArtifacts` or `patchArtifactSize`), the first `HttpClient` in the `HttpManager` is used. The number of available clients is equal to the upload or download concurrency and there will always be at least one available.
|
||||
Generated
-339
@@ -1,339 +0,0 @@
|
||||
{
|
||||
"name": "@actions/artifact",
|
||||
"version": "1.1.1",
|
||||
"lockfileVersion": 2,
|
||||
"requires": true,
|
||||
"packages": {
|
||||
"": {
|
||||
"name": "@actions/artifact",
|
||||
"version": "1.1.1",
|
||||
"license": "MIT",
|
||||
"dependencies": {
|
||||
"@actions/core": "^1.9.1",
|
||||
"@actions/http-client": "^2.0.1",
|
||||
"tmp": "^0.2.1",
|
||||
"tmp-promise": "^3.0.2"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@types/tmp": "^0.2.1",
|
||||
"typescript": "^3.8.3"
|
||||
}
|
||||
},
|
||||
"node_modules/@actions/core": {
|
||||
"version": "1.9.1",
|
||||
"resolved": "https://registry.npmjs.org/@actions/core/-/core-1.9.1.tgz",
|
||||
"integrity": "sha512-5ad+U2YGrmmiw6du20AQW5XuWo7UKN2052FjSV7MX+Wfjf8sCqcsZe62NfgHys4QI4/Y+vQvLKYL8jWtA1ZBTA==",
|
||||
"dependencies": {
|
||||
"@actions/http-client": "^2.0.1",
|
||||
"uuid": "^8.3.2"
|
||||
}
|
||||
},
|
||||
"node_modules/@actions/http-client": {
|
||||
"version": "2.0.1",
|
||||
"resolved": "https://registry.npmjs.org/@actions/http-client/-/http-client-2.0.1.tgz",
|
||||
"integrity": "sha512-PIXiMVtz6VvyaRsGY268qvj57hXQEpsYogYOu2nrQhlf+XCGmZstmuZBbAybUl1nQGnvS1k1eEsQ69ZoD7xlSw==",
|
||||
"dependencies": {
|
||||
"tunnel": "^0.0.6"
|
||||
}
|
||||
},
|
||||
"node_modules/@types/tmp": {
|
||||
"version": "0.2.3",
|
||||
"resolved": "https://registry.npmjs.org/@types/tmp/-/tmp-0.2.3.tgz",
|
||||
"integrity": "sha512-dDZH/tXzwjutnuk4UacGgFRwV+JSLaXL1ikvidfJprkb7L9Nx1njcRHHmi3Dsvt7pgqqTEeucQuOrWHPFgzVHA==",
|
||||
"dev": true
|
||||
},
|
||||
"node_modules/balanced-match": {
|
||||
"version": "1.0.2",
|
||||
"resolved": "https://registry.npmjs.org/balanced-match/-/balanced-match-1.0.2.tgz",
|
||||
"integrity": "sha512-3oSeUO0TMV67hN1AmbXsK4yaqU7tjiHlbxRDZOpH0KW9+CeX4bRAaX0Anxt0tx2MrpRpWwQaPwIlISEJhYU5Pw=="
|
||||
},
|
||||
"node_modules/brace-expansion": {
|
||||
"version": "1.1.11",
|
||||
"resolved": "https://registry.npmjs.org/brace-expansion/-/brace-expansion-1.1.11.tgz",
|
||||
"integrity": "sha512-iCuPHDFgrHX7H2vEI/5xpz07zSHB00TpugqhmYtVmMO6518mCuRMoOYFldEBl0g187ufozdaHgWKcYFb61qGiA==",
|
||||
"dependencies": {
|
||||
"balanced-match": "^1.0.0",
|
||||
"concat-map": "0.0.1"
|
||||
}
|
||||
},
|
||||
"node_modules/concat-map": {
|
||||
"version": "0.0.1",
|
||||
"resolved": "https://registry.npmjs.org/concat-map/-/concat-map-0.0.1.tgz",
|
||||
"integrity": "sha1-2Klr13/Wjfd5OnMDajug1UBdR3s="
|
||||
},
|
||||
"node_modules/fs.realpath": {
|
||||
"version": "1.0.0",
|
||||
"resolved": "https://registry.npmjs.org/fs.realpath/-/fs.realpath-1.0.0.tgz",
|
||||
"integrity": "sha1-FQStJSMVjKpA20onh8sBQRmU6k8="
|
||||
},
|
||||
"node_modules/glob": {
|
||||
"version": "7.2.0",
|
||||
"resolved": "https://registry.npmjs.org/glob/-/glob-7.2.0.tgz",
|
||||
"integrity": "sha512-lmLf6gtyrPq8tTjSmrO94wBeQbFR3HbLHbuyD69wuyQkImp2hWqMGB47OX65FBkPffO641IP9jWa1z4ivqG26Q==",
|
||||
"dependencies": {
|
||||
"fs.realpath": "^1.0.0",
|
||||
"inflight": "^1.0.4",
|
||||
"inherits": "2",
|
||||
"minimatch": "^3.0.4",
|
||||
"once": "^1.3.0",
|
||||
"path-is-absolute": "^1.0.0"
|
||||
},
|
||||
"engines": {
|
||||
"node": "*"
|
||||
},
|
||||
"funding": {
|
||||
"url": "https://github.com/sponsors/isaacs"
|
||||
}
|
||||
},
|
||||
"node_modules/inflight": {
|
||||
"version": "1.0.6",
|
||||
"resolved": "https://registry.npmjs.org/inflight/-/inflight-1.0.6.tgz",
|
||||
"integrity": "sha1-Sb1jMdfQLQwJvJEKEHW6gWW1bfk=",
|
||||
"dependencies": {
|
||||
"once": "^1.3.0",
|
||||
"wrappy": "1"
|
||||
}
|
||||
},
|
||||
"node_modules/inherits": {
|
||||
"version": "2.0.4",
|
||||
"resolved": "https://registry.npmjs.org/inherits/-/inherits-2.0.4.tgz",
|
||||
"integrity": "sha512-k/vGaX4/Yla3WzyMCvTQOXYeIHvqOKtnqBduzTHpzpQZzAskKMhZ2K+EnBiSM9zGSoIFeMpXKxa4dYeZIQqewQ=="
|
||||
},
|
||||
"node_modules/minimatch": {
|
||||
"version": "3.1.2",
|
||||
"resolved": "https://registry.npmjs.org/minimatch/-/minimatch-3.1.2.tgz",
|
||||
"integrity": "sha512-J7p63hRiAjw1NDEww1W7i37+ByIrOWO5XQQAzZ3VOcL0PNybwpfmV/N05zFAzwQ9USyEcX6t3UO+K5aqBQOIHw==",
|
||||
"dependencies": {
|
||||
"brace-expansion": "^1.1.7"
|
||||
},
|
||||
"engines": {
|
||||
"node": "*"
|
||||
}
|
||||
},
|
||||
"node_modules/once": {
|
||||
"version": "1.4.0",
|
||||
"resolved": "https://registry.npmjs.org/once/-/once-1.4.0.tgz",
|
||||
"integrity": "sha1-WDsap3WWHUsROsF9nFC6753Xa9E=",
|
||||
"dependencies": {
|
||||
"wrappy": "1"
|
||||
}
|
||||
},
|
||||
"node_modules/path-is-absolute": {
|
||||
"version": "1.0.1",
|
||||
"resolved": "https://registry.npmjs.org/path-is-absolute/-/path-is-absolute-1.0.1.tgz",
|
||||
"integrity": "sha1-F0uSaHNVNP+8es5r9TpanhtcX18=",
|
||||
"engines": {
|
||||
"node": ">=0.10.0"
|
||||
}
|
||||
},
|
||||
"node_modules/rimraf": {
|
||||
"version": "3.0.2",
|
||||
"resolved": "https://registry.npmjs.org/rimraf/-/rimraf-3.0.2.tgz",
|
||||
"integrity": "sha512-JZkJMZkAGFFPP2YqXZXPbMlMBgsxzE8ILs4lMIX/2o0L9UBw9O/Y3o6wFw/i9YLapcUJWwqbi3kdxIPdC62TIA==",
|
||||
"dependencies": {
|
||||
"glob": "^7.1.3"
|
||||
},
|
||||
"bin": {
|
||||
"rimraf": "bin.js"
|
||||
},
|
||||
"funding": {
|
||||
"url": "https://github.com/sponsors/isaacs"
|
||||
}
|
||||
},
|
||||
"node_modules/tmp": {
|
||||
"version": "0.2.1",
|
||||
"resolved": "https://registry.npmjs.org/tmp/-/tmp-0.2.1.tgz",
|
||||
"integrity": "sha512-76SUhtfqR2Ijn+xllcI5P1oyannHNHByD80W1q447gU3mp9G9PSpGdWmjUOHRDPiHYacIk66W7ubDTuPF3BEtQ==",
|
||||
"dependencies": {
|
||||
"rimraf": "^3.0.0"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=8.17.0"
|
||||
}
|
||||
},
|
||||
"node_modules/tmp-promise": {
|
||||
"version": "3.0.3",
|
||||
"resolved": "https://registry.npmjs.org/tmp-promise/-/tmp-promise-3.0.3.tgz",
|
||||
"integrity": "sha512-RwM7MoPojPxsOBYnyd2hy0bxtIlVrihNs9pj5SUvY8Zz1sQcQG2tG1hSr8PDxfgEB8RNKDhqbIlroIarSNDNsQ==",
|
||||
"dependencies": {
|
||||
"tmp": "^0.2.0"
|
||||
}
|
||||
},
|
||||
"node_modules/tunnel": {
|
||||
"version": "0.0.6",
|
||||
"resolved": "https://registry.npmjs.org/tunnel/-/tunnel-0.0.6.tgz",
|
||||
"integrity": "sha512-1h/Lnq9yajKY2PEbBadPXj3VxsDDu844OnaAo52UVmIzIvwwtBPIuNvkjuzBlTWpfJyUbG3ez0KSBibQkj4ojg==",
|
||||
"engines": {
|
||||
"node": ">=0.6.11 <=0.7.0 || >=0.7.3"
|
||||
}
|
||||
},
|
||||
"node_modules/typescript": {
|
||||
"version": "3.9.10",
|
||||
"resolved": "https://registry.npmjs.org/typescript/-/typescript-3.9.10.tgz",
|
||||
"integrity": "sha512-w6fIxVE/H1PkLKcCPsFqKE7Kv7QUwhU8qQY2MueZXWx5cPZdwFupLgKK3vntcK98BtNHZtAF4LA/yl2a7k8R6Q==",
|
||||
"dev": true,
|
||||
"bin": {
|
||||
"tsc": "bin/tsc",
|
||||
"tsserver": "bin/tsserver"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=4.2.0"
|
||||
}
|
||||
},
|
||||
"node_modules/uuid": {
|
||||
"version": "8.3.2",
|
||||
"resolved": "https://registry.npmjs.org/uuid/-/uuid-8.3.2.tgz",
|
||||
"integrity": "sha512-+NYs2QeMWy+GWFOEm9xnn6HCDp0l7QBD7ml8zLUmJ+93Q5NF0NocErnwkTkXVFNiX3/fpC6afS8Dhb/gz7R7eg==",
|
||||
"bin": {
|
||||
"uuid": "dist/bin/uuid"
|
||||
}
|
||||
},
|
||||
"node_modules/wrappy": {
|
||||
"version": "1.0.2",
|
||||
"resolved": "https://registry.npmjs.org/wrappy/-/wrappy-1.0.2.tgz",
|
||||
"integrity": "sha1-tSQ9jz7BqjXxNkYFvA0QNuMKtp8="
|
||||
}
|
||||
},
|
||||
"dependencies": {
|
||||
"@actions/core": {
|
||||
"version": "1.9.1",
|
||||
"resolved": "https://registry.npmjs.org/@actions/core/-/core-1.9.1.tgz",
|
||||
"integrity": "sha512-5ad+U2YGrmmiw6du20AQW5XuWo7UKN2052FjSV7MX+Wfjf8sCqcsZe62NfgHys4QI4/Y+vQvLKYL8jWtA1ZBTA==",
|
||||
"requires": {
|
||||
"@actions/http-client": "^2.0.1",
|
||||
"uuid": "^8.3.2"
|
||||
}
|
||||
},
|
||||
"@actions/http-client": {
|
||||
"version": "2.0.1",
|
||||
"resolved": "https://registry.npmjs.org/@actions/http-client/-/http-client-2.0.1.tgz",
|
||||
"integrity": "sha512-PIXiMVtz6VvyaRsGY268qvj57hXQEpsYogYOu2nrQhlf+XCGmZstmuZBbAybUl1nQGnvS1k1eEsQ69ZoD7xlSw==",
|
||||
"requires": {
|
||||
"tunnel": "^0.0.6"
|
||||
}
|
||||
},
|
||||
"@types/tmp": {
|
||||
"version": "0.2.3",
|
||||
"resolved": "https://registry.npmjs.org/@types/tmp/-/tmp-0.2.3.tgz",
|
||||
"integrity": "sha512-dDZH/tXzwjutnuk4UacGgFRwV+JSLaXL1ikvidfJprkb7L9Nx1njcRHHmi3Dsvt7pgqqTEeucQuOrWHPFgzVHA==",
|
||||
"dev": true
|
||||
},
|
||||
"balanced-match": {
|
||||
"version": "1.0.2",
|
||||
"resolved": "https://registry.npmjs.org/balanced-match/-/balanced-match-1.0.2.tgz",
|
||||
"integrity": "sha512-3oSeUO0TMV67hN1AmbXsK4yaqU7tjiHlbxRDZOpH0KW9+CeX4bRAaX0Anxt0tx2MrpRpWwQaPwIlISEJhYU5Pw=="
|
||||
},
|
||||
"brace-expansion": {
|
||||
"version": "1.1.11",
|
||||
"resolved": "https://registry.npmjs.org/brace-expansion/-/brace-expansion-1.1.11.tgz",
|
||||
"integrity": "sha512-iCuPHDFgrHX7H2vEI/5xpz07zSHB00TpugqhmYtVmMO6518mCuRMoOYFldEBl0g187ufozdaHgWKcYFb61qGiA==",
|
||||
"requires": {
|
||||
"balanced-match": "^1.0.0",
|
||||
"concat-map": "0.0.1"
|
||||
}
|
||||
},
|
||||
"concat-map": {
|
||||
"version": "0.0.1",
|
||||
"resolved": "https://registry.npmjs.org/concat-map/-/concat-map-0.0.1.tgz",
|
||||
"integrity": "sha1-2Klr13/Wjfd5OnMDajug1UBdR3s="
|
||||
},
|
||||
"fs.realpath": {
|
||||
"version": "1.0.0",
|
||||
"resolved": "https://registry.npmjs.org/fs.realpath/-/fs.realpath-1.0.0.tgz",
|
||||
"integrity": "sha1-FQStJSMVjKpA20onh8sBQRmU6k8="
|
||||
},
|
||||
"glob": {
|
||||
"version": "7.2.0",
|
||||
"resolved": "https://registry.npmjs.org/glob/-/glob-7.2.0.tgz",
|
||||
"integrity": "sha512-lmLf6gtyrPq8tTjSmrO94wBeQbFR3HbLHbuyD69wuyQkImp2hWqMGB47OX65FBkPffO641IP9jWa1z4ivqG26Q==",
|
||||
"requires": {
|
||||
"fs.realpath": "^1.0.0",
|
||||
"inflight": "^1.0.4",
|
||||
"inherits": "2",
|
||||
"minimatch": "^3.0.4",
|
||||
"once": "^1.3.0",
|
||||
"path-is-absolute": "^1.0.0"
|
||||
}
|
||||
},
|
||||
"inflight": {
|
||||
"version": "1.0.6",
|
||||
"resolved": "https://registry.npmjs.org/inflight/-/inflight-1.0.6.tgz",
|
||||
"integrity": "sha1-Sb1jMdfQLQwJvJEKEHW6gWW1bfk=",
|
||||
"requires": {
|
||||
"once": "^1.3.0",
|
||||
"wrappy": "1"
|
||||
}
|
||||
},
|
||||
"inherits": {
|
||||
"version": "2.0.4",
|
||||
"resolved": "https://registry.npmjs.org/inherits/-/inherits-2.0.4.tgz",
|
||||
"integrity": "sha512-k/vGaX4/Yla3WzyMCvTQOXYeIHvqOKtnqBduzTHpzpQZzAskKMhZ2K+EnBiSM9zGSoIFeMpXKxa4dYeZIQqewQ=="
|
||||
},
|
||||
"minimatch": {
|
||||
"version": "3.1.2",
|
||||
"resolved": "https://registry.npmjs.org/minimatch/-/minimatch-3.1.2.tgz",
|
||||
"integrity": "sha512-J7p63hRiAjw1NDEww1W7i37+ByIrOWO5XQQAzZ3VOcL0PNybwpfmV/N05zFAzwQ9USyEcX6t3UO+K5aqBQOIHw==",
|
||||
"requires": {
|
||||
"brace-expansion": "^1.1.7"
|
||||
}
|
||||
},
|
||||
"once": {
|
||||
"version": "1.4.0",
|
||||
"resolved": "https://registry.npmjs.org/once/-/once-1.4.0.tgz",
|
||||
"integrity": "sha1-WDsap3WWHUsROsF9nFC6753Xa9E=",
|
||||
"requires": {
|
||||
"wrappy": "1"
|
||||
}
|
||||
},
|
||||
"path-is-absolute": {
|
||||
"version": "1.0.1",
|
||||
"resolved": "https://registry.npmjs.org/path-is-absolute/-/path-is-absolute-1.0.1.tgz",
|
||||
"integrity": "sha1-F0uSaHNVNP+8es5r9TpanhtcX18="
|
||||
},
|
||||
"rimraf": {
|
||||
"version": "3.0.2",
|
||||
"resolved": "https://registry.npmjs.org/rimraf/-/rimraf-3.0.2.tgz",
|
||||
"integrity": "sha512-JZkJMZkAGFFPP2YqXZXPbMlMBgsxzE8ILs4lMIX/2o0L9UBw9O/Y3o6wFw/i9YLapcUJWwqbi3kdxIPdC62TIA==",
|
||||
"requires": {
|
||||
"glob": "^7.1.3"
|
||||
}
|
||||
},
|
||||
"tmp": {
|
||||
"version": "0.2.1",
|
||||
"resolved": "https://registry.npmjs.org/tmp/-/tmp-0.2.1.tgz",
|
||||
"integrity": "sha512-76SUhtfqR2Ijn+xllcI5P1oyannHNHByD80W1q447gU3mp9G9PSpGdWmjUOHRDPiHYacIk66W7ubDTuPF3BEtQ==",
|
||||
"requires": {
|
||||
"rimraf": "^3.0.0"
|
||||
}
|
||||
},
|
||||
"tmp-promise": {
|
||||
"version": "3.0.3",
|
||||
"resolved": "https://registry.npmjs.org/tmp-promise/-/tmp-promise-3.0.3.tgz",
|
||||
"integrity": "sha512-RwM7MoPojPxsOBYnyd2hy0bxtIlVrihNs9pj5SUvY8Zz1sQcQG2tG1hSr8PDxfgEB8RNKDhqbIlroIarSNDNsQ==",
|
||||
"requires": {
|
||||
"tmp": "^0.2.0"
|
||||
}
|
||||
},
|
||||
"tunnel": {
|
||||
"version": "0.0.6",
|
||||
"resolved": "https://registry.npmjs.org/tunnel/-/tunnel-0.0.6.tgz",
|
||||
"integrity": "sha512-1h/Lnq9yajKY2PEbBadPXj3VxsDDu844OnaAo52UVmIzIvwwtBPIuNvkjuzBlTWpfJyUbG3ez0KSBibQkj4ojg=="
|
||||
},
|
||||
"typescript": {
|
||||
"version": "3.9.10",
|
||||
"resolved": "https://registry.npmjs.org/typescript/-/typescript-3.9.10.tgz",
|
||||
"integrity": "sha512-w6fIxVE/H1PkLKcCPsFqKE7Kv7QUwhU8qQY2MueZXWx5cPZdwFupLgKK3vntcK98BtNHZtAF4LA/yl2a7k8R6Q==",
|
||||
"dev": true
|
||||
},
|
||||
"uuid": {
|
||||
"version": "8.3.2",
|
||||
"resolved": "https://registry.npmjs.org/uuid/-/uuid-8.3.2.tgz",
|
||||
"integrity": "sha512-+NYs2QeMWy+GWFOEm9xnn6HCDp0l7QBD7ml8zLUmJ+93Q5NF0NocErnwkTkXVFNiX3/fpC6afS8Dhb/gz7R7eg=="
|
||||
},
|
||||
"wrappy": {
|
||||
"version": "1.0.2",
|
||||
"resolved": "https://registry.npmjs.org/wrappy/-/wrappy-1.0.2.tgz",
|
||||
"integrity": "sha1-tSQ9jz7BqjXxNkYFvA0QNuMKtp8="
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -1,49 +0,0 @@
|
||||
{
|
||||
"name": "@actions/artifact",
|
||||
"version": "1.1.1",
|
||||
"preview": true,
|
||||
"description": "Actions artifact lib",
|
||||
"keywords": [
|
||||
"github",
|
||||
"actions",
|
||||
"artifact"
|
||||
],
|
||||
"homepage": "https://github.com/actions/toolkit/tree/main/packages/artifact",
|
||||
"license": "MIT",
|
||||
"main": "lib/artifact-client.js",
|
||||
"types": "lib/artifact-client.d.ts",
|
||||
"directories": {
|
||||
"lib": "lib",
|
||||
"test": "__tests__"
|
||||
},
|
||||
"files": [
|
||||
"lib",
|
||||
"!.DS_Store"
|
||||
],
|
||||
"publishConfig": {
|
||||
"access": "public"
|
||||
},
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git+https://github.com/actions/toolkit.git",
|
||||
"directory": "packages/artifact"
|
||||
},
|
||||
"scripts": {
|
||||
"audit-moderate": "npm install && npm audit --json --audit-level=moderate > audit.json",
|
||||
"test": "echo \"Error: run tests from root\" && exit 1",
|
||||
"tsc": "tsc"
|
||||
},
|
||||
"bugs": {
|
||||
"url": "https://github.com/actions/toolkit/issues"
|
||||
},
|
||||
"dependencies": {
|
||||
"@actions/core": "^1.9.1",
|
||||
"@actions/http-client": "^2.0.1",
|
||||
"tmp": "^0.2.1",
|
||||
"tmp-promise": "^3.0.2"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@types/tmp": "^0.2.1",
|
||||
"typescript": "^3.8.3"
|
||||
}
|
||||
}
|
||||
@@ -1,20 +0,0 @@
|
||||
import {UploadOptions} from './internal/upload-options'
|
||||
import {UploadResponse} from './internal/upload-response'
|
||||
import {DownloadOptions} from './internal/download-options'
|
||||
import {DownloadResponse} from './internal/download-response'
|
||||
import {ArtifactClient, DefaultArtifactClient} from './internal/artifact-client'
|
||||
|
||||
export {
|
||||
ArtifactClient,
|
||||
UploadResponse,
|
||||
UploadOptions,
|
||||
DownloadResponse,
|
||||
DownloadOptions
|
||||
}
|
||||
|
||||
/**
|
||||
* Constructs an ArtifactClient
|
||||
*/
|
||||
export function create(): ArtifactClient {
|
||||
return DefaultArtifactClient.create()
|
||||
}
|
||||
@@ -1,51 +0,0 @@
|
||||
/**
|
||||
* Mocks default limits for easier testing
|
||||
*/
|
||||
export function getUploadFileConcurrency(): number {
|
||||
return 1
|
||||
}
|
||||
|
||||
export function getUploadChunkConcurrency(): number {
|
||||
return 1
|
||||
}
|
||||
|
||||
export function getUploadChunkSize(): number {
|
||||
return 4 * 1024 * 1024 // 4 MB Chunks
|
||||
}
|
||||
|
||||
export function getRetryLimit(): number {
|
||||
return 2
|
||||
}
|
||||
|
||||
export function getRetryMultiplier(): number {
|
||||
return 1.5
|
||||
}
|
||||
|
||||
export function getInitialRetryIntervalInMilliseconds(): number {
|
||||
return 10
|
||||
}
|
||||
|
||||
export function getDownloadFileConcurrency(): number {
|
||||
return 1
|
||||
}
|
||||
|
||||
/**
|
||||
* Mocks the 'ACTIONS_RUNTIME_TOKEN', 'ACTIONS_RUNTIME_URL' and 'GITHUB_RUN_ID' env variables
|
||||
* that are only available from a node context on the runner. This allows for tests to run
|
||||
* locally without the env variables actually being set
|
||||
*/
|
||||
export function getRuntimeToken(): string {
|
||||
return 'totally-valid-token'
|
||||
}
|
||||
|
||||
export function getRuntimeUrl(): string {
|
||||
return 'https://www.example.com/'
|
||||
}
|
||||
|
||||
export function getWorkFlowRunId(): string {
|
||||
return '15'
|
||||
}
|
||||
|
||||
export function getRetentionDays(): string | undefined {
|
||||
return '45'
|
||||
}
|
||||
@@ -1,282 +0,0 @@
|
||||
import * as core from '@actions/core'
|
||||
import {
|
||||
UploadSpecification,
|
||||
getUploadSpecification
|
||||
} from './upload-specification'
|
||||
import {UploadHttpClient} from './upload-http-client'
|
||||
import {UploadResponse} from './upload-response'
|
||||
import {UploadOptions} from './upload-options'
|
||||
import {DownloadOptions} from './download-options'
|
||||
import {DownloadResponse} from './download-response'
|
||||
import {
|
||||
createDirectoriesForArtifact,
|
||||
createEmptyFilesForArtifact
|
||||
} from './utils'
|
||||
import {checkArtifactName} from './path-and-artifact-name-validation'
|
||||
import {DownloadHttpClient} from './download-http-client'
|
||||
import {getDownloadSpecification} from './download-specification'
|
||||
import {getWorkSpaceDirectory} from './config-variables'
|
||||
import {normalize, resolve} from 'path'
|
||||
|
||||
export interface ArtifactClient {
|
||||
/**
|
||||
* Uploads an artifact
|
||||
*
|
||||
* @param name the name of the artifact, required
|
||||
* @param files a list of absolute or relative paths that denote what files should be uploaded
|
||||
* @param rootDirectory an absolute or relative file path that denotes the root parent directory of the files being uploaded
|
||||
* @param options extra options for customizing the upload behavior
|
||||
* @returns single UploadInfo object
|
||||
*/
|
||||
uploadArtifact(
|
||||
name: string,
|
||||
files: string[],
|
||||
rootDirectory: string,
|
||||
options?: UploadOptions
|
||||
): Promise<UploadResponse>
|
||||
|
||||
/**
|
||||
* Downloads a single artifact associated with a run
|
||||
*
|
||||
* @param name the name of the artifact being downloaded
|
||||
* @param path optional path that denotes where the artifact will be downloaded to
|
||||
* @param options extra options that allow for the customization of the download behavior
|
||||
*/
|
||||
downloadArtifact(
|
||||
name: string,
|
||||
path?: string,
|
||||
options?: DownloadOptions
|
||||
): Promise<DownloadResponse>
|
||||
|
||||
/**
|
||||
* Downloads all artifacts associated with a run. Because there are multiple artifacts being downloaded, a folder will be created for each one in the specified or default directory
|
||||
* @param path optional path that denotes where the artifacts will be downloaded to
|
||||
*/
|
||||
downloadAllArtifacts(path?: string): Promise<DownloadResponse[]>
|
||||
}
|
||||
|
||||
export class DefaultArtifactClient implements ArtifactClient {
|
||||
/**
|
||||
* Constructs a DefaultArtifactClient
|
||||
*/
|
||||
static create(): DefaultArtifactClient {
|
||||
return new DefaultArtifactClient()
|
||||
}
|
||||
|
||||
/**
|
||||
* Uploads an artifact
|
||||
*/
|
||||
async uploadArtifact(
|
||||
name: string,
|
||||
files: string[],
|
||||
rootDirectory: string,
|
||||
options?: UploadOptions | undefined
|
||||
): Promise<UploadResponse> {
|
||||
core.info(
|
||||
`Starting artifact upload
|
||||
For more detailed logs during the artifact upload process, enable step-debugging: https://docs.github.com/actions/monitoring-and-troubleshooting-workflows/enabling-debug-logging#enabling-step-debug-logging`
|
||||
)
|
||||
checkArtifactName(name)
|
||||
|
||||
// Get specification for the files being uploaded
|
||||
const uploadSpecification: UploadSpecification[] = getUploadSpecification(
|
||||
name,
|
||||
rootDirectory,
|
||||
files
|
||||
)
|
||||
const uploadResponse: UploadResponse = {
|
||||
artifactName: name,
|
||||
artifactItems: [],
|
||||
size: 0,
|
||||
failedItems: []
|
||||
}
|
||||
|
||||
const uploadHttpClient = new UploadHttpClient()
|
||||
|
||||
if (uploadSpecification.length === 0) {
|
||||
core.warning(`No files found that can be uploaded`)
|
||||
} else {
|
||||
// Create an entry for the artifact in the file container
|
||||
const response = await uploadHttpClient.createArtifactInFileContainer(
|
||||
name,
|
||||
options
|
||||
)
|
||||
if (!response.fileContainerResourceUrl) {
|
||||
core.debug(response.toString())
|
||||
throw new Error(
|
||||
'No URL provided by the Artifact Service to upload an artifact to'
|
||||
)
|
||||
}
|
||||
|
||||
core.debug(`Upload Resource URL: ${response.fileContainerResourceUrl}`)
|
||||
core.info(
|
||||
`Container for artifact "${name}" successfully created. Starting upload of file(s)`
|
||||
)
|
||||
|
||||
// Upload each of the files that were found concurrently
|
||||
const uploadResult = await uploadHttpClient.uploadArtifactToFileContainer(
|
||||
response.fileContainerResourceUrl,
|
||||
uploadSpecification,
|
||||
options
|
||||
)
|
||||
|
||||
// Update the size of the artifact to indicate we are done uploading
|
||||
// The uncompressed size is used for display when downloading a zip of the artifact from the UI
|
||||
core.info(
|
||||
`File upload process has finished. Finalizing the artifact upload`
|
||||
)
|
||||
await uploadHttpClient.patchArtifactSize(uploadResult.totalSize, name)
|
||||
|
||||
if (uploadResult.failedItems.length > 0) {
|
||||
core.info(
|
||||
`Upload finished. There were ${uploadResult.failedItems.length} items that failed to upload`
|
||||
)
|
||||
} else {
|
||||
core.info(
|
||||
`Artifact has been finalized. All files have been successfully uploaded!`
|
||||
)
|
||||
}
|
||||
|
||||
core.info(
|
||||
`
|
||||
The raw size of all the files that were specified for upload is ${uploadResult.totalSize} bytes
|
||||
The size of all the files that were uploaded is ${uploadResult.uploadSize} bytes. This takes into account any gzip compression used to reduce the upload size, time and storage
|
||||
|
||||
Note: The size of downloaded zips can differ significantly from the reported size. For more information see: https://github.com/actions/upload-artifact#zipped-artifact-downloads \r\n`
|
||||
)
|
||||
|
||||
uploadResponse.artifactItems = uploadSpecification.map(
|
||||
item => item.absoluteFilePath
|
||||
)
|
||||
uploadResponse.size = uploadResult.uploadSize
|
||||
uploadResponse.failedItems = uploadResult.failedItems
|
||||
}
|
||||
return uploadResponse
|
||||
}
|
||||
|
||||
async downloadArtifact(
|
||||
name: string,
|
||||
path?: string | undefined,
|
||||
options?: DownloadOptions | undefined
|
||||
): Promise<DownloadResponse> {
|
||||
const downloadHttpClient = new DownloadHttpClient()
|
||||
|
||||
const artifacts = await downloadHttpClient.listArtifacts()
|
||||
if (artifacts.count === 0) {
|
||||
throw new Error(
|
||||
`Unable to find any artifacts for the associated workflow`
|
||||
)
|
||||
}
|
||||
|
||||
const artifactToDownload = artifacts.value.find(artifact => {
|
||||
return artifact.name === name
|
||||
})
|
||||
if (!artifactToDownload) {
|
||||
throw new Error(`Unable to find an artifact with the name: ${name}`)
|
||||
}
|
||||
|
||||
const items = await downloadHttpClient.getContainerItems(
|
||||
artifactToDownload.name,
|
||||
artifactToDownload.fileContainerResourceUrl
|
||||
)
|
||||
|
||||
if (!path) {
|
||||
path = getWorkSpaceDirectory()
|
||||
}
|
||||
path = normalize(path)
|
||||
path = resolve(path)
|
||||
|
||||
// During upload, empty directories are rejected by the remote server so there should be no artifacts that consist of only empty directories
|
||||
const downloadSpecification = getDownloadSpecification(
|
||||
name,
|
||||
items.value,
|
||||
path,
|
||||
options?.createArtifactFolder || false
|
||||
)
|
||||
|
||||
if (downloadSpecification.filesToDownload.length === 0) {
|
||||
core.info(
|
||||
`No downloadable files were found for the artifact: ${artifactToDownload.name}`
|
||||
)
|
||||
} else {
|
||||
// Create all necessary directories recursively before starting any download
|
||||
await createDirectoriesForArtifact(
|
||||
downloadSpecification.directoryStructure
|
||||
)
|
||||
core.info('Directory structure has been set up for the artifact')
|
||||
await createEmptyFilesForArtifact(
|
||||
downloadSpecification.emptyFilesToCreate
|
||||
)
|
||||
await downloadHttpClient.downloadSingleArtifact(
|
||||
downloadSpecification.filesToDownload
|
||||
)
|
||||
}
|
||||
|
||||
return {
|
||||
artifactName: name,
|
||||
downloadPath: downloadSpecification.rootDownloadLocation
|
||||
}
|
||||
}
|
||||
|
||||
async downloadAllArtifacts(
|
||||
path?: string | undefined
|
||||
): Promise<DownloadResponse[]> {
|
||||
const downloadHttpClient = new DownloadHttpClient()
|
||||
|
||||
const response: DownloadResponse[] = []
|
||||
const artifacts = await downloadHttpClient.listArtifacts()
|
||||
if (artifacts.count === 0) {
|
||||
core.info('Unable to find any artifacts for the associated workflow')
|
||||
return response
|
||||
}
|
||||
|
||||
if (!path) {
|
||||
path = getWorkSpaceDirectory()
|
||||
}
|
||||
path = normalize(path)
|
||||
path = resolve(path)
|
||||
|
||||
let downloadedArtifacts = 0
|
||||
while (downloadedArtifacts < artifacts.count) {
|
||||
const currentArtifactToDownload = artifacts.value[downloadedArtifacts]
|
||||
downloadedArtifacts += 1
|
||||
core.info(
|
||||
`starting download of artifact ${currentArtifactToDownload.name} : ${downloadedArtifacts}/${artifacts.count}`
|
||||
)
|
||||
|
||||
// Get container entries for the specific artifact
|
||||
const items = await downloadHttpClient.getContainerItems(
|
||||
currentArtifactToDownload.name,
|
||||
currentArtifactToDownload.fileContainerResourceUrl
|
||||
)
|
||||
|
||||
const downloadSpecification = getDownloadSpecification(
|
||||
currentArtifactToDownload.name,
|
||||
items.value,
|
||||
path,
|
||||
true
|
||||
)
|
||||
if (downloadSpecification.filesToDownload.length === 0) {
|
||||
core.info(
|
||||
`No downloadable files were found for any artifact ${currentArtifactToDownload.name}`
|
||||
)
|
||||
} else {
|
||||
await createDirectoriesForArtifact(
|
||||
downloadSpecification.directoryStructure
|
||||
)
|
||||
await createEmptyFilesForArtifact(
|
||||
downloadSpecification.emptyFilesToCreate
|
||||
)
|
||||
await downloadHttpClient.downloadSingleArtifact(
|
||||
downloadSpecification.filesToDownload
|
||||
)
|
||||
}
|
||||
|
||||
response.push({
|
||||
artifactName: currentArtifactToDownload.name,
|
||||
downloadPath: downloadSpecification.rootDownloadLocation
|
||||
})
|
||||
}
|
||||
return response
|
||||
}
|
||||
}
|
||||
@@ -1,67 +0,0 @@
|
||||
// The number of concurrent uploads that happens at the same time
|
||||
export function getUploadFileConcurrency(): number {
|
||||
return 2
|
||||
}
|
||||
|
||||
// When uploading large files that can't be uploaded with a single http call, this controls
|
||||
// the chunk size that is used during upload
|
||||
export function getUploadChunkSize(): number {
|
||||
return 8 * 1024 * 1024 // 8 MB Chunks
|
||||
}
|
||||
|
||||
// The maximum number of retries that can be attempted before an upload or download fails
|
||||
export function getRetryLimit(): number {
|
||||
return 5
|
||||
}
|
||||
|
||||
// With exponential backoff, the larger the retry count, the larger the wait time before another attempt
|
||||
// The retry multiplier controls by how much the backOff time increases depending on the number of retries
|
||||
export function getRetryMultiplier(): number {
|
||||
return 1.5
|
||||
}
|
||||
|
||||
// The initial wait time if an upload or download fails and a retry is being attempted for the first time
|
||||
export function getInitialRetryIntervalInMilliseconds(): number {
|
||||
return 3000
|
||||
}
|
||||
|
||||
// The number of concurrent downloads that happens at the same time
|
||||
export function getDownloadFileConcurrency(): number {
|
||||
return 2
|
||||
}
|
||||
|
||||
export function getRuntimeToken(): string {
|
||||
const token = process.env['ACTIONS_RUNTIME_TOKEN']
|
||||
if (!token) {
|
||||
throw new Error('Unable to get ACTIONS_RUNTIME_TOKEN env variable')
|
||||
}
|
||||
return token
|
||||
}
|
||||
|
||||
export function getRuntimeUrl(): string {
|
||||
const runtimeUrl = process.env['ACTIONS_RUNTIME_URL']
|
||||
if (!runtimeUrl) {
|
||||
throw new Error('Unable to get ACTIONS_RUNTIME_URL env variable')
|
||||
}
|
||||
return runtimeUrl
|
||||
}
|
||||
|
||||
export function getWorkFlowRunId(): string {
|
||||
const workFlowRunId = process.env['GITHUB_RUN_ID']
|
||||
if (!workFlowRunId) {
|
||||
throw new Error('Unable to get GITHUB_RUN_ID env variable')
|
||||
}
|
||||
return workFlowRunId
|
||||
}
|
||||
|
||||
export function getWorkSpaceDirectory(): string {
|
||||
const workspaceDirectory = process.env['GITHUB_WORKSPACE']
|
||||
if (!workspaceDirectory) {
|
||||
throw new Error('Unable to get GITHUB_WORKSPACE env variable')
|
||||
}
|
||||
return workspaceDirectory
|
||||
}
|
||||
|
||||
export function getRetentionDays(): string | undefined {
|
||||
return process.env['GITHUB_RETENTION_DAYS']
|
||||
}
|
||||
@@ -1,76 +0,0 @@
|
||||
export interface ArtifactResponse {
|
||||
containerId: string
|
||||
size: number
|
||||
signedContent: string
|
||||
fileContainerResourceUrl: string
|
||||
type: string
|
||||
name: string
|
||||
url: string
|
||||
}
|
||||
|
||||
export interface CreateArtifactParameters {
|
||||
Type: string
|
||||
Name: string
|
||||
RetentionDays?: number
|
||||
}
|
||||
|
||||
export interface PatchArtifactSize {
|
||||
Size: number
|
||||
}
|
||||
|
||||
export interface PatchArtifactSizeSuccessResponse {
|
||||
containerId: number
|
||||
size: number
|
||||
signedContent: string
|
||||
type: string
|
||||
name: string
|
||||
url: string
|
||||
uploadUrl: string
|
||||
}
|
||||
|
||||
export interface UploadResults {
|
||||
/**
|
||||
* The size in bytes of data that was transferred during the upload process to the actions backend service. This takes into account possible
|
||||
* gzip compression to reduce the amount of data that needs to be transferred
|
||||
*/
|
||||
uploadSize: number
|
||||
|
||||
/**
|
||||
* The raw size of the files that were specified for upload
|
||||
*/
|
||||
totalSize: number
|
||||
|
||||
/**
|
||||
* An array of files that failed to upload
|
||||
*/
|
||||
failedItems: string[]
|
||||
}
|
||||
|
||||
export interface ListArtifactsResponse {
|
||||
count: number
|
||||
value: ArtifactResponse[]
|
||||
}
|
||||
|
||||
export interface QueryArtifactResponse {
|
||||
count: number
|
||||
value: ContainerEntry[]
|
||||
}
|
||||
|
||||
export interface ContainerEntry {
|
||||
containerId: number
|
||||
scopeIdentifier: string
|
||||
path: string
|
||||
itemType: string
|
||||
status: string
|
||||
fileLength?: number
|
||||
fileEncoding?: number
|
||||
fileType?: number
|
||||
dateCreated: string
|
||||
dateLastModified: string
|
||||
createdBy: string
|
||||
lastModifiedBy: string
|
||||
itemLocation: string
|
||||
contentLocation: string
|
||||
fileId?: number
|
||||
contentId: string
|
||||
}
|
||||
@@ -1,317 +0,0 @@
|
||||
/**
|
||||
* CRC64: cyclic redundancy check, 64-bits
|
||||
*
|
||||
* In order to validate that artifacts are not being corrupted over the wire, this redundancy check allows us to
|
||||
* validate that there was no corruption during transmission. The implementation here is based on Go's hash/crc64 pkg,
|
||||
* but without the slicing-by-8 optimization: https://cs.opensource.google/go/go/+/master:src/hash/crc64/crc64.go
|
||||
*
|
||||
* This implementation uses a pregenerated table based on 0x9A6C9329AC4BC9B5 as the polynomial, the same polynomial that
|
||||
* is used for Azure Storage: https://github.com/Azure/azure-storage-net/blob/cbe605f9faa01bfc3003d75fc5a16b2eaccfe102/Lib/Common/Core/Util/Crc64.cs#L27
|
||||
*/
|
||||
|
||||
// when transpile target is >= ES2020 (after dropping node 12) these can be changed to bigint literals - ts(2737)
|
||||
const PREGEN_POLY_TABLE = [
|
||||
BigInt('0x0000000000000000'),
|
||||
BigInt('0x7F6EF0C830358979'),
|
||||
BigInt('0xFEDDE190606B12F2'),
|
||||
BigInt('0x81B31158505E9B8B'),
|
||||
BigInt('0xC962E5739841B68F'),
|
||||
BigInt('0xB60C15BBA8743FF6'),
|
||||
BigInt('0x37BF04E3F82AA47D'),
|
||||
BigInt('0x48D1F42BC81F2D04'),
|
||||
BigInt('0xA61CECB46814FE75'),
|
||||
BigInt('0xD9721C7C5821770C'),
|
||||
BigInt('0x58C10D24087FEC87'),
|
||||
BigInt('0x27AFFDEC384A65FE'),
|
||||
BigInt('0x6F7E09C7F05548FA'),
|
||||
BigInt('0x1010F90FC060C183'),
|
||||
BigInt('0x91A3E857903E5A08'),
|
||||
BigInt('0xEECD189FA00BD371'),
|
||||
BigInt('0x78E0FF3B88BE6F81'),
|
||||
BigInt('0x078E0FF3B88BE6F8'),
|
||||
BigInt('0x863D1EABE8D57D73'),
|
||||
BigInt('0xF953EE63D8E0F40A'),
|
||||
BigInt('0xB1821A4810FFD90E'),
|
||||
BigInt('0xCEECEA8020CA5077'),
|
||||
BigInt('0x4F5FFBD87094CBFC'),
|
||||
BigInt('0x30310B1040A14285'),
|
||||
BigInt('0xDEFC138FE0AA91F4'),
|
||||
BigInt('0xA192E347D09F188D'),
|
||||
BigInt('0x2021F21F80C18306'),
|
||||
BigInt('0x5F4F02D7B0F40A7F'),
|
||||
BigInt('0x179EF6FC78EB277B'),
|
||||
BigInt('0x68F0063448DEAE02'),
|
||||
BigInt('0xE943176C18803589'),
|
||||
BigInt('0x962DE7A428B5BCF0'),
|
||||
BigInt('0xF1C1FE77117CDF02'),
|
||||
BigInt('0x8EAF0EBF2149567B'),
|
||||
BigInt('0x0F1C1FE77117CDF0'),
|
||||
BigInt('0x7072EF2F41224489'),
|
||||
BigInt('0x38A31B04893D698D'),
|
||||
BigInt('0x47CDEBCCB908E0F4'),
|
||||
BigInt('0xC67EFA94E9567B7F'),
|
||||
BigInt('0xB9100A5CD963F206'),
|
||||
BigInt('0x57DD12C379682177'),
|
||||
BigInt('0x28B3E20B495DA80E'),
|
||||
BigInt('0xA900F35319033385'),
|
||||
BigInt('0xD66E039B2936BAFC'),
|
||||
BigInt('0x9EBFF7B0E12997F8'),
|
||||
BigInt('0xE1D10778D11C1E81'),
|
||||
BigInt('0x606216208142850A'),
|
||||
BigInt('0x1F0CE6E8B1770C73'),
|
||||
BigInt('0x8921014C99C2B083'),
|
||||
BigInt('0xF64FF184A9F739FA'),
|
||||
BigInt('0x77FCE0DCF9A9A271'),
|
||||
BigInt('0x08921014C99C2B08'),
|
||||
BigInt('0x4043E43F0183060C'),
|
||||
BigInt('0x3F2D14F731B68F75'),
|
||||
BigInt('0xBE9E05AF61E814FE'),
|
||||
BigInt('0xC1F0F56751DD9D87'),
|
||||
BigInt('0x2F3DEDF8F1D64EF6'),
|
||||
BigInt('0x50531D30C1E3C78F'),
|
||||
BigInt('0xD1E00C6891BD5C04'),
|
||||
BigInt('0xAE8EFCA0A188D57D'),
|
||||
BigInt('0xE65F088B6997F879'),
|
||||
BigInt('0x9931F84359A27100'),
|
||||
BigInt('0x1882E91B09FCEA8B'),
|
||||
BigInt('0x67EC19D339C963F2'),
|
||||
BigInt('0xD75ADABD7A6E2D6F'),
|
||||
BigInt('0xA8342A754A5BA416'),
|
||||
BigInt('0x29873B2D1A053F9D'),
|
||||
BigInt('0x56E9CBE52A30B6E4'),
|
||||
BigInt('0x1E383FCEE22F9BE0'),
|
||||
BigInt('0x6156CF06D21A1299'),
|
||||
BigInt('0xE0E5DE5E82448912'),
|
||||
BigInt('0x9F8B2E96B271006B'),
|
||||
BigInt('0x71463609127AD31A'),
|
||||
BigInt('0x0E28C6C1224F5A63'),
|
||||
BigInt('0x8F9BD7997211C1E8'),
|
||||
BigInt('0xF0F5275142244891'),
|
||||
BigInt('0xB824D37A8A3B6595'),
|
||||
BigInt('0xC74A23B2BA0EECEC'),
|
||||
BigInt('0x46F932EAEA507767'),
|
||||
BigInt('0x3997C222DA65FE1E'),
|
||||
BigInt('0xAFBA2586F2D042EE'),
|
||||
BigInt('0xD0D4D54EC2E5CB97'),
|
||||
BigInt('0x5167C41692BB501C'),
|
||||
BigInt('0x2E0934DEA28ED965'),
|
||||
BigInt('0x66D8C0F56A91F461'),
|
||||
BigInt('0x19B6303D5AA47D18'),
|
||||
BigInt('0x980521650AFAE693'),
|
||||
BigInt('0xE76BD1AD3ACF6FEA'),
|
||||
BigInt('0x09A6C9329AC4BC9B'),
|
||||
BigInt('0x76C839FAAAF135E2'),
|
||||
BigInt('0xF77B28A2FAAFAE69'),
|
||||
BigInt('0x8815D86ACA9A2710'),
|
||||
BigInt('0xC0C42C4102850A14'),
|
||||
BigInt('0xBFAADC8932B0836D'),
|
||||
BigInt('0x3E19CDD162EE18E6'),
|
||||
BigInt('0x41773D1952DB919F'),
|
||||
BigInt('0x269B24CA6B12F26D'),
|
||||
BigInt('0x59F5D4025B277B14'),
|
||||
BigInt('0xD846C55A0B79E09F'),
|
||||
BigInt('0xA72835923B4C69E6'),
|
||||
BigInt('0xEFF9C1B9F35344E2'),
|
||||
BigInt('0x90973171C366CD9B'),
|
||||
BigInt('0x1124202993385610'),
|
||||
BigInt('0x6E4AD0E1A30DDF69'),
|
||||
BigInt('0x8087C87E03060C18'),
|
||||
BigInt('0xFFE938B633338561'),
|
||||
BigInt('0x7E5A29EE636D1EEA'),
|
||||
BigInt('0x0134D92653589793'),
|
||||
BigInt('0x49E52D0D9B47BA97'),
|
||||
BigInt('0x368BDDC5AB7233EE'),
|
||||
BigInt('0xB738CC9DFB2CA865'),
|
||||
BigInt('0xC8563C55CB19211C'),
|
||||
BigInt('0x5E7BDBF1E3AC9DEC'),
|
||||
BigInt('0x21152B39D3991495'),
|
||||
BigInt('0xA0A63A6183C78F1E'),
|
||||
BigInt('0xDFC8CAA9B3F20667'),
|
||||
BigInt('0x97193E827BED2B63'),
|
||||
BigInt('0xE877CE4A4BD8A21A'),
|
||||
BigInt('0x69C4DF121B863991'),
|
||||
BigInt('0x16AA2FDA2BB3B0E8'),
|
||||
BigInt('0xF86737458BB86399'),
|
||||
BigInt('0x8709C78DBB8DEAE0'),
|
||||
BigInt('0x06BAD6D5EBD3716B'),
|
||||
BigInt('0x79D4261DDBE6F812'),
|
||||
BigInt('0x3105D23613F9D516'),
|
||||
BigInt('0x4E6B22FE23CC5C6F'),
|
||||
BigInt('0xCFD833A67392C7E4'),
|
||||
BigInt('0xB0B6C36E43A74E9D'),
|
||||
BigInt('0x9A6C9329AC4BC9B5'),
|
||||
BigInt('0xE50263E19C7E40CC'),
|
||||
BigInt('0x64B172B9CC20DB47'),
|
||||
BigInt('0x1BDF8271FC15523E'),
|
||||
BigInt('0x530E765A340A7F3A'),
|
||||
BigInt('0x2C608692043FF643'),
|
||||
BigInt('0xADD397CA54616DC8'),
|
||||
BigInt('0xD2BD67026454E4B1'),
|
||||
BigInt('0x3C707F9DC45F37C0'),
|
||||
BigInt('0x431E8F55F46ABEB9'),
|
||||
BigInt('0xC2AD9E0DA4342532'),
|
||||
BigInt('0xBDC36EC59401AC4B'),
|
||||
BigInt('0xF5129AEE5C1E814F'),
|
||||
BigInt('0x8A7C6A266C2B0836'),
|
||||
BigInt('0x0BCF7B7E3C7593BD'),
|
||||
BigInt('0x74A18BB60C401AC4'),
|
||||
BigInt('0xE28C6C1224F5A634'),
|
||||
BigInt('0x9DE29CDA14C02F4D'),
|
||||
BigInt('0x1C518D82449EB4C6'),
|
||||
BigInt('0x633F7D4A74AB3DBF'),
|
||||
BigInt('0x2BEE8961BCB410BB'),
|
||||
BigInt('0x548079A98C8199C2'),
|
||||
BigInt('0xD53368F1DCDF0249'),
|
||||
BigInt('0xAA5D9839ECEA8B30'),
|
||||
BigInt('0x449080A64CE15841'),
|
||||
BigInt('0x3BFE706E7CD4D138'),
|
||||
BigInt('0xBA4D61362C8A4AB3'),
|
||||
BigInt('0xC52391FE1CBFC3CA'),
|
||||
BigInt('0x8DF265D5D4A0EECE'),
|
||||
BigInt('0xF29C951DE49567B7'),
|
||||
BigInt('0x732F8445B4CBFC3C'),
|
||||
BigInt('0x0C41748D84FE7545'),
|
||||
BigInt('0x6BAD6D5EBD3716B7'),
|
||||
BigInt('0x14C39D968D029FCE'),
|
||||
BigInt('0x95708CCEDD5C0445'),
|
||||
BigInt('0xEA1E7C06ED698D3C'),
|
||||
BigInt('0xA2CF882D2576A038'),
|
||||
BigInt('0xDDA178E515432941'),
|
||||
BigInt('0x5C1269BD451DB2CA'),
|
||||
BigInt('0x237C997575283BB3'),
|
||||
BigInt('0xCDB181EAD523E8C2'),
|
||||
BigInt('0xB2DF7122E51661BB'),
|
||||
BigInt('0x336C607AB548FA30'),
|
||||
BigInt('0x4C0290B2857D7349'),
|
||||
BigInt('0x04D364994D625E4D'),
|
||||
BigInt('0x7BBD94517D57D734'),
|
||||
BigInt('0xFA0E85092D094CBF'),
|
||||
BigInt('0x856075C11D3CC5C6'),
|
||||
BigInt('0x134D926535897936'),
|
||||
BigInt('0x6C2362AD05BCF04F'),
|
||||
BigInt('0xED9073F555E26BC4'),
|
||||
BigInt('0x92FE833D65D7E2BD'),
|
||||
BigInt('0xDA2F7716ADC8CFB9'),
|
||||
BigInt('0xA54187DE9DFD46C0'),
|
||||
BigInt('0x24F29686CDA3DD4B'),
|
||||
BigInt('0x5B9C664EFD965432'),
|
||||
BigInt('0xB5517ED15D9D8743'),
|
||||
BigInt('0xCA3F8E196DA80E3A'),
|
||||
BigInt('0x4B8C9F413DF695B1'),
|
||||
BigInt('0x34E26F890DC31CC8'),
|
||||
BigInt('0x7C339BA2C5DC31CC'),
|
||||
BigInt('0x035D6B6AF5E9B8B5'),
|
||||
BigInt('0x82EE7A32A5B7233E'),
|
||||
BigInt('0xFD808AFA9582AA47'),
|
||||
BigInt('0x4D364994D625E4DA'),
|
||||
BigInt('0x3258B95CE6106DA3'),
|
||||
BigInt('0xB3EBA804B64EF628'),
|
||||
BigInt('0xCC8558CC867B7F51'),
|
||||
BigInt('0x8454ACE74E645255'),
|
||||
BigInt('0xFB3A5C2F7E51DB2C'),
|
||||
BigInt('0x7A894D772E0F40A7'),
|
||||
BigInt('0x05E7BDBF1E3AC9DE'),
|
||||
BigInt('0xEB2AA520BE311AAF'),
|
||||
BigInt('0x944455E88E0493D6'),
|
||||
BigInt('0x15F744B0DE5A085D'),
|
||||
BigInt('0x6A99B478EE6F8124'),
|
||||
BigInt('0x224840532670AC20'),
|
||||
BigInt('0x5D26B09B16452559'),
|
||||
BigInt('0xDC95A1C3461BBED2'),
|
||||
BigInt('0xA3FB510B762E37AB'),
|
||||
BigInt('0x35D6B6AF5E9B8B5B'),
|
||||
BigInt('0x4AB846676EAE0222'),
|
||||
BigInt('0xCB0B573F3EF099A9'),
|
||||
BigInt('0xB465A7F70EC510D0'),
|
||||
BigInt('0xFCB453DCC6DA3DD4'),
|
||||
BigInt('0x83DAA314F6EFB4AD'),
|
||||
BigInt('0x0269B24CA6B12F26'),
|
||||
BigInt('0x7D0742849684A65F'),
|
||||
BigInt('0x93CA5A1B368F752E'),
|
||||
BigInt('0xECA4AAD306BAFC57'),
|
||||
BigInt('0x6D17BB8B56E467DC'),
|
||||
BigInt('0x12794B4366D1EEA5'),
|
||||
BigInt('0x5AA8BF68AECEC3A1'),
|
||||
BigInt('0x25C64FA09EFB4AD8'),
|
||||
BigInt('0xA4755EF8CEA5D153'),
|
||||
BigInt('0xDB1BAE30FE90582A'),
|
||||
BigInt('0xBCF7B7E3C7593BD8'),
|
||||
BigInt('0xC399472BF76CB2A1'),
|
||||
BigInt('0x422A5673A732292A'),
|
||||
BigInt('0x3D44A6BB9707A053'),
|
||||
BigInt('0x759552905F188D57'),
|
||||
BigInt('0x0AFBA2586F2D042E'),
|
||||
BigInt('0x8B48B3003F739FA5'),
|
||||
BigInt('0xF42643C80F4616DC'),
|
||||
BigInt('0x1AEB5B57AF4DC5AD'),
|
||||
BigInt('0x6585AB9F9F784CD4'),
|
||||
BigInt('0xE436BAC7CF26D75F'),
|
||||
BigInt('0x9B584A0FFF135E26'),
|
||||
BigInt('0xD389BE24370C7322'),
|
||||
BigInt('0xACE74EEC0739FA5B'),
|
||||
BigInt('0x2D545FB4576761D0'),
|
||||
BigInt('0x523AAF7C6752E8A9'),
|
||||
BigInt('0xC41748D84FE75459'),
|
||||
BigInt('0xBB79B8107FD2DD20'),
|
||||
BigInt('0x3ACAA9482F8C46AB'),
|
||||
BigInt('0x45A459801FB9CFD2'),
|
||||
BigInt('0x0D75ADABD7A6E2D6'),
|
||||
BigInt('0x721B5D63E7936BAF'),
|
||||
BigInt('0xF3A84C3BB7CDF024'),
|
||||
BigInt('0x8CC6BCF387F8795D'),
|
||||
BigInt('0x620BA46C27F3AA2C'),
|
||||
BigInt('0x1D6554A417C62355'),
|
||||
BigInt('0x9CD645FC4798B8DE'),
|
||||
BigInt('0xE3B8B53477AD31A7'),
|
||||
BigInt('0xAB69411FBFB21CA3'),
|
||||
BigInt('0xD407B1D78F8795DA'),
|
||||
BigInt('0x55B4A08FDFD90E51'),
|
||||
BigInt('0x2ADA5047EFEC8728')
|
||||
]
|
||||
|
||||
export type CRC64DigestEncoding = 'hex' | 'base64' | 'buffer'
|
||||
|
||||
class CRC64 {
|
||||
private _crc: bigint
|
||||
|
||||
constructor() {
|
||||
this._crc = BigInt(0)
|
||||
}
|
||||
|
||||
update(data: Buffer | string): void {
|
||||
const buffer = typeof data === 'string' ? Buffer.from(data) : data
|
||||
let crc = CRC64.flip64Bits(this._crc)
|
||||
|
||||
for (const dataByte of buffer) {
|
||||
const crcByte = Number(crc & BigInt(0xff))
|
||||
crc = PREGEN_POLY_TABLE[crcByte ^ dataByte] ^ (crc >> BigInt(8))
|
||||
}
|
||||
|
||||
this._crc = CRC64.flip64Bits(crc)
|
||||
}
|
||||
|
||||
digest(encoding?: CRC64DigestEncoding): string | Buffer {
|
||||
switch (encoding) {
|
||||
case 'hex':
|
||||
return this._crc.toString(16).toUpperCase()
|
||||
case 'base64':
|
||||
return this.toBuffer().toString('base64')
|
||||
default:
|
||||
return this.toBuffer()
|
||||
}
|
||||
}
|
||||
|
||||
private toBuffer(): Buffer {
|
||||
return Buffer.from(
|
||||
[0, 8, 16, 24, 32, 40, 48, 56].map(s =>
|
||||
Number((this._crc >> BigInt(s)) & BigInt(0xff))
|
||||
)
|
||||
)
|
||||
}
|
||||
|
||||
static flip64Bits(n: bigint): bigint {
|
||||
return (BigInt(1) << BigInt(64)) - BigInt(1) - n
|
||||
}
|
||||
}
|
||||
|
||||
export default CRC64
|
||||
@@ -1,362 +0,0 @@
|
||||
import * as fs from 'fs'
|
||||
import * as core from '@actions/core'
|
||||
import * as zlib from 'zlib'
|
||||
import {
|
||||
getArtifactUrl,
|
||||
getDownloadHeaders,
|
||||
isSuccessStatusCode,
|
||||
isRetryableStatusCode,
|
||||
isThrottledStatusCode,
|
||||
getExponentialRetryTimeInMilliseconds,
|
||||
tryGetRetryAfterValueTimeInMilliseconds,
|
||||
displayHttpDiagnostics,
|
||||
getFileSize,
|
||||
rmFile,
|
||||
sleep
|
||||
} from './utils'
|
||||
import {URL} from 'url'
|
||||
import {StatusReporter} from './status-reporter'
|
||||
import {performance} from 'perf_hooks'
|
||||
import {ListArtifactsResponse, QueryArtifactResponse} from './contracts'
|
||||
import {HttpClientResponse} from '@actions/http-client'
|
||||
import {HttpManager} from './http-manager'
|
||||
import {DownloadItem} from './download-specification'
|
||||
import {getDownloadFileConcurrency, getRetryLimit} from './config-variables'
|
||||
import {IncomingHttpHeaders} from 'http'
|
||||
import {retryHttpClientRequest} from './requestUtils'
|
||||
|
||||
export class DownloadHttpClient {
|
||||
// http manager is used for concurrent connections when downloading multiple files at once
|
||||
private downloadHttpManager: HttpManager
|
||||
private statusReporter: StatusReporter
|
||||
|
||||
constructor() {
|
||||
this.downloadHttpManager = new HttpManager(
|
||||
getDownloadFileConcurrency(),
|
||||
'@actions/artifact-download'
|
||||
)
|
||||
// downloads are usually significantly faster than uploads so display status information every second
|
||||
this.statusReporter = new StatusReporter(1000)
|
||||
}
|
||||
|
||||
/**
|
||||
* Gets a list of all artifacts that are in a specific container
|
||||
*/
|
||||
async listArtifacts(): Promise<ListArtifactsResponse> {
|
||||
const artifactUrl = getArtifactUrl()
|
||||
|
||||
// use the first client from the httpManager, `keep-alive` is not used so the connection will close immediately
|
||||
const client = this.downloadHttpManager.getClient(0)
|
||||
const headers = getDownloadHeaders('application/json')
|
||||
const response = await retryHttpClientRequest('List Artifacts', async () =>
|
||||
client.get(artifactUrl, headers)
|
||||
)
|
||||
const body: string = await response.readBody()
|
||||
return JSON.parse(body)
|
||||
}
|
||||
|
||||
/**
|
||||
* Fetches a set of container items that describe the contents of an artifact
|
||||
* @param artifactName the name of the artifact
|
||||
* @param containerUrl the artifact container URL for the run
|
||||
*/
|
||||
async getContainerItems(
|
||||
artifactName: string,
|
||||
containerUrl: string
|
||||
): Promise<QueryArtifactResponse> {
|
||||
// the itemPath search parameter controls which containers will be returned
|
||||
const resourceUrl = new URL(containerUrl)
|
||||
resourceUrl.searchParams.append('itemPath', artifactName)
|
||||
|
||||
// use the first client from the httpManager, `keep-alive` is not used so the connection will close immediately
|
||||
const client = this.downloadHttpManager.getClient(0)
|
||||
const headers = getDownloadHeaders('application/json')
|
||||
const response = await retryHttpClientRequest(
|
||||
'Get Container Items',
|
||||
async () => client.get(resourceUrl.toString(), headers)
|
||||
)
|
||||
const body: string = await response.readBody()
|
||||
return JSON.parse(body)
|
||||
}
|
||||
|
||||
/**
|
||||
* Concurrently downloads all the files that are part of an artifact
|
||||
* @param downloadItems information about what items to download and where to save them
|
||||
*/
|
||||
async downloadSingleArtifact(downloadItems: DownloadItem[]): Promise<void> {
|
||||
const DOWNLOAD_CONCURRENCY = getDownloadFileConcurrency()
|
||||
// limit the number of files downloaded at a single time
|
||||
core.debug(`Download file concurrency is set to ${DOWNLOAD_CONCURRENCY}`)
|
||||
const parallelDownloads = [...new Array(DOWNLOAD_CONCURRENCY).keys()]
|
||||
let currentFile = 0
|
||||
let downloadedFiles = 0
|
||||
|
||||
core.info(
|
||||
`Total number of files that will be downloaded: ${downloadItems.length}`
|
||||
)
|
||||
|
||||
this.statusReporter.setTotalNumberOfFilesToProcess(downloadItems.length)
|
||||
this.statusReporter.start()
|
||||
|
||||
await Promise.all(
|
||||
parallelDownloads.map(async index => {
|
||||
while (currentFile < downloadItems.length) {
|
||||
const currentFileToDownload = downloadItems[currentFile]
|
||||
currentFile += 1
|
||||
|
||||
const startTime = performance.now()
|
||||
await this.downloadIndividualFile(
|
||||
index,
|
||||
currentFileToDownload.sourceLocation,
|
||||
currentFileToDownload.targetPath
|
||||
)
|
||||
|
||||
if (core.isDebug()) {
|
||||
core.debug(
|
||||
`File: ${++downloadedFiles}/${downloadItems.length}. ${
|
||||
currentFileToDownload.targetPath
|
||||
} took ${(performance.now() - startTime).toFixed(
|
||||
3
|
||||
)} milliseconds to finish downloading`
|
||||
)
|
||||
}
|
||||
|
||||
this.statusReporter.incrementProcessedCount()
|
||||
}
|
||||
})
|
||||
)
|
||||
.catch(error => {
|
||||
throw new Error(`Unable to download the artifact: ${error}`)
|
||||
})
|
||||
.finally(() => {
|
||||
this.statusReporter.stop()
|
||||
// safety dispose all connections
|
||||
this.downloadHttpManager.disposeAndReplaceAllClients()
|
||||
})
|
||||
}
|
||||
|
||||
/**
|
||||
* Downloads an individual file
|
||||
* @param httpClientIndex the index of the http client that is used to make all of the calls
|
||||
* @param artifactLocation origin location where a file will be downloaded from
|
||||
* @param downloadPath destination location for the file being downloaded
|
||||
*/
|
||||
private async downloadIndividualFile(
|
||||
httpClientIndex: number,
|
||||
artifactLocation: string,
|
||||
downloadPath: string
|
||||
): Promise<void> {
|
||||
let retryCount = 0
|
||||
const retryLimit = getRetryLimit()
|
||||
let destinationStream = fs.createWriteStream(downloadPath)
|
||||
const headers = getDownloadHeaders('application/json', true, true)
|
||||
|
||||
// a single GET request is used to download a file
|
||||
const makeDownloadRequest = async (): Promise<HttpClientResponse> => {
|
||||
const client = this.downloadHttpManager.getClient(httpClientIndex)
|
||||
return await client.get(artifactLocation, headers)
|
||||
}
|
||||
|
||||
// check the response headers to determine if the file was compressed using gzip
|
||||
const isGzip = (incomingHeaders: IncomingHttpHeaders): boolean => {
|
||||
return (
|
||||
'content-encoding' in incomingHeaders &&
|
||||
incomingHeaders['content-encoding'] === 'gzip'
|
||||
)
|
||||
}
|
||||
|
||||
// Increments the current retry count and then checks if the retry limit has been reached
|
||||
// If there have been too many retries, fail so the download stops. If there is a retryAfterValue value provided,
|
||||
// it will be used
|
||||
const backOff = async (retryAfterValue?: number): Promise<void> => {
|
||||
retryCount++
|
||||
if (retryCount > retryLimit) {
|
||||
return Promise.reject(
|
||||
new Error(
|
||||
`Retry limit has been reached. Unable to download ${artifactLocation}`
|
||||
)
|
||||
)
|
||||
} else {
|
||||
this.downloadHttpManager.disposeAndReplaceClient(httpClientIndex)
|
||||
if (retryAfterValue) {
|
||||
// Back off by waiting the specified time denoted by the retry-after header
|
||||
core.info(
|
||||
`Backoff due to too many requests, retry #${retryCount}. Waiting for ${retryAfterValue} milliseconds before continuing the download`
|
||||
)
|
||||
await sleep(retryAfterValue)
|
||||
} else {
|
||||
// Back off using an exponential value that depends on the retry count
|
||||
const backoffTime = getExponentialRetryTimeInMilliseconds(retryCount)
|
||||
core.info(
|
||||
`Exponential backoff for retry #${retryCount}. Waiting for ${backoffTime} milliseconds before continuing the download`
|
||||
)
|
||||
await sleep(backoffTime)
|
||||
}
|
||||
core.info(
|
||||
`Finished backoff for retry #${retryCount}, continuing with download`
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
const isAllBytesReceived = (
|
||||
expected?: string,
|
||||
received?: number
|
||||
): boolean => {
|
||||
// be lenient, if any input is missing, assume success, i.e. not truncated
|
||||
if (
|
||||
!expected ||
|
||||
!received ||
|
||||
process.env['ACTIONS_ARTIFACT_SKIP_DOWNLOAD_VALIDATION']
|
||||
) {
|
||||
core.info('Skipping download validation.')
|
||||
return true
|
||||
}
|
||||
|
||||
return parseInt(expected) === received
|
||||
}
|
||||
|
||||
const resetDestinationStream = async (
|
||||
fileDownloadPath: string
|
||||
): Promise<void> => {
|
||||
destinationStream.close()
|
||||
// await until file is created at downloadpath; node15 and up fs.createWriteStream had not created a file yet
|
||||
await new Promise<void>(resolve => {
|
||||
destinationStream.on('close', resolve)
|
||||
if (destinationStream.writableFinished) {
|
||||
resolve()
|
||||
}
|
||||
})
|
||||
await rmFile(fileDownloadPath)
|
||||
destinationStream = fs.createWriteStream(fileDownloadPath)
|
||||
}
|
||||
|
||||
// keep trying to download a file until a retry limit has been reached
|
||||
while (retryCount <= retryLimit) {
|
||||
let response: HttpClientResponse
|
||||
try {
|
||||
response = await makeDownloadRequest()
|
||||
} catch (error) {
|
||||
// if an error is caught, it is usually indicative of a timeout so retry the download
|
||||
core.info('An error occurred while attempting to download a file')
|
||||
// eslint-disable-next-line no-console
|
||||
console.log(error)
|
||||
|
||||
// increment the retryCount and use exponential backoff to wait before making the next request
|
||||
await backOff()
|
||||
continue
|
||||
}
|
||||
|
||||
let forceRetry = false
|
||||
if (isSuccessStatusCode(response.message.statusCode)) {
|
||||
// The body contains the contents of the file however calling response.readBody() causes all the content to be converted to a string
|
||||
// which can cause some gzip encoded data to be lost
|
||||
// Instead of using response.readBody(), response.message is a readableStream that can be directly used to get the raw body contents
|
||||
try {
|
||||
const isGzipped = isGzip(response.message.headers)
|
||||
await this.pipeResponseToFile(response, destinationStream, isGzipped)
|
||||
|
||||
if (
|
||||
isGzipped ||
|
||||
isAllBytesReceived(
|
||||
response.message.headers['content-length'],
|
||||
await getFileSize(downloadPath)
|
||||
)
|
||||
) {
|
||||
return
|
||||
} else {
|
||||
forceRetry = true
|
||||
}
|
||||
} catch (error) {
|
||||
// retry on error, most likely streams were corrupted
|
||||
forceRetry = true
|
||||
}
|
||||
}
|
||||
|
||||
if (forceRetry || isRetryableStatusCode(response.message.statusCode)) {
|
||||
core.info(
|
||||
`A ${response.message.statusCode} response code has been received while attempting to download an artifact`
|
||||
)
|
||||
resetDestinationStream(downloadPath)
|
||||
// if a throttled status code is received, try to get the retryAfter header value, else differ to standard exponential backoff
|
||||
isThrottledStatusCode(response.message.statusCode)
|
||||
? await backOff(
|
||||
tryGetRetryAfterValueTimeInMilliseconds(response.message.headers)
|
||||
)
|
||||
: await backOff()
|
||||
} else {
|
||||
// Some unexpected response code, fail immediately and stop the download
|
||||
displayHttpDiagnostics(response)
|
||||
return Promise.reject(
|
||||
new Error(
|
||||
`Unexpected http ${response.message.statusCode} during download for ${artifactLocation}`
|
||||
)
|
||||
)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Pipes the response from downloading an individual file to the appropriate destination stream while decoding gzip content if necessary
|
||||
* @param response the http response received when downloading a file
|
||||
* @param destinationStream the stream where the file should be written to
|
||||
* @param isGzip a boolean denoting if the content is compressed using gzip and if we need to decode it
|
||||
*/
|
||||
async pipeResponseToFile(
|
||||
response: HttpClientResponse,
|
||||
destinationStream: fs.WriteStream,
|
||||
isGzip: boolean
|
||||
): Promise<void> {
|
||||
await new Promise((resolve, reject) => {
|
||||
if (isGzip) {
|
||||
const gunzip = zlib.createGunzip()
|
||||
response.message
|
||||
.on('error', error => {
|
||||
core.info(
|
||||
`An error occurred while attempting to read the response stream`
|
||||
)
|
||||
gunzip.close()
|
||||
destinationStream.close()
|
||||
reject(error)
|
||||
})
|
||||
.pipe(gunzip)
|
||||
.on('error', error => {
|
||||
core.info(
|
||||
`An error occurred while attempting to decompress the response stream`
|
||||
)
|
||||
destinationStream.close()
|
||||
reject(error)
|
||||
})
|
||||
.pipe(destinationStream)
|
||||
.on('close', () => {
|
||||
resolve()
|
||||
})
|
||||
.on('error', error => {
|
||||
core.info(
|
||||
`An error occurred while writing a downloaded file to ${destinationStream.path}`
|
||||
)
|
||||
reject(error)
|
||||
})
|
||||
} else {
|
||||
response.message
|
||||
.on('error', error => {
|
||||
core.info(
|
||||
`An error occurred while attempting to read the response stream`
|
||||
)
|
||||
destinationStream.close()
|
||||
reject(error)
|
||||
})
|
||||
.pipe(destinationStream)
|
||||
.on('close', () => {
|
||||
resolve()
|
||||
})
|
||||
.on('error', error => {
|
||||
core.info(
|
||||
`An error occurred while writing a downloaded file to ${destinationStream.path}`
|
||||
)
|
||||
reject(error)
|
||||
})
|
||||
}
|
||||
})
|
||||
return
|
||||
}
|
||||
}
|
||||
@@ -1,7 +0,0 @@
|
||||
export interface DownloadOptions {
|
||||
/**
|
||||
* Specifies if a folder is created for the artifact that is downloaded (contents downloaded into this folder),
|
||||
* defaults to false if not specified
|
||||
* */
|
||||
createArtifactFolder?: boolean
|
||||
}
|
||||
@@ -1,11 +0,0 @@
|
||||
export interface DownloadResponse {
|
||||
/**
|
||||
* The name of the artifact that was downloaded
|
||||
*/
|
||||
artifactName: string
|
||||
|
||||
/**
|
||||
* The full Path to where the artifact was downloaded
|
||||
*/
|
||||
downloadPath: string
|
||||
}
|
||||
@@ -1,87 +0,0 @@
|
||||
import * as path from 'path'
|
||||
import {ContainerEntry} from './contracts'
|
||||
|
||||
export interface DownloadSpecification {
|
||||
// root download location for the artifact
|
||||
rootDownloadLocation: string
|
||||
|
||||
// directories that need to be created for all the items in the artifact
|
||||
directoryStructure: string[]
|
||||
|
||||
// empty files that are part of the artifact that don't require any downloading
|
||||
emptyFilesToCreate: string[]
|
||||
|
||||
// individual files that need to be downloaded as part of the artifact
|
||||
filesToDownload: DownloadItem[]
|
||||
}
|
||||
|
||||
export interface DownloadItem {
|
||||
// Url that denotes where to download the item from
|
||||
sourceLocation: string
|
||||
|
||||
// Information about where the file should be downloaded to
|
||||
targetPath: string
|
||||
}
|
||||
|
||||
/**
|
||||
* Creates a specification for a set of files that will be downloaded
|
||||
* @param artifactName the name of the artifact
|
||||
* @param artifactEntries a set of container entries that describe that files that make up an artifact
|
||||
* @param downloadPath the path where the artifact will be downloaded to
|
||||
* @param includeRootDirectory specifies if there should be an extra directory (denoted by the artifact name) where the artifact files should be downloaded to
|
||||
*/
|
||||
export function getDownloadSpecification(
|
||||
artifactName: string,
|
||||
artifactEntries: ContainerEntry[],
|
||||
downloadPath: string,
|
||||
includeRootDirectory: boolean
|
||||
): DownloadSpecification {
|
||||
// use a set for the directory paths so that there are no duplicates
|
||||
const directories = new Set<string>()
|
||||
|
||||
const specifications: DownloadSpecification = {
|
||||
rootDownloadLocation: includeRootDirectory
|
||||
? path.join(downloadPath, artifactName)
|
||||
: downloadPath,
|
||||
directoryStructure: [],
|
||||
emptyFilesToCreate: [],
|
||||
filesToDownload: []
|
||||
}
|
||||
|
||||
for (const entry of artifactEntries) {
|
||||
// Ignore artifacts in the container that don't begin with the same name
|
||||
if (
|
||||
entry.path.startsWith(`${artifactName}/`) ||
|
||||
entry.path.startsWith(`${artifactName}\\`)
|
||||
) {
|
||||
// normalize all separators to the local OS
|
||||
const normalizedPathEntry = path.normalize(entry.path)
|
||||
// entry.path always starts with the artifact name, if includeRootDirectory is false, remove the name from the beginning of the path
|
||||
const filePath = path.join(
|
||||
downloadPath,
|
||||
includeRootDirectory
|
||||
? normalizedPathEntry
|
||||
: normalizedPathEntry.replace(artifactName, '')
|
||||
)
|
||||
|
||||
// Case insensitive folder structure maintained in the backend, not every folder is created so the 'folder'
|
||||
// itemType cannot be relied upon. The file must be used to determine the directory structure
|
||||
if (entry.itemType === 'file') {
|
||||
// Get the directories that we need to create from the filePath for each individual file
|
||||
directories.add(path.dirname(filePath))
|
||||
if (entry.fileLength === 0) {
|
||||
// An empty file was uploaded, create the empty files locally so that no extra http calls are made
|
||||
specifications.emptyFilesToCreate.push(filePath)
|
||||
} else {
|
||||
specifications.filesToDownload.push({
|
||||
sourceLocation: entry.contentLocation,
|
||||
targetPath: filePath
|
||||
})
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
specifications.directoryStructure = Array.from(directories)
|
||||
return specifications
|
||||
}
|
||||
@@ -1,35 +0,0 @@
|
||||
import {HttpClient} from '@actions/http-client'
|
||||
import {createHttpClient} from './utils'
|
||||
|
||||
/**
|
||||
* Used for managing http clients during either upload or download
|
||||
*/
|
||||
export class HttpManager {
|
||||
private clients: HttpClient[]
|
||||
private userAgent: string
|
||||
|
||||
constructor(clientCount: number, userAgent: string) {
|
||||
if (clientCount < 1) {
|
||||
throw new Error('There must be at least one client')
|
||||
}
|
||||
this.userAgent = userAgent
|
||||
this.clients = new Array(clientCount).fill(createHttpClient(userAgent))
|
||||
}
|
||||
|
||||
getClient(index: number): HttpClient {
|
||||
return this.clients[index]
|
||||
}
|
||||
|
||||
// client disposal is necessary if a keep-alive connection is used to properly close the connection
|
||||
// for more information see: https://github.com/actions/http-client/blob/04e5ad73cd3fd1f5610a32116b0759eddf6570d2/index.ts#L292
|
||||
disposeAndReplaceClient(index: number): void {
|
||||
this.clients[index].dispose()
|
||||
this.clients[index] = createHttpClient(this.userAgent)
|
||||
}
|
||||
|
||||
disposeAndReplaceAllClients(): void {
|
||||
for (const [index] of this.clients.entries()) {
|
||||
this.disposeAndReplaceClient(index)
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -1,82 +0,0 @@
|
||||
import {info} from '@actions/core'
|
||||
|
||||
/**
|
||||
* Invalid characters that cannot be in the artifact name or an uploaded file. Will be rejected
|
||||
* from the server if attempted to be sent over. These characters are not allowed due to limitations with certain
|
||||
* file systems such as NTFS. To maintain platform-agnostic behavior, all characters that are not supported by an
|
||||
* individual filesystem/platform will not be supported on all fileSystems/platforms
|
||||
*
|
||||
* FilePaths can include characters such as \ and / which are not permitted in the artifact name alone
|
||||
*/
|
||||
const invalidArtifactFilePathCharacters = new Map<string, string>([
|
||||
['"', ' Double quote "'],
|
||||
[':', ' Colon :'],
|
||||
['<', ' Less than <'],
|
||||
['>', ' Greater than >'],
|
||||
['|', ' Vertical bar |'],
|
||||
['*', ' Asterisk *'],
|
||||
['?', ' Question mark ?'],
|
||||
['\r', ' Carriage return \\r'],
|
||||
['\n', ' Line feed \\n']
|
||||
])
|
||||
|
||||
const invalidArtifactNameCharacters = new Map<string, string>([
|
||||
...invalidArtifactFilePathCharacters,
|
||||
['\\', ' Backslash \\'],
|
||||
['/', ' Forward slash /']
|
||||
])
|
||||
|
||||
/**
|
||||
* Scans the name of the artifact to make sure there are no illegal characters
|
||||
*/
|
||||
export function checkArtifactName(name: string): void {
|
||||
if (!name) {
|
||||
throw new Error(`Artifact name: ${name}, is incorrectly provided`)
|
||||
}
|
||||
|
||||
for (const [
|
||||
invalidCharacterKey,
|
||||
errorMessageForCharacter
|
||||
] of invalidArtifactNameCharacters) {
|
||||
if (name.includes(invalidCharacterKey)) {
|
||||
throw new Error(
|
||||
`Artifact name is not valid: ${name}. Contains the following character: ${errorMessageForCharacter}
|
||||
|
||||
Invalid characters include: ${Array.from(
|
||||
invalidArtifactNameCharacters.values()
|
||||
).toString()}
|
||||
|
||||
These characters are not allowed in the artifact name due to limitations with certain file systems such as NTFS. To maintain file system agnostic behavior, these characters are intentionally not allowed to prevent potential problems with downloads on different file systems.`
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
info(`Artifact name is valid!`)
|
||||
}
|
||||
|
||||
/**
|
||||
* Scans the name of the filePath used to make sure there are no illegal characters
|
||||
*/
|
||||
export function checkArtifactFilePath(path: string): void {
|
||||
if (!path) {
|
||||
throw new Error(`Artifact path: ${path}, is incorrectly provided`)
|
||||
}
|
||||
|
||||
for (const [
|
||||
invalidCharacterKey,
|
||||
errorMessageForCharacter
|
||||
] of invalidArtifactFilePathCharacters) {
|
||||
if (path.includes(invalidCharacterKey)) {
|
||||
throw new Error(
|
||||
`Artifact path is not valid: ${path}. Contains the following character: ${errorMessageForCharacter}
|
||||
|
||||
Invalid characters include: ${Array.from(
|
||||
invalidArtifactFilePathCharacters.values()
|
||||
).toString()}
|
||||
|
||||
The following characters are not allowed in files that are uploaded due to limitations with certain file systems such as NTFS. To maintain file system agnostic behavior, these characters are intentionally not allowed to prevent potential problems with downloads on different file systems.
|
||||
`
|
||||
)
|
||||
}
|
||||
}
|
||||
}
|
||||
@@ -1,79 +0,0 @@
|
||||
import {HttpClientResponse} from '@actions/http-client'
|
||||
import {
|
||||
isRetryableStatusCode,
|
||||
isSuccessStatusCode,
|
||||
sleep,
|
||||
getExponentialRetryTimeInMilliseconds,
|
||||
displayHttpDiagnostics
|
||||
} from './utils'
|
||||
import * as core from '@actions/core'
|
||||
import {getRetryLimit} from './config-variables'
|
||||
|
||||
export async function retry(
|
||||
name: string,
|
||||
operation: () => Promise<HttpClientResponse>,
|
||||
customErrorMessages: Map<number, string>,
|
||||
maxAttempts: number
|
||||
): Promise<HttpClientResponse> {
|
||||
let response: HttpClientResponse | undefined = undefined
|
||||
let statusCode: number | undefined = undefined
|
||||
let isRetryable = false
|
||||
let errorMessage = ''
|
||||
let customErrorInformation: string | undefined = undefined
|
||||
let attempt = 1
|
||||
|
||||
while (attempt <= maxAttempts) {
|
||||
try {
|
||||
response = await operation()
|
||||
statusCode = response.message.statusCode
|
||||
|
||||
if (isSuccessStatusCode(statusCode)) {
|
||||
return response
|
||||
}
|
||||
|
||||
// Extra error information that we want to display if a particular response code is hit
|
||||
if (statusCode) {
|
||||
customErrorInformation = customErrorMessages.get(statusCode)
|
||||
}
|
||||
|
||||
isRetryable = isRetryableStatusCode(statusCode)
|
||||
errorMessage = `Artifact service responded with ${statusCode}`
|
||||
} catch (error) {
|
||||
isRetryable = true
|
||||
errorMessage = error.message
|
||||
}
|
||||
|
||||
if (!isRetryable) {
|
||||
core.info(`${name} - Error is not retryable`)
|
||||
if (response) {
|
||||
displayHttpDiagnostics(response)
|
||||
}
|
||||
break
|
||||
}
|
||||
|
||||
core.info(
|
||||
`${name} - Attempt ${attempt} of ${maxAttempts} failed with error: ${errorMessage}`
|
||||
)
|
||||
|
||||
await sleep(getExponentialRetryTimeInMilliseconds(attempt))
|
||||
attempt++
|
||||
}
|
||||
|
||||
if (response) {
|
||||
displayHttpDiagnostics(response)
|
||||
}
|
||||
|
||||
if (customErrorInformation) {
|
||||
throw Error(`${name} failed: ${customErrorInformation}`)
|
||||
}
|
||||
throw Error(`${name} failed: ${errorMessage}`)
|
||||
}
|
||||
|
||||
export async function retryHttpClientRequest(
|
||||
name: string,
|
||||
method: () => Promise<HttpClientResponse>,
|
||||
customErrorMessages: Map<number, string> = new Map(),
|
||||
maxAttempts = getRetryLimit()
|
||||
): Promise<HttpClientResponse> {
|
||||
return await retry(name, method, customErrorMessages, maxAttempts)
|
||||
}
|
||||
@@ -1,78 +0,0 @@
|
||||
import {info} from '@actions/core'
|
||||
|
||||
/**
|
||||
* Status Reporter that displays information about the progress/status of an artifact that is being uploaded or downloaded
|
||||
*
|
||||
* Variable display time that can be adjusted using the displayFrequencyInMilliseconds variable
|
||||
* The total status of the upload/download gets displayed according to this value
|
||||
* If there is a large file that is being uploaded, extra information about the individual status can also be displayed using the updateLargeFileStatus function
|
||||
*/
|
||||
|
||||
export class StatusReporter {
|
||||
private totalNumberOfFilesToProcess = 0
|
||||
private processedCount = 0
|
||||
private displayFrequencyInMilliseconds: number
|
||||
private largeFiles = new Map<string, string>()
|
||||
private totalFileStatus: NodeJS.Timeout | undefined
|
||||
|
||||
constructor(displayFrequencyInMilliseconds: number) {
|
||||
this.totalFileStatus = undefined
|
||||
this.displayFrequencyInMilliseconds = displayFrequencyInMilliseconds
|
||||
}
|
||||
|
||||
setTotalNumberOfFilesToProcess(fileTotal: number): void {
|
||||
this.totalNumberOfFilesToProcess = fileTotal
|
||||
this.processedCount = 0
|
||||
}
|
||||
|
||||
start(): void {
|
||||
// displays information about the total upload/download status
|
||||
this.totalFileStatus = setInterval(() => {
|
||||
// display 1 decimal place without any rounding
|
||||
const percentage = this.formatPercentage(
|
||||
this.processedCount,
|
||||
this.totalNumberOfFilesToProcess
|
||||
)
|
||||
info(
|
||||
`Total file count: ${
|
||||
this.totalNumberOfFilesToProcess
|
||||
} ---- Processed file #${this.processedCount} (${percentage.slice(
|
||||
0,
|
||||
percentage.indexOf('.') + 2
|
||||
)}%)`
|
||||
)
|
||||
}, this.displayFrequencyInMilliseconds)
|
||||
}
|
||||
|
||||
// if there is a large file that is being uploaded in chunks, this is used to display extra information about the status of the upload
|
||||
updateLargeFileStatus(
|
||||
fileName: string,
|
||||
chunkStartIndex: number,
|
||||
chunkEndIndex: number,
|
||||
totalUploadFileSize: number
|
||||
): void {
|
||||
// display 1 decimal place without any rounding
|
||||
const percentage = this.formatPercentage(chunkEndIndex, totalUploadFileSize)
|
||||
info(
|
||||
`Uploaded ${fileName} (${percentage.slice(
|
||||
0,
|
||||
percentage.indexOf('.') + 2
|
||||
)}%) bytes ${chunkStartIndex}:${chunkEndIndex}`
|
||||
)
|
||||
}
|
||||
|
||||
stop(): void {
|
||||
if (this.totalFileStatus) {
|
||||
clearInterval(this.totalFileStatus)
|
||||
}
|
||||
}
|
||||
|
||||
incrementProcessedCount(): void {
|
||||
this.processedCount++
|
||||
}
|
||||
|
||||
private formatPercentage(numerator: number, denominator: number): string {
|
||||
// toFixed() rounds, so use extra precision to display accurate information even though 4 decimal places are not displayed
|
||||
return ((numerator / denominator) * 100).toFixed(4).toString()
|
||||
}
|
||||
}
|
||||
@@ -1,89 +0,0 @@
|
||||
import * as fs from 'fs'
|
||||
import * as zlib from 'zlib'
|
||||
import {promisify} from 'util'
|
||||
const stat = promisify(fs.stat)
|
||||
|
||||
/**
|
||||
* GZipping certain files that are already compressed will likely not yield further size reductions. Creating large temporary gzip
|
||||
* files then will just waste a lot of time before ultimately being discarded (especially for very large files).
|
||||
* If any of these types of files are encountered then on-disk gzip creation will be skipped and the original file will be uploaded as-is
|
||||
*/
|
||||
const gzipExemptFileExtensions = [
|
||||
'.gz', // GZIP
|
||||
'.gzip', // GZIP
|
||||
'.tgz', // GZIP
|
||||
'.taz', // GZIP
|
||||
'.Z', // COMPRESS
|
||||
'.taZ', // COMPRESS
|
||||
'.bz2', // BZIP2
|
||||
'.tbz', // BZIP2
|
||||
'.tbz2', // BZIP2
|
||||
'.tz2', // BZIP2
|
||||
'.lz', // LZIP
|
||||
'.lzma', // LZMA
|
||||
'.tlz', // LZMA
|
||||
'.lzo', // LZOP
|
||||
'.xz', // XZ
|
||||
'.txz', // XZ
|
||||
'.zst', // ZSTD
|
||||
'.zstd', // ZSTD
|
||||
'.tzst', // ZSTD
|
||||
'.zip', // ZIP
|
||||
'.7z' // 7ZIP
|
||||
]
|
||||
|
||||
/**
|
||||
* Creates a Gzip compressed file of an original file at the provided temporary filepath location
|
||||
* @param {string} originalFilePath filepath of whatever will be compressed. The original file will be unmodified
|
||||
* @param {string} tempFilePath the location of where the Gzip file will be created
|
||||
* @returns the size of gzip file that gets created
|
||||
*/
|
||||
export async function createGZipFileOnDisk(
|
||||
originalFilePath: string,
|
||||
tempFilePath: string
|
||||
): Promise<number> {
|
||||
for (const gzipExemptExtension of gzipExemptFileExtensions) {
|
||||
if (originalFilePath.endsWith(gzipExemptExtension)) {
|
||||
// return a really large number so that the original file gets uploaded
|
||||
return Number.MAX_SAFE_INTEGER
|
||||
}
|
||||
}
|
||||
|
||||
return new Promise((resolve, reject) => {
|
||||
const inputStream = fs.createReadStream(originalFilePath)
|
||||
const gzip = zlib.createGzip()
|
||||
const outputStream = fs.createWriteStream(tempFilePath)
|
||||
inputStream.pipe(gzip).pipe(outputStream)
|
||||
outputStream.on('finish', async () => {
|
||||
// wait for stream to finish before calculating the size which is needed as part of the Content-Length header when starting an upload
|
||||
const size = (await stat(tempFilePath)).size
|
||||
resolve(size)
|
||||
})
|
||||
outputStream.on('error', error => {
|
||||
// eslint-disable-next-line no-console
|
||||
console.log(error)
|
||||
reject(error)
|
||||
})
|
||||
})
|
||||
}
|
||||
|
||||
/**
|
||||
* Creates a GZip file in memory using a buffer. Should be used for smaller files to reduce disk I/O
|
||||
* @param originalFilePath the path to the original file that is being GZipped
|
||||
* @returns a buffer with the GZip file
|
||||
*/
|
||||
export async function createGZipFileInBuffer(
|
||||
originalFilePath: string
|
||||
): Promise<Buffer> {
|
||||
return new Promise(async resolve => {
|
||||
const inputStream = fs.createReadStream(originalFilePath)
|
||||
const gzip = zlib.createGzip()
|
||||
inputStream.pipe(gzip)
|
||||
// read stream into buffer, using experimental async iterators see https://github.com/nodejs/readable-stream/issues/403#issuecomment-479069043
|
||||
const chunks = []
|
||||
for await (const chunk of gzip) {
|
||||
chunks.push(chunk)
|
||||
}
|
||||
resolve(Buffer.concat(chunks))
|
||||
})
|
||||
}
|
||||
@@ -1,567 +0,0 @@
|
||||
import * as fs from 'fs'
|
||||
import * as core from '@actions/core'
|
||||
import * as tmp from 'tmp-promise'
|
||||
import * as stream from 'stream'
|
||||
import {
|
||||
ArtifactResponse,
|
||||
CreateArtifactParameters,
|
||||
PatchArtifactSize,
|
||||
UploadResults
|
||||
} from './contracts'
|
||||
import {
|
||||
digestForStream,
|
||||
getArtifactUrl,
|
||||
getContentRange,
|
||||
getUploadHeaders,
|
||||
isRetryableStatusCode,
|
||||
isSuccessStatusCode,
|
||||
isThrottledStatusCode,
|
||||
displayHttpDiagnostics,
|
||||
getExponentialRetryTimeInMilliseconds,
|
||||
tryGetRetryAfterValueTimeInMilliseconds,
|
||||
getProperRetention,
|
||||
sleep
|
||||
} from './utils'
|
||||
import {
|
||||
getUploadChunkSize,
|
||||
getUploadFileConcurrency,
|
||||
getRetryLimit,
|
||||
getRetentionDays
|
||||
} from './config-variables'
|
||||
import {promisify} from 'util'
|
||||
import {URL} from 'url'
|
||||
import {performance} from 'perf_hooks'
|
||||
import {StatusReporter} from './status-reporter'
|
||||
import {HttpCodes, HttpClientResponse} from '@actions/http-client'
|
||||
import {HttpManager} from './http-manager'
|
||||
import {UploadSpecification} from './upload-specification'
|
||||
import {UploadOptions} from './upload-options'
|
||||
import {createGZipFileOnDisk, createGZipFileInBuffer} from './upload-gzip'
|
||||
import {retryHttpClientRequest} from './requestUtils'
|
||||
const stat = promisify(fs.stat)
|
||||
|
||||
export class UploadHttpClient {
|
||||
private uploadHttpManager: HttpManager
|
||||
private statusReporter: StatusReporter
|
||||
|
||||
constructor() {
|
||||
this.uploadHttpManager = new HttpManager(
|
||||
getUploadFileConcurrency(),
|
||||
'@actions/artifact-upload'
|
||||
)
|
||||
this.statusReporter = new StatusReporter(10000)
|
||||
}
|
||||
|
||||
/**
|
||||
* Creates a file container for the new artifact in the remote blob storage/file service
|
||||
* @param {string} artifactName Name of the artifact being created
|
||||
* @returns The response from the Artifact Service if the file container was successfully created
|
||||
*/
|
||||
async createArtifactInFileContainer(
|
||||
artifactName: string,
|
||||
options?: UploadOptions | undefined
|
||||
): Promise<ArtifactResponse> {
|
||||
const parameters: CreateArtifactParameters = {
|
||||
Type: 'actions_storage',
|
||||
Name: artifactName
|
||||
}
|
||||
|
||||
// calculate retention period
|
||||
if (options && options.retentionDays) {
|
||||
const maxRetentionStr = getRetentionDays()
|
||||
parameters.RetentionDays = getProperRetention(
|
||||
options.retentionDays,
|
||||
maxRetentionStr
|
||||
)
|
||||
}
|
||||
|
||||
const data: string = JSON.stringify(parameters, null, 2)
|
||||
const artifactUrl = getArtifactUrl()
|
||||
|
||||
// use the first client from the httpManager, `keep-alive` is not used so the connection will close immediately
|
||||
const client = this.uploadHttpManager.getClient(0)
|
||||
const headers = getUploadHeaders('application/json', false)
|
||||
|
||||
// Extra information to display when a particular HTTP code is returned
|
||||
// If a 403 is returned when trying to create a file container, the customer has exceeded
|
||||
// their storage quota so no new artifact containers can be created
|
||||
const customErrorMessages: Map<number, string> = new Map([
|
||||
[
|
||||
HttpCodes.Forbidden,
|
||||
'Artifact storage quota has been hit. Unable to upload any new artifacts'
|
||||
],
|
||||
[
|
||||
HttpCodes.BadRequest,
|
||||
`The artifact name ${artifactName} is not valid. Request URL ${artifactUrl}`
|
||||
]
|
||||
])
|
||||
|
||||
const response = await retryHttpClientRequest(
|
||||
'Create Artifact Container',
|
||||
async () => client.post(artifactUrl, data, headers),
|
||||
customErrorMessages
|
||||
)
|
||||
const body: string = await response.readBody()
|
||||
return JSON.parse(body)
|
||||
}
|
||||
|
||||
/**
|
||||
* Concurrently upload all of the files in chunks
|
||||
* @param {string} uploadUrl Base Url for the artifact that was created
|
||||
* @param {SearchResult[]} filesToUpload A list of information about the files being uploaded
|
||||
* @returns The size of all the files uploaded in bytes
|
||||
*/
|
||||
async uploadArtifactToFileContainer(
|
||||
uploadUrl: string,
|
||||
filesToUpload: UploadSpecification[],
|
||||
options?: UploadOptions
|
||||
): Promise<UploadResults> {
|
||||
const FILE_CONCURRENCY = getUploadFileConcurrency()
|
||||
const MAX_CHUNK_SIZE = getUploadChunkSize()
|
||||
core.debug(
|
||||
`File Concurrency: ${FILE_CONCURRENCY}, and Chunk Size: ${MAX_CHUNK_SIZE}`
|
||||
)
|
||||
|
||||
const parameters: UploadFileParameters[] = []
|
||||
// by default, file uploads will continue if there is an error unless specified differently in the options
|
||||
let continueOnError = true
|
||||
if (options) {
|
||||
if (options.continueOnError === false) {
|
||||
continueOnError = false
|
||||
}
|
||||
}
|
||||
|
||||
// prepare the necessary parameters to upload all the files
|
||||
for (const file of filesToUpload) {
|
||||
const resourceUrl = new URL(uploadUrl)
|
||||
resourceUrl.searchParams.append('itemPath', file.uploadFilePath)
|
||||
parameters.push({
|
||||
file: file.absoluteFilePath,
|
||||
resourceUrl: resourceUrl.toString(),
|
||||
maxChunkSize: MAX_CHUNK_SIZE,
|
||||
continueOnError
|
||||
})
|
||||
}
|
||||
|
||||
const parallelUploads = [...new Array(FILE_CONCURRENCY).keys()]
|
||||
const failedItemsToReport: string[] = []
|
||||
let currentFile = 0
|
||||
let completedFiles = 0
|
||||
let uploadFileSize = 0
|
||||
let totalFileSize = 0
|
||||
let abortPendingFileUploads = false
|
||||
|
||||
this.statusReporter.setTotalNumberOfFilesToProcess(filesToUpload.length)
|
||||
this.statusReporter.start()
|
||||
|
||||
// only allow a certain amount of files to be uploaded at once, this is done to reduce potential errors
|
||||
await Promise.all(
|
||||
parallelUploads.map(async index => {
|
||||
while (currentFile < filesToUpload.length) {
|
||||
const currentFileParameters = parameters[currentFile]
|
||||
currentFile += 1
|
||||
if (abortPendingFileUploads) {
|
||||
failedItemsToReport.push(currentFileParameters.file)
|
||||
continue
|
||||
}
|
||||
|
||||
const startTime = performance.now()
|
||||
const uploadFileResult = await this.uploadFileAsync(
|
||||
index,
|
||||
currentFileParameters
|
||||
)
|
||||
|
||||
if (core.isDebug()) {
|
||||
core.debug(
|
||||
`File: ${++completedFiles}/${filesToUpload.length}. ${
|
||||
currentFileParameters.file
|
||||
} took ${(performance.now() - startTime).toFixed(
|
||||
3
|
||||
)} milliseconds to finish upload`
|
||||
)
|
||||
}
|
||||
|
||||
uploadFileSize += uploadFileResult.successfulUploadSize
|
||||
totalFileSize += uploadFileResult.totalSize
|
||||
if (uploadFileResult.isSuccess === false) {
|
||||
failedItemsToReport.push(currentFileParameters.file)
|
||||
if (!continueOnError) {
|
||||
// fail fast
|
||||
core.error(`aborting artifact upload`)
|
||||
abortPendingFileUploads = true
|
||||
}
|
||||
}
|
||||
this.statusReporter.incrementProcessedCount()
|
||||
}
|
||||
})
|
||||
)
|
||||
|
||||
this.statusReporter.stop()
|
||||
// done uploading, safety dispose all connections
|
||||
this.uploadHttpManager.disposeAndReplaceAllClients()
|
||||
|
||||
core.info(`Total size of all the files uploaded is ${uploadFileSize} bytes`)
|
||||
return {
|
||||
uploadSize: uploadFileSize,
|
||||
totalSize: totalFileSize,
|
||||
failedItems: failedItemsToReport
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Asynchronously uploads a file. The file is compressed and uploaded using GZip if it is determined to save space.
|
||||
* If the upload file is bigger than the max chunk size it will be uploaded via multiple calls
|
||||
* @param {number} httpClientIndex The index of the httpClient that is being used to make all of the calls
|
||||
* @param {UploadFileParameters} parameters Information about the file that needs to be uploaded
|
||||
* @returns The size of the file that was uploaded in bytes along with any failed uploads
|
||||
*/
|
||||
private async uploadFileAsync(
|
||||
httpClientIndex: number,
|
||||
parameters: UploadFileParameters
|
||||
): Promise<UploadFileResult> {
|
||||
const fileStat: fs.Stats = await stat(parameters.file)
|
||||
const totalFileSize = fileStat.size
|
||||
const isFIFO = fileStat.isFIFO()
|
||||
let offset = 0
|
||||
let isUploadSuccessful = true
|
||||
let failedChunkSizes = 0
|
||||
let uploadFileSize = 0
|
||||
let isGzip = true
|
||||
|
||||
// the file that is being uploaded is less than 64k in size to increase throughput and to minimize disk I/O
|
||||
// for creating a new GZip file, an in-memory buffer is used for compression
|
||||
// with named pipes the file size is reported as zero in that case don't read the file in memory
|
||||
if (!isFIFO && totalFileSize < 65536) {
|
||||
core.debug(
|
||||
`${parameters.file} is less than 64k in size. Creating a gzip file in-memory to potentially reduce the upload size`
|
||||
)
|
||||
const buffer = await createGZipFileInBuffer(parameters.file)
|
||||
|
||||
// An open stream is needed in the event of a failure and we need to retry. If a NodeJS.ReadableStream is directly passed in,
|
||||
// it will not properly get reset to the start of the stream if a chunk upload needs to be retried
|
||||
let openUploadStream: () => NodeJS.ReadableStream
|
||||
|
||||
if (totalFileSize < buffer.byteLength) {
|
||||
// compression did not help with reducing the size, use a readable stream from the original file for upload
|
||||
core.debug(
|
||||
`The gzip file created for ${parameters.file} did not help with reducing the size of the file. The original file will be uploaded as-is`
|
||||
)
|
||||
openUploadStream = () => fs.createReadStream(parameters.file)
|
||||
isGzip = false
|
||||
uploadFileSize = totalFileSize
|
||||
} else {
|
||||
// create a readable stream using a PassThrough stream that is both readable and writable
|
||||
core.debug(
|
||||
`A gzip file created for ${parameters.file} helped with reducing the size of the original file. The file will be uploaded using gzip.`
|
||||
)
|
||||
openUploadStream = () => {
|
||||
const passThrough = new stream.PassThrough()
|
||||
passThrough.end(buffer)
|
||||
return passThrough
|
||||
}
|
||||
uploadFileSize = buffer.byteLength
|
||||
}
|
||||
|
||||
const result = await this.uploadChunk(
|
||||
httpClientIndex,
|
||||
parameters.resourceUrl,
|
||||
openUploadStream,
|
||||
0,
|
||||
uploadFileSize - 1,
|
||||
uploadFileSize,
|
||||
isGzip,
|
||||
totalFileSize
|
||||
)
|
||||
|
||||
if (!result) {
|
||||
// chunk failed to upload
|
||||
isUploadSuccessful = false
|
||||
failedChunkSizes += uploadFileSize
|
||||
core.warning(`Aborting upload for ${parameters.file} due to failure`)
|
||||
}
|
||||
|
||||
return {
|
||||
isSuccess: isUploadSuccessful,
|
||||
successfulUploadSize: uploadFileSize - failedChunkSizes,
|
||||
totalSize: totalFileSize
|
||||
}
|
||||
} else {
|
||||
// the file that is being uploaded is greater than 64k in size, a temporary file gets created on disk using the
|
||||
// npm tmp-promise package and this file gets used to create a GZipped file
|
||||
const tempFile = await tmp.file()
|
||||
core.debug(
|
||||
`${parameters.file} is greater than 64k in size. Creating a gzip file on-disk ${tempFile.path} to potentially reduce the upload size`
|
||||
)
|
||||
|
||||
// create a GZip file of the original file being uploaded, the original file should not be modified in any way
|
||||
uploadFileSize = await createGZipFileOnDisk(
|
||||
parameters.file,
|
||||
tempFile.path
|
||||
)
|
||||
|
||||
let uploadFilePath = tempFile.path
|
||||
|
||||
// compression did not help with size reduction, use the original file for upload and delete the temp GZip file
|
||||
// for named pipes totalFileSize is zero, this assumes compression did help
|
||||
if (!isFIFO && totalFileSize < uploadFileSize) {
|
||||
core.debug(
|
||||
`The gzip file created for ${parameters.file} did not help with reducing the size of the file. The original file will be uploaded as-is`
|
||||
)
|
||||
uploadFileSize = totalFileSize
|
||||
uploadFilePath = parameters.file
|
||||
isGzip = false
|
||||
} else {
|
||||
core.debug(
|
||||
`The gzip file created for ${parameters.file} is smaller than the original file. The file will be uploaded using gzip.`
|
||||
)
|
||||
}
|
||||
|
||||
let abortFileUpload = false
|
||||
// upload only a single chunk at a time
|
||||
while (offset < uploadFileSize) {
|
||||
const chunkSize = Math.min(
|
||||
uploadFileSize - offset,
|
||||
parameters.maxChunkSize
|
||||
)
|
||||
|
||||
const startChunkIndex = offset
|
||||
const endChunkIndex = offset + chunkSize - 1
|
||||
offset += parameters.maxChunkSize
|
||||
|
||||
if (abortFileUpload) {
|
||||
// if we don't want to continue in the event of an error, any pending upload chunks will be marked as failed
|
||||
failedChunkSizes += chunkSize
|
||||
continue
|
||||
}
|
||||
|
||||
const result = await this.uploadChunk(
|
||||
httpClientIndex,
|
||||
parameters.resourceUrl,
|
||||
() =>
|
||||
fs.createReadStream(uploadFilePath, {
|
||||
start: startChunkIndex,
|
||||
end: endChunkIndex,
|
||||
autoClose: false
|
||||
}),
|
||||
startChunkIndex,
|
||||
endChunkIndex,
|
||||
uploadFileSize,
|
||||
isGzip,
|
||||
totalFileSize
|
||||
)
|
||||
|
||||
if (!result) {
|
||||
// Chunk failed to upload, report as failed and do not continue uploading any more chunks for the file. It is possible that part of a chunk was
|
||||
// successfully uploaded so the server may report a different size for what was uploaded
|
||||
isUploadSuccessful = false
|
||||
failedChunkSizes += chunkSize
|
||||
core.warning(`Aborting upload for ${parameters.file} due to failure`)
|
||||
abortFileUpload = true
|
||||
} else {
|
||||
// if an individual file is greater than 8MB (1024*1024*8) in size, display extra information about the upload status
|
||||
if (uploadFileSize > 8388608) {
|
||||
this.statusReporter.updateLargeFileStatus(
|
||||
parameters.file,
|
||||
startChunkIndex,
|
||||
endChunkIndex,
|
||||
uploadFileSize
|
||||
)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// Delete the temporary file that was created as part of the upload. If the temp file does not get manually deleted by
|
||||
// calling cleanup, it gets removed when the node process exits. For more info see: https://www.npmjs.com/package/tmp-promise#about
|
||||
core.debug(`deleting temporary gzip file ${tempFile.path}`)
|
||||
await tempFile.cleanup()
|
||||
|
||||
return {
|
||||
isSuccess: isUploadSuccessful,
|
||||
successfulUploadSize: uploadFileSize - failedChunkSizes,
|
||||
totalSize: totalFileSize
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Uploads a chunk of an individual file to the specified resourceUrl. If the upload fails and the status code
|
||||
* indicates a retryable status, we try to upload the chunk as well
|
||||
* @param {number} httpClientIndex The index of the httpClient being used to make all the necessary calls
|
||||
* @param {string} resourceUrl Url of the resource that the chunk will be uploaded to
|
||||
* @param {NodeJS.ReadableStream} openStream Stream of the file that will be uploaded
|
||||
* @param {number} start Starting byte index of file that the chunk belongs to
|
||||
* @param {number} end Ending byte index of file that the chunk belongs to
|
||||
* @param {number} uploadFileSize Total size of the file in bytes that is being uploaded
|
||||
* @param {boolean} isGzip Denotes if we are uploading a Gzip compressed stream
|
||||
* @param {number} totalFileSize Original total size of the file that is being uploaded
|
||||
* @returns if the chunk was successfully uploaded
|
||||
*/
|
||||
private async uploadChunk(
|
||||
httpClientIndex: number,
|
||||
resourceUrl: string,
|
||||
openStream: () => NodeJS.ReadableStream,
|
||||
start: number,
|
||||
end: number,
|
||||
uploadFileSize: number,
|
||||
isGzip: boolean,
|
||||
totalFileSize: number
|
||||
): Promise<boolean> {
|
||||
// open a new stream and read it to compute the digest
|
||||
const digest = await digestForStream(openStream())
|
||||
|
||||
// prepare all the necessary headers before making any http call
|
||||
const headers = getUploadHeaders(
|
||||
'application/octet-stream',
|
||||
true,
|
||||
isGzip,
|
||||
totalFileSize,
|
||||
end - start + 1,
|
||||
getContentRange(start, end, uploadFileSize),
|
||||
digest
|
||||
)
|
||||
|
||||
const uploadChunkRequest = async (): Promise<HttpClientResponse> => {
|
||||
const client = this.uploadHttpManager.getClient(httpClientIndex)
|
||||
return await client.sendStream('PUT', resourceUrl, openStream(), headers)
|
||||
}
|
||||
|
||||
let retryCount = 0
|
||||
const retryLimit = getRetryLimit()
|
||||
|
||||
// Increments the current retry count and then checks if the retry limit has been reached
|
||||
// If there have been too many retries, fail so the download stops
|
||||
const incrementAndCheckRetryLimit = (
|
||||
response?: HttpClientResponse
|
||||
): boolean => {
|
||||
retryCount++
|
||||
if (retryCount > retryLimit) {
|
||||
if (response) {
|
||||
displayHttpDiagnostics(response)
|
||||
}
|
||||
core.info(
|
||||
`Retry limit has been reached for chunk at offset ${start} to ${resourceUrl}`
|
||||
)
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
const backOff = async (retryAfterValue?: number): Promise<void> => {
|
||||
this.uploadHttpManager.disposeAndReplaceClient(httpClientIndex)
|
||||
if (retryAfterValue) {
|
||||
core.info(
|
||||
`Backoff due to too many requests, retry #${retryCount}. Waiting for ${retryAfterValue} milliseconds before continuing the upload`
|
||||
)
|
||||
await sleep(retryAfterValue)
|
||||
} else {
|
||||
const backoffTime = getExponentialRetryTimeInMilliseconds(retryCount)
|
||||
core.info(
|
||||
`Exponential backoff for retry #${retryCount}. Waiting for ${backoffTime} milliseconds before continuing the upload at offset ${start}`
|
||||
)
|
||||
await sleep(backoffTime)
|
||||
}
|
||||
core.info(
|
||||
`Finished backoff for retry #${retryCount}, continuing with upload`
|
||||
)
|
||||
return
|
||||
}
|
||||
|
||||
// allow for failed chunks to be retried multiple times
|
||||
while (retryCount <= retryLimit) {
|
||||
let response: HttpClientResponse
|
||||
|
||||
try {
|
||||
response = await uploadChunkRequest()
|
||||
} catch (error) {
|
||||
// if an error is caught, it is usually indicative of a timeout so retry the upload
|
||||
core.info(
|
||||
`An error has been caught http-client index ${httpClientIndex}, retrying the upload`
|
||||
)
|
||||
// eslint-disable-next-line no-console
|
||||
console.log(error)
|
||||
|
||||
if (incrementAndCheckRetryLimit()) {
|
||||
return false
|
||||
}
|
||||
await backOff()
|
||||
continue
|
||||
}
|
||||
|
||||
// Always read the body of the response. There is potential for a resource leak if the body is not read which will
|
||||
// result in the connection remaining open along with unintended consequences when trying to dispose of the client
|
||||
await response.readBody()
|
||||
|
||||
if (isSuccessStatusCode(response.message.statusCode)) {
|
||||
return true
|
||||
} else if (isRetryableStatusCode(response.message.statusCode)) {
|
||||
core.info(
|
||||
`A ${response.message.statusCode} status code has been received, will attempt to retry the upload`
|
||||
)
|
||||
if (incrementAndCheckRetryLimit(response)) {
|
||||
return false
|
||||
}
|
||||
isThrottledStatusCode(response.message.statusCode)
|
||||
? await backOff(
|
||||
tryGetRetryAfterValueTimeInMilliseconds(response.message.headers)
|
||||
)
|
||||
: await backOff()
|
||||
} else {
|
||||
core.error(
|
||||
`Unexpected response. Unable to upload chunk to ${resourceUrl}`
|
||||
)
|
||||
displayHttpDiagnostics(response)
|
||||
return false
|
||||
}
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
/**
|
||||
* Updates the size of the artifact from -1 which was initially set when the container was first created for the artifact.
|
||||
* Updating the size indicates that we are done uploading all the contents of the artifact
|
||||
*/
|
||||
async patchArtifactSize(size: number, artifactName: string): Promise<void> {
|
||||
const resourceUrl = new URL(getArtifactUrl())
|
||||
resourceUrl.searchParams.append('artifactName', artifactName)
|
||||
|
||||
const parameters: PatchArtifactSize = {Size: size}
|
||||
const data: string = JSON.stringify(parameters, null, 2)
|
||||
core.debug(`URL is ${resourceUrl.toString()}`)
|
||||
|
||||
// use the first client from the httpManager, `keep-alive` is not used so the connection will close immediately
|
||||
const client = this.uploadHttpManager.getClient(0)
|
||||
const headers = getUploadHeaders('application/json', false)
|
||||
|
||||
// Extra information to display when a particular HTTP code is returned
|
||||
const customErrorMessages: Map<number, string> = new Map([
|
||||
[
|
||||
HttpCodes.NotFound,
|
||||
`An Artifact with the name ${artifactName} was not found`
|
||||
]
|
||||
])
|
||||
|
||||
// TODO retry for all possible response codes, the artifact upload is pretty much complete so it at all costs we should try to finish this
|
||||
const response = await retryHttpClientRequest(
|
||||
'Finalize artifact upload',
|
||||
async () => client.patch(resourceUrl.toString(), data, headers),
|
||||
customErrorMessages
|
||||
)
|
||||
await response.readBody()
|
||||
core.debug(
|
||||
`Artifact ${artifactName} has been successfully uploaded, total size in bytes: ${size}`
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
interface UploadFileParameters {
|
||||
file: string
|
||||
resourceUrl: string
|
||||
maxChunkSize: number
|
||||
continueOnError: boolean
|
||||
}
|
||||
|
||||
interface UploadFileResult {
|
||||
isSuccess: boolean
|
||||
successfulUploadSize: number
|
||||
totalSize: number
|
||||
}
|
||||
@@ -1,35 +0,0 @@
|
||||
export interface UploadOptions {
|
||||
/**
|
||||
* Indicates if the artifact upload should continue if file or chunk fails to upload from any error.
|
||||
* If there is a error during upload, a partial artifact will always be associated and available for
|
||||
* download at the end. The size reported will be the amount of storage that the user or org will be
|
||||
* charged for the partial artifact. Defaults to true if not specified
|
||||
*
|
||||
* If set to false, and an error is encountered, all other uploads will stop and any files or chunks
|
||||
* that were queued will not be attempted to be uploaded. The partial artifact available will only
|
||||
* include files and chunks up until the failure
|
||||
*
|
||||
* If set to true and an error is encountered, the failed file will be skipped and ignored and all
|
||||
* other queued files will be attempted to be uploaded. The partial artifact at the end will have all
|
||||
* files with the exception of the problematic files(s)/chunks(s) that failed to upload
|
||||
*
|
||||
*/
|
||||
continueOnError?: boolean
|
||||
|
||||
/**
|
||||
* Duration after which artifact will expire in days.
|
||||
*
|
||||
* By default artifact expires after 90 days:
|
||||
* https://docs.github.com/en/actions/configuring-and-managing-workflows/persisting-workflow-data-using-artifacts#downloading-and-deleting-artifacts-after-a-workflow-run-is-complete
|
||||
*
|
||||
* Use this option to override the default expiry.
|
||||
*
|
||||
* Min value: 1
|
||||
* Max value: 90 unless changed by repository setting
|
||||
*
|
||||
* If this is set to a greater value than the retention settings allowed, the retention on artifacts
|
||||
* will be reduced to match the max value allowed on server, and the upload process will continue. An
|
||||
* input of 0 assumes default retention setting.
|
||||
*/
|
||||
retentionDays?: number
|
||||
}
|
||||
@@ -1,22 +0,0 @@
|
||||
export interface UploadResponse {
|
||||
/**
|
||||
* The name of the artifact that was uploaded
|
||||
*/
|
||||
artifactName: string
|
||||
|
||||
/**
|
||||
* A list of all items that are meant to be uploaded as part of the artifact
|
||||
*/
|
||||
artifactItems: string[]
|
||||
|
||||
/**
|
||||
* Total size of the artifact in bytes that was uploaded
|
||||
*/
|
||||
size: number
|
||||
|
||||
/**
|
||||
* A list of items that were not uploaded as part of the artifact (includes queued items that were not uploaded if
|
||||
* continueOnError is set to false). This is a subset of artifactItems.
|
||||
*/
|
||||
failedItems: string[]
|
||||
}
|
||||
@@ -1,94 +0,0 @@
|
||||
import * as fs from 'fs'
|
||||
import {debug} from '@actions/core'
|
||||
import {join, normalize, resolve} from 'path'
|
||||
import {checkArtifactFilePath} from './path-and-artifact-name-validation'
|
||||
|
||||
export interface UploadSpecification {
|
||||
absoluteFilePath: string
|
||||
uploadFilePath: string
|
||||
}
|
||||
|
||||
/**
|
||||
* Creates a specification that describes how each file that is part of the artifact will be uploaded
|
||||
* @param artifactName the name of the artifact being uploaded. Used during upload to denote where the artifact is stored on the server
|
||||
* @param rootDirectory an absolute file path that denotes the path that should be removed from the beginning of each artifact file
|
||||
* @param artifactFiles a list of absolute file paths that denote what should be uploaded as part of the artifact
|
||||
*/
|
||||
export function getUploadSpecification(
|
||||
artifactName: string,
|
||||
rootDirectory: string,
|
||||
artifactFiles: string[]
|
||||
): UploadSpecification[] {
|
||||
// artifact name was checked earlier on, no need to check again
|
||||
const specifications: UploadSpecification[] = []
|
||||
|
||||
if (!fs.existsSync(rootDirectory)) {
|
||||
throw new Error(`Provided rootDirectory ${rootDirectory} does not exist`)
|
||||
}
|
||||
if (!fs.statSync(rootDirectory).isDirectory()) {
|
||||
throw new Error(
|
||||
`Provided rootDirectory ${rootDirectory} is not a valid directory`
|
||||
)
|
||||
}
|
||||
// Normalize and resolve, this allows for either absolute or relative paths to be used
|
||||
rootDirectory = normalize(rootDirectory)
|
||||
rootDirectory = resolve(rootDirectory)
|
||||
|
||||
/*
|
||||
Example to demonstrate behavior
|
||||
|
||||
Input:
|
||||
artifactName: my-artifact
|
||||
rootDirectory: '/home/user/files/plz-upload'
|
||||
artifactFiles: [
|
||||
'/home/user/files/plz-upload/file1.txt',
|
||||
'/home/user/files/plz-upload/file2.txt',
|
||||
'/home/user/files/plz-upload/dir/file3.txt'
|
||||
]
|
||||
|
||||
Output:
|
||||
specifications: [
|
||||
['/home/user/files/plz-upload/file1.txt', 'my-artifact/file1.txt'],
|
||||
['/home/user/files/plz-upload/file1.txt', 'my-artifact/file2.txt'],
|
||||
['/home/user/files/plz-upload/file1.txt', 'my-artifact/dir/file3.txt']
|
||||
]
|
||||
*/
|
||||
for (let file of artifactFiles) {
|
||||
if (!fs.existsSync(file)) {
|
||||
throw new Error(`File ${file} does not exist`)
|
||||
}
|
||||
if (!fs.statSync(file).isDirectory()) {
|
||||
// Normalize and resolve, this allows for either absolute or relative paths to be used
|
||||
file = normalize(file)
|
||||
file = resolve(file)
|
||||
if (!file.startsWith(rootDirectory)) {
|
||||
throw new Error(
|
||||
`The rootDirectory: ${rootDirectory} is not a parent directory of the file: ${file}`
|
||||
)
|
||||
}
|
||||
|
||||
// Check for forbidden characters in file paths that will be rejected during upload
|
||||
const uploadPath = file.replace(rootDirectory, '')
|
||||
checkArtifactFilePath(uploadPath)
|
||||
|
||||
/*
|
||||
uploadFilePath denotes where the file will be uploaded in the file container on the server. During a run, if multiple artifacts are uploaded, they will all
|
||||
be saved in the same container. The artifact name is used as the root directory in the container to separate and distinguish uploaded artifacts
|
||||
|
||||
path.join handles all the following cases and would return 'artifact-name/file-to-upload.txt
|
||||
join('artifact-name/', 'file-to-upload.txt')
|
||||
join('artifact-name/', '/file-to-upload.txt')
|
||||
join('artifact-name', 'file-to-upload.txt')
|
||||
join('artifact-name', '/file-to-upload.txt')
|
||||
*/
|
||||
specifications.push({
|
||||
absoluteFilePath: file,
|
||||
uploadFilePath: join(artifactName, uploadPath)
|
||||
})
|
||||
} else {
|
||||
// Directories are rejected by the server during upload
|
||||
debug(`Removing ${file} from rawSearchResults because it is a directory`)
|
||||
}
|
||||
}
|
||||
return specifications
|
||||
}
|
||||
@@ -1,325 +0,0 @@
|
||||
import crypto from 'crypto'
|
||||
import {promises as fs} from 'fs'
|
||||
import {IncomingHttpHeaders, OutgoingHttpHeaders} from 'http'
|
||||
import {debug, info, warning} from '@actions/core'
|
||||
import {HttpCodes, HttpClient, HttpClientResponse} from '@actions/http-client'
|
||||
import {BearerCredentialHandler} from '@actions/http-client/lib/auth'
|
||||
import {
|
||||
getRuntimeToken,
|
||||
getRuntimeUrl,
|
||||
getWorkFlowRunId,
|
||||
getRetryMultiplier,
|
||||
getInitialRetryIntervalInMilliseconds
|
||||
} from './config-variables'
|
||||
import CRC64 from './crc64'
|
||||
|
||||
/**
|
||||
* Returns a retry time in milliseconds that exponentially gets larger
|
||||
* depending on the amount of retries that have been attempted
|
||||
*/
|
||||
export function getExponentialRetryTimeInMilliseconds(
|
||||
retryCount: number
|
||||
): number {
|
||||
if (retryCount < 0) {
|
||||
throw new Error('RetryCount should not be negative')
|
||||
} else if (retryCount === 0) {
|
||||
return getInitialRetryIntervalInMilliseconds()
|
||||
}
|
||||
|
||||
const minTime =
|
||||
getInitialRetryIntervalInMilliseconds() * getRetryMultiplier() * retryCount
|
||||
const maxTime = minTime * getRetryMultiplier()
|
||||
|
||||
// returns a random number between the minTime (inclusive) and the maxTime (exclusive)
|
||||
return Math.trunc(Math.random() * (maxTime - minTime) + minTime)
|
||||
}
|
||||
|
||||
/**
|
||||
* Parses a env variable that is a number
|
||||
*/
|
||||
export function parseEnvNumber(key: string): number | undefined {
|
||||
const value = Number(process.env[key])
|
||||
if (Number.isNaN(value) || value < 0) {
|
||||
return undefined
|
||||
}
|
||||
return value
|
||||
}
|
||||
|
||||
/**
|
||||
* Various utility functions to help with the necessary API calls
|
||||
*/
|
||||
export function getApiVersion(): string {
|
||||
return '6.0-preview'
|
||||
}
|
||||
|
||||
export function isSuccessStatusCode(statusCode?: number): boolean {
|
||||
if (!statusCode) {
|
||||
return false
|
||||
}
|
||||
return statusCode >= 200 && statusCode < 300
|
||||
}
|
||||
|
||||
export function isForbiddenStatusCode(statusCode?: number): boolean {
|
||||
if (!statusCode) {
|
||||
return false
|
||||
}
|
||||
return statusCode === HttpCodes.Forbidden
|
||||
}
|
||||
|
||||
export function isRetryableStatusCode(statusCode: number | undefined): boolean {
|
||||
if (!statusCode) {
|
||||
return false
|
||||
}
|
||||
|
||||
const retryableStatusCodes = [
|
||||
HttpCodes.BadGateway,
|
||||
HttpCodes.GatewayTimeout,
|
||||
HttpCodes.InternalServerError,
|
||||
HttpCodes.ServiceUnavailable,
|
||||
HttpCodes.TooManyRequests,
|
||||
413 // Payload Too Large
|
||||
]
|
||||
return retryableStatusCodes.includes(statusCode)
|
||||
}
|
||||
|
||||
export function isThrottledStatusCode(statusCode?: number): boolean {
|
||||
if (!statusCode) {
|
||||
return false
|
||||
}
|
||||
return statusCode === HttpCodes.TooManyRequests
|
||||
}
|
||||
|
||||
/**
|
||||
* Attempts to get the retry-after value from a set of http headers. The retry time
|
||||
* is originally denoted in seconds, so if present, it is converted to milliseconds
|
||||
* @param headers all the headers received when making an http call
|
||||
*/
|
||||
export function tryGetRetryAfterValueTimeInMilliseconds(
|
||||
headers: IncomingHttpHeaders
|
||||
): number | undefined {
|
||||
if (headers['retry-after']) {
|
||||
const retryTime = Number(headers['retry-after'])
|
||||
if (!isNaN(retryTime)) {
|
||||
info(`Retry-After header is present with a value of ${retryTime}`)
|
||||
return retryTime * 1000
|
||||
}
|
||||
info(
|
||||
`Returned retry-after header value: ${retryTime} is non-numeric and cannot be used`
|
||||
)
|
||||
return undefined
|
||||
}
|
||||
info(
|
||||
`No retry-after header was found. Dumping all headers for diagnostic purposes`
|
||||
)
|
||||
// eslint-disable-next-line no-console
|
||||
console.log(headers)
|
||||
return undefined
|
||||
}
|
||||
|
||||
export function getContentRange(
|
||||
start: number,
|
||||
end: number,
|
||||
total: number
|
||||
): string {
|
||||
// Format: `bytes start-end/fileSize
|
||||
// start and end are inclusive
|
||||
// For a 200 byte chunk starting at byte 0:
|
||||
// Content-Range: bytes 0-199/200
|
||||
return `bytes ${start}-${end}/${total}`
|
||||
}
|
||||
|
||||
/**
|
||||
* Sets all the necessary headers when downloading an artifact
|
||||
* @param {string} contentType the type of content being uploaded
|
||||
* @param {boolean} isKeepAlive is the same connection being used to make multiple calls
|
||||
* @param {boolean} acceptGzip can we accept a gzip encoded response
|
||||
* @param {string} acceptType the type of content that we can accept
|
||||
* @returns appropriate headers to make a specific http call during artifact download
|
||||
*/
|
||||
export function getDownloadHeaders(
|
||||
contentType: string,
|
||||
isKeepAlive?: boolean,
|
||||
acceptGzip?: boolean
|
||||
): OutgoingHttpHeaders {
|
||||
const requestOptions: OutgoingHttpHeaders = {}
|
||||
|
||||
if (contentType) {
|
||||
requestOptions['Content-Type'] = contentType
|
||||
}
|
||||
if (isKeepAlive) {
|
||||
requestOptions['Connection'] = 'Keep-Alive'
|
||||
// keep alive for at least 10 seconds before closing the connection
|
||||
requestOptions['Keep-Alive'] = '10'
|
||||
}
|
||||
if (acceptGzip) {
|
||||
// if we are expecting a response with gzip encoding, it should be using an octet-stream in the accept header
|
||||
requestOptions['Accept-Encoding'] = 'gzip'
|
||||
requestOptions[
|
||||
'Accept'
|
||||
] = `application/octet-stream;api-version=${getApiVersion()}`
|
||||
} else {
|
||||
// default to application/json if we are not working with gzip content
|
||||
requestOptions['Accept'] = `application/json;api-version=${getApiVersion()}`
|
||||
}
|
||||
|
||||
return requestOptions
|
||||
}
|
||||
|
||||
/**
|
||||
* Sets all the necessary headers when uploading an artifact
|
||||
* @param {string} contentType the type of content being uploaded
|
||||
* @param {boolean} isKeepAlive is the same connection being used to make multiple calls
|
||||
* @param {boolean} isGzip is the connection being used to upload GZip compressed content
|
||||
* @param {number} uncompressedLength the original size of the content if something is being uploaded that has been compressed
|
||||
* @param {number} contentLength the length of the content that is being uploaded
|
||||
* @param {string} contentRange the range of the content that is being uploaded
|
||||
* @returns appropriate headers to make a specific http call during artifact upload
|
||||
*/
|
||||
export function getUploadHeaders(
|
||||
contentType: string,
|
||||
isKeepAlive?: boolean,
|
||||
isGzip?: boolean,
|
||||
uncompressedLength?: number,
|
||||
contentLength?: number,
|
||||
contentRange?: string,
|
||||
digest?: StreamDigest
|
||||
): OutgoingHttpHeaders {
|
||||
const requestOptions: OutgoingHttpHeaders = {}
|
||||
requestOptions['Accept'] = `application/json;api-version=${getApiVersion()}`
|
||||
if (contentType) {
|
||||
requestOptions['Content-Type'] = contentType
|
||||
}
|
||||
if (isKeepAlive) {
|
||||
requestOptions['Connection'] = 'Keep-Alive'
|
||||
// keep alive for at least 10 seconds before closing the connection
|
||||
requestOptions['Keep-Alive'] = '10'
|
||||
}
|
||||
if (isGzip) {
|
||||
requestOptions['Content-Encoding'] = 'gzip'
|
||||
requestOptions['x-tfs-filelength'] = uncompressedLength
|
||||
}
|
||||
if (contentLength) {
|
||||
requestOptions['Content-Length'] = contentLength
|
||||
}
|
||||
if (contentRange) {
|
||||
requestOptions['Content-Range'] = contentRange
|
||||
}
|
||||
if (digest) {
|
||||
requestOptions['x-actions-results-crc64'] = digest.crc64
|
||||
requestOptions['x-actions-results-md5'] = digest.md5
|
||||
}
|
||||
|
||||
return requestOptions
|
||||
}
|
||||
|
||||
export function createHttpClient(userAgent: string): HttpClient {
|
||||
return new HttpClient(userAgent, [
|
||||
new BearerCredentialHandler(getRuntimeToken())
|
||||
])
|
||||
}
|
||||
|
||||
export function getArtifactUrl(): string {
|
||||
const artifactUrl = `${getRuntimeUrl()}_apis/pipelines/workflows/${getWorkFlowRunId()}/artifacts?api-version=${getApiVersion()}`
|
||||
debug(`Artifact Url: ${artifactUrl}`)
|
||||
return artifactUrl
|
||||
}
|
||||
|
||||
/**
|
||||
* Uh oh! Something might have gone wrong during either upload or download. The IHtttpClientResponse object contains information
|
||||
* about the http call that was made by the actions http client. This information might be useful to display for diagnostic purposes, but
|
||||
* this entire object is really big and most of the information is not really useful. This function takes the response object and displays only
|
||||
* the information that we want.
|
||||
*
|
||||
* Certain information such as the TLSSocket and the Readable state are not really useful for diagnostic purposes so they can be avoided.
|
||||
* Other information such as the headers, the response code and message might be useful, so this is displayed.
|
||||
*/
|
||||
export function displayHttpDiagnostics(response: HttpClientResponse): void {
|
||||
info(
|
||||
`##### Begin Diagnostic HTTP information #####
|
||||
Status Code: ${response.message.statusCode}
|
||||
Status Message: ${response.message.statusMessage}
|
||||
Header Information: ${JSON.stringify(response.message.headers, undefined, 2)}
|
||||
###### End Diagnostic HTTP information ######`
|
||||
)
|
||||
}
|
||||
|
||||
export async function createDirectoriesForArtifact(
|
||||
directories: string[]
|
||||
): Promise<void> {
|
||||
for (const directory of directories) {
|
||||
await fs.mkdir(directory, {
|
||||
recursive: true
|
||||
})
|
||||
}
|
||||
}
|
||||
|
||||
export async function createEmptyFilesForArtifact(
|
||||
emptyFilesToCreate: string[]
|
||||
): Promise<void> {
|
||||
for (const filePath of emptyFilesToCreate) {
|
||||
await (await fs.open(filePath, 'w')).close()
|
||||
}
|
||||
}
|
||||
|
||||
export async function getFileSize(filePath: string): Promise<number> {
|
||||
const stats = await fs.stat(filePath)
|
||||
debug(
|
||||
`${filePath} size:(${stats.size}) blksize:(${stats.blksize}) blocks:(${stats.blocks})`
|
||||
)
|
||||
return stats.size
|
||||
}
|
||||
|
||||
export async function rmFile(filePath: string): Promise<void> {
|
||||
await fs.unlink(filePath)
|
||||
}
|
||||
|
||||
export function getProperRetention(
|
||||
retentionInput: number,
|
||||
retentionSetting: string | undefined
|
||||
): number {
|
||||
if (retentionInput < 0) {
|
||||
throw new Error('Invalid retention, minimum value is 1.')
|
||||
}
|
||||
|
||||
let retention = retentionInput
|
||||
if (retentionSetting) {
|
||||
const maxRetention = parseInt(retentionSetting)
|
||||
if (!isNaN(maxRetention) && maxRetention < retention) {
|
||||
warning(
|
||||
`Retention days is greater than the max value allowed by the repository setting, reduce retention to ${maxRetention} days`
|
||||
)
|
||||
retention = maxRetention
|
||||
}
|
||||
}
|
||||
return retention
|
||||
}
|
||||
|
||||
export async function sleep(milliseconds: number): Promise<void> {
|
||||
return new Promise(resolve => setTimeout(resolve, milliseconds))
|
||||
}
|
||||
|
||||
export interface StreamDigest {
|
||||
crc64: string
|
||||
md5: string
|
||||
}
|
||||
|
||||
export async function digestForStream(
|
||||
stream: NodeJS.ReadableStream
|
||||
): Promise<StreamDigest> {
|
||||
return new Promise((resolve, reject) => {
|
||||
const crc64 = new CRC64()
|
||||
const md5 = crypto.createHash('md5')
|
||||
stream
|
||||
.on('data', data => {
|
||||
crc64.update(data)
|
||||
md5.update(data)
|
||||
})
|
||||
.on('end', () =>
|
||||
resolve({
|
||||
crc64: crc64.digest('base64') as string,
|
||||
md5: md5.digest('base64')
|
||||
})
|
||||
)
|
||||
.on('error', reject)
|
||||
})
|
||||
}
|
||||
@@ -1,11 +0,0 @@
|
||||
{
|
||||
"extends": "../../tsconfig.json",
|
||||
"compilerOptions": {
|
||||
"baseUrl": "./",
|
||||
"outDir": "./lib",
|
||||
"rootDir": "./src"
|
||||
},
|
||||
"include": [
|
||||
"./src"
|
||||
]
|
||||
}
|
||||
Vendored
-9
@@ -1,9 +0,0 @@
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright 2019 GitHub
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
||||
Vendored
-51
@@ -1,51 +0,0 @@
|
||||
# `@actions/cache`
|
||||
|
||||
> Functions necessary for caching dependencies and build outputs to improve workflow execution time.
|
||||
|
||||
See ["Caching dependencies to speed up workflows"](https://docs.github.com/en/actions/using-workflows/caching-dependencies-to-speed-up-workflows) for how caching works.
|
||||
|
||||
Note that GitHub will remove any cache entries that have not been accessed in over 7 days. There is no limit on the number of caches you can store, but the total size of all caches in a repository is limited to 10 GB. If you exceed this limit, GitHub will save your cache but will begin evicting caches until the total size is less than 10 GB.
|
||||
|
||||
## Usage
|
||||
|
||||
This package is used by the v2+ versions of our first party cache action. You can find an example implementation in the cache repo [here](https://github.com/actions/cache).
|
||||
|
||||
#### Save Cache
|
||||
|
||||
Saves a cache containing the files in `paths` using the `key` provided. The files would be compressed using zstandard compression algorithm if zstd is installed, otherwise gzip is used. Function returns the cache id if the cache was saved succesfully and throws an error if cache upload fails.
|
||||
|
||||
```js
|
||||
const cache = require('@actions/cache');
|
||||
const paths = [
|
||||
'node_modules',
|
||||
'packages/*/node_modules/'
|
||||
]
|
||||
const key = 'npm-foobar-d5ea0750'
|
||||
const cacheId = await cache.saveCache(paths, key)
|
||||
```
|
||||
|
||||
#### Restore Cache
|
||||
|
||||
Restores a cache based on `key` and `restoreKeys` to the `paths` provided. Function returns the cache key for cache hit and returns undefined if cache not found.
|
||||
|
||||
```js
|
||||
const cache = require('@actions/cache');
|
||||
const paths = [
|
||||
'node_modules',
|
||||
'packages/*/node_modules/'
|
||||
]
|
||||
const key = 'npm-foobar-d5ea0750'
|
||||
const restoreKeys = [
|
||||
'npm-foobar-',
|
||||
'npm-'
|
||||
]
|
||||
const cacheKey = await cache.restoreCache(paths, key, restoreKeys)
|
||||
```
|
||||
|
||||
##### Cache segment restore timeout
|
||||
|
||||
A cache gets downloaded in multiple segments of fixed sizes (now `128MB` to fail-fast, previously `1GB` for a `32-bit` runner and `2GB` for a `64-bit` runner were used). Sometimes, a segment download gets stuck which causes the workflow job to be stuck forever and fail. Version `v3.0.4` of cache package introduces a segment download timeout. The segment download timeout will allow the segment download to get aborted and hence allow the job to proceed with a cache miss.
|
||||
|
||||
Default value of this timeout is 10 minutes (starting `v3.2.1` and higher, previously 60 minutes in versions between `v.3.0.4` and `v3.2.0`, both included) and can be customized by specifying an [environment variable](https://docs.github.com/en/actions/learn-github-actions/environment-variables) named `SEGMENT_DOWNLOAD_TIMEOUT_MINS` with timeout value in minutes.
|
||||
|
||||
|
||||
Vendored
-162
@@ -1,162 +0,0 @@
|
||||
# @actions/cache Releases
|
||||
|
||||
### 0.1.0
|
||||
|
||||
- Initial release
|
||||
|
||||
### 0.2.0
|
||||
|
||||
- Fixes issues with the zstd compression algorithm on Windows and Ubuntu 16.04 [#469](https://github.com/actions/toolkit/pull/469)
|
||||
|
||||
### 0.2.1
|
||||
|
||||
- Fix to await async function getCompressionMethod
|
||||
|
||||
### 1.0.0
|
||||
|
||||
- Downloads Azure-hosted caches using the Azure SDK for speed and reliability
|
||||
- Displays download progress
|
||||
- Includes changes that break compatibility with earlier versions, including:
|
||||
- `retry`, `retryTypedResponse`, and `retryHttpClientResponse` moved from `cacheHttpClient` to `requestUtils`
|
||||
|
||||
### 1.0.1
|
||||
|
||||
- Fix bug in downloading large files (> 2 GBs) with the Azure SDK
|
||||
|
||||
### 1.0.2
|
||||
|
||||
- Use posix archive format to add support for some tools
|
||||
|
||||
### 1.0.3
|
||||
|
||||
- Use http-client v1.0.9
|
||||
- Fixes error handling so retries are not attempted on non-retryable errors (409 Conflict, for example)
|
||||
- Adds 5 second delay between retry attempts
|
||||
|
||||
### 1.0.4
|
||||
|
||||
- Use @actions/core v1.2.6
|
||||
- Fixes uploadChunk to throw an error if any unsuccessful response code is received
|
||||
|
||||
### 1.0.5
|
||||
|
||||
- Fix to ensure Windows cache paths get resolved correctly
|
||||
|
||||
### 1.0.6
|
||||
|
||||
- Make caching more verbose [#650](https://github.com/actions/toolkit/pull/650)
|
||||
- Use GNU tar on macOS if available [#701](https://github.com/actions/toolkit/pull/701)
|
||||
|
||||
### 1.0.7
|
||||
|
||||
- Fixes permissions issue extracting archives with GNU tar on macOS ([issue](https://github.com/actions/cache/issues/527))
|
||||
|
||||
### 1.0.8
|
||||
|
||||
- Increase the allowed artifact cache size from 5GB to 10GB ([issue](https://github.com/actions/cache/discussions/497))
|
||||
|
||||
### 1.0.9
|
||||
|
||||
- Use @azure/ms-rest-js v2.6.0
|
||||
- Use @azure/storage-blob v12.8.0
|
||||
|
||||
### 1.0.10
|
||||
|
||||
- Update `lockfileVersion` to `v2` in `package-lock.json [#1022](https://github.com/actions/toolkit/pull/1022)
|
||||
|
||||
### 1.0.11
|
||||
|
||||
- Fix file downloads > 2GB([issue](https://github.com/actions/cache/issues/773))
|
||||
|
||||
### 2.0.0
|
||||
|
||||
- Added support to check if Actions cache service feature is available or not [#1028](https://github.com/actions/toolkit/pull/1028)
|
||||
|
||||
### 2.0.3
|
||||
|
||||
- Update to v2.0.0 of `@actions/http-client`
|
||||
|
||||
### 2.0.4
|
||||
|
||||
- Update to v2.0.1 of `@actions/http-client` [#1087](https://github.com/actions/toolkit/pull/1087)
|
||||
|
||||
### 2.0.5
|
||||
|
||||
- Fix to avoid saving empty cache when no files are available for caching. ([issue](https://github.com/actions/cache/issues/624))
|
||||
|
||||
### 2.0.6
|
||||
|
||||
- Fix `Tar failed with error: The process '/usr/bin/tar' failed with exit code 1` issue when temp directory where tar is getting created is actually the subdirectory of the path mentioned by the user for caching. ([issue](https://github.com/actions/cache/issues/689))
|
||||
|
||||
### 3.0.0
|
||||
|
||||
- Updated actions/cache to suppress Actions cache server error and log warning for those error [#1122](https://github.com/actions/toolkit/pull/1122)
|
||||
|
||||
### 3.0.1
|
||||
|
||||
- Fix [#833](https://github.com/actions/cache/issues/833) - cache doesn't work with github workspace directory.
|
||||
- Fix [#809](https://github.com/actions/cache/issues/809) `zstd -d: no such file or directory` error on AWS self-hosted runners.
|
||||
|
||||
### 3.0.2
|
||||
|
||||
- Added 1 hour timeout for the download stuck issue [#810](https://github.com/actions/cache/issues/810).
|
||||
|
||||
### 3.0.3
|
||||
|
||||
- Bug fixes for download stuck issue [#810](https://github.com/actions/cache/issues/810).
|
||||
|
||||
### 3.0.4
|
||||
|
||||
- Fix zstd not working for windows on gnu tar in issues [#888](https://github.com/actions/cache/issues/888) and [#891](https://github.com/actions/cache/issues/891).
|
||||
- Allowing users to provide a custom timeout as input for aborting download of a cache segment using an environment variable `SEGMENT_DOWNLOAD_TIMEOUT_MINS`. Default is 60 minutes.
|
||||
|
||||
### 3.0.5
|
||||
|
||||
- Update `@actions/cache` to use `@actions/core@^1.10.0`
|
||||
|
||||
### 3.0.6
|
||||
|
||||
- Added `@azure/abort-controller` to dependencies to fix compatibility issue with ESM [#1208](https://github.com/actions/toolkit/issues/1208)
|
||||
|
||||
### 3.1.0-beta.1
|
||||
|
||||
- Update actions/cache on windows to use gnu tar and zstd by default and fallback to bsdtar and zstd if gnu tar is not available. ([issue](https://github.com/actions/cache/issues/984))
|
||||
|
||||
### 3.1.0-beta.2
|
||||
|
||||
- Added support for fallback to gzip to restore old caches on windows.
|
||||
|
||||
### 3.1.0-beta.3
|
||||
|
||||
- Bug Fixes for fallback to gzip to restore old caches on windows and bsdtar if gnutar is not available.
|
||||
|
||||
### 3.1.0
|
||||
|
||||
- Update actions/cache on windows to use gnu tar and zstd by default
|
||||
- Update actions/cache on windows to fallback to bsdtar and zstd if gnu tar is not available.
|
||||
- Added support for fallback to gzip to restore old caches on windows.
|
||||
|
||||
### 3.1.1
|
||||
|
||||
- Reverted changes in 3.1.0 to fix issue with symlink restoration on windows.
|
||||
- Added support for verbose logging about cache version during cache miss.
|
||||
|
||||
### 3.1.2
|
||||
|
||||
- Fix issue with symlink restoration on windows.
|
||||
|
||||
### 3.1.3
|
||||
|
||||
- Fix to prevent from setting MYSYS environement variable globally [#1329](https://github.com/actions/toolkit/pull/1329).
|
||||
|
||||
### 3.1.4
|
||||
|
||||
- Fix zstd not being used due to `zstd --version` output change in zstd 1.5.4 release. See [#1353](https://github.com/actions/toolkit/pull/1353).
|
||||
|
||||
### 3.2.0
|
||||
|
||||
- Add `lookupOnly` to cache restore `DownloadOptions`.
|
||||
|
||||
### 3.2.1
|
||||
|
||||
- Updated @azure/storage-blob to `v12.13.0`
|
||||
@@ -1,5 +0,0 @@
|
||||
name: 'Set env variables'
|
||||
description: 'Sets certain env variables so that e2e restore and save cache can be tested in a shell'
|
||||
runs:
|
||||
using: 'node12'
|
||||
main: 'index.js'
|
||||
@@ -1 +0,0 @@
|
||||
hello world
|
||||
-14
@@ -1,14 +0,0 @@
|
||||
// Certain env variables are not set by default in a shell context and are only available in a node context from a running action
|
||||
// In order to be able to restore and save cache e2e in a shell when running CI tests, we need these env variables set
|
||||
const fs = require('fs');
|
||||
const os = require('os');
|
||||
const filePath = process.env[`GITHUB_ENV`]
|
||||
fs.appendFileSync(filePath, `ACTIONS_RUNTIME_TOKEN=${process.env.ACTIONS_RUNTIME_TOKEN}${os.EOL}`, {
|
||||
encoding: 'utf8'
|
||||
})
|
||||
fs.appendFileSync(filePath, `ACTIONS_CACHE_URL=${process.env.ACTIONS_CACHE_URL}${os.EOL}`, {
|
||||
encoding: 'utf8'
|
||||
})
|
||||
fs.appendFileSync(filePath, `GITHUB_RUN_ID=${process.env.GITHUB_RUN_ID}${os.EOL}`, {
|
||||
encoding: 'utf8'
|
||||
})
|
||||
-14
@@ -1,14 +0,0 @@
|
||||
import * as cache from '../src/cache'
|
||||
|
||||
test('isFeatureAvailable returns true if server url is set', () => {
|
||||
try {
|
||||
process.env['ACTIONS_CACHE_URL'] = 'http://cache.com'
|
||||
expect(cache.isFeatureAvailable()).toBe(true)
|
||||
} finally {
|
||||
delete process.env['ACTIONS_CACHE_URL']
|
||||
}
|
||||
})
|
||||
|
||||
test('isFeatureAvailable returns false if server url is not set', () => {
|
||||
expect(cache.isFeatureAvailable()).toBe(false)
|
||||
})
|
||||
-152
@@ -1,152 +0,0 @@
|
||||
import {downloadCache, getCacheVersion} from '../src/internal/cacheHttpClient'
|
||||
import {CompressionMethod} from '../src/internal/constants'
|
||||
import * as downloadUtils from '../src/internal/downloadUtils'
|
||||
import {DownloadOptions, getDownloadOptions} from '../src/options'
|
||||
|
||||
jest.mock('../src/internal/downloadUtils')
|
||||
|
||||
test('getCacheVersion with one path returns version', async () => {
|
||||
const paths = ['node_modules']
|
||||
const result = getCacheVersion(paths, undefined, true)
|
||||
expect(result).toEqual(
|
||||
'b3e0c6cb5ecf32614eeb2997d905b9c297046d7cbf69062698f25b14b4cb0985'
|
||||
)
|
||||
})
|
||||
|
||||
test('getCacheVersion with multiple paths returns version', async () => {
|
||||
const paths = ['node_modules', 'dist']
|
||||
const result = getCacheVersion(paths, undefined, true)
|
||||
expect(result).toEqual(
|
||||
'165c3053bc646bf0d4fac17b1f5731caca6fe38e0e464715c0c3c6b6318bf436'
|
||||
)
|
||||
})
|
||||
|
||||
test('getCacheVersion with zstd compression returns version', async () => {
|
||||
const paths = ['node_modules']
|
||||
const result = getCacheVersion(paths, CompressionMethod.Zstd, true)
|
||||
|
||||
expect(result).toEqual(
|
||||
'273877e14fd65d270b87a198edbfa2db5a43de567c9a548d2a2505b408befe24'
|
||||
)
|
||||
})
|
||||
|
||||
test('getCacheVersion with gzip compression returns version', async () => {
|
||||
const paths = ['node_modules']
|
||||
const result = getCacheVersion(paths, CompressionMethod.Gzip, true)
|
||||
|
||||
expect(result).toEqual(
|
||||
'470e252814dbffc9524891b17cf4e5749b26c1b5026e63dd3f00972db2393117'
|
||||
)
|
||||
})
|
||||
|
||||
test('getCacheVersion with enableCrossOsArchive as false returns version on windows', async () => {
|
||||
if (process.platform === 'win32') {
|
||||
const paths = ['node_modules']
|
||||
const result = getCacheVersion(paths)
|
||||
|
||||
expect(result).toEqual(
|
||||
'2db19d6596dc34f51f0043120148827a264863f5c6ac857569c2af7119bad14e'
|
||||
)
|
||||
}
|
||||
})
|
||||
|
||||
test('downloadCache uses http-client for non-Azure URLs', async () => {
|
||||
const downloadCacheHttpClientMock = jest.spyOn(
|
||||
downloadUtils,
|
||||
'downloadCacheHttpClient'
|
||||
)
|
||||
const downloadCacheStorageSDKMock = jest.spyOn(
|
||||
downloadUtils,
|
||||
'downloadCacheStorageSDK'
|
||||
)
|
||||
|
||||
const archiveLocation = 'http://www.actionscache.test/download'
|
||||
const archivePath = '/foo/bar'
|
||||
|
||||
await downloadCache(archiveLocation, archivePath)
|
||||
|
||||
expect(downloadCacheHttpClientMock).toHaveBeenCalledTimes(1)
|
||||
expect(downloadCacheHttpClientMock).toHaveBeenCalledWith(
|
||||
archiveLocation,
|
||||
archivePath
|
||||
)
|
||||
|
||||
expect(downloadCacheStorageSDKMock).toHaveBeenCalledTimes(0)
|
||||
})
|
||||
|
||||
test('downloadCache uses storage SDK for Azure storage URLs', async () => {
|
||||
const downloadCacheHttpClientMock = jest.spyOn(
|
||||
downloadUtils,
|
||||
'downloadCacheHttpClient'
|
||||
)
|
||||
const downloadCacheStorageSDKMock = jest.spyOn(
|
||||
downloadUtils,
|
||||
'downloadCacheStorageSDK'
|
||||
)
|
||||
|
||||
const archiveLocation = 'http://foo.blob.core.windows.net/bar/baz'
|
||||
const archivePath = '/foo/bar'
|
||||
|
||||
await downloadCache(archiveLocation, archivePath)
|
||||
|
||||
expect(downloadCacheStorageSDKMock).toHaveBeenCalledTimes(1)
|
||||
expect(downloadCacheStorageSDKMock).toHaveBeenCalledWith(
|
||||
archiveLocation,
|
||||
archivePath,
|
||||
getDownloadOptions()
|
||||
)
|
||||
|
||||
expect(downloadCacheHttpClientMock).toHaveBeenCalledTimes(0)
|
||||
})
|
||||
|
||||
test('downloadCache passes options to download methods', async () => {
|
||||
const downloadCacheHttpClientMock = jest.spyOn(
|
||||
downloadUtils,
|
||||
'downloadCacheHttpClient'
|
||||
)
|
||||
const downloadCacheStorageSDKMock = jest.spyOn(
|
||||
downloadUtils,
|
||||
'downloadCacheStorageSDK'
|
||||
)
|
||||
|
||||
const archiveLocation = 'http://foo.blob.core.windows.net/bar/baz'
|
||||
const archivePath = '/foo/bar'
|
||||
const options: DownloadOptions = {downloadConcurrency: 4}
|
||||
|
||||
await downloadCache(archiveLocation, archivePath, options)
|
||||
|
||||
expect(downloadCacheStorageSDKMock).toHaveBeenCalledTimes(1)
|
||||
expect(downloadCacheStorageSDKMock).toHaveBeenCalled()
|
||||
expect(downloadCacheStorageSDKMock).toHaveBeenCalledWith(
|
||||
archiveLocation,
|
||||
archivePath,
|
||||
getDownloadOptions(options)
|
||||
)
|
||||
|
||||
expect(downloadCacheHttpClientMock).toHaveBeenCalledTimes(0)
|
||||
})
|
||||
|
||||
test('downloadCache uses http-client when overridden', async () => {
|
||||
const downloadCacheHttpClientMock = jest.spyOn(
|
||||
downloadUtils,
|
||||
'downloadCacheHttpClient'
|
||||
)
|
||||
const downloadCacheStorageSDKMock = jest.spyOn(
|
||||
downloadUtils,
|
||||
'downloadCacheStorageSDK'
|
||||
)
|
||||
|
||||
const archiveLocation = 'http://foo.blob.core.windows.net/bar/baz'
|
||||
const archivePath = '/foo/bar'
|
||||
const options: DownloadOptions = {useAzureSdk: false}
|
||||
|
||||
await downloadCache(archiveLocation, archivePath, options)
|
||||
|
||||
expect(downloadCacheHttpClientMock).toHaveBeenCalledTimes(1)
|
||||
expect(downloadCacheHttpClientMock).toHaveBeenCalledWith(
|
||||
archiveLocation,
|
||||
archivePath
|
||||
)
|
||||
|
||||
expect(downloadCacheStorageSDKMock).toHaveBeenCalledTimes(0)
|
||||
})
|
||||
-40
@@ -1,40 +0,0 @@
|
||||
import {promises as fs} from 'fs'
|
||||
import * as path from 'path'
|
||||
import * as cacheUtils from '../src/internal/cacheUtils'
|
||||
|
||||
test('getArchiveFileSizeInBytes returns file size', () => {
|
||||
const filePath = path.join(__dirname, '__fixtures__', 'helloWorld.txt')
|
||||
|
||||
const size = cacheUtils.getArchiveFileSizeInBytes(filePath)
|
||||
|
||||
expect(size).toBe(11)
|
||||
})
|
||||
|
||||
test('unlinkFile unlinks file', async () => {
|
||||
const testDirectory = await fs.mkdtemp('unlinkFileTest')
|
||||
const testFile = path.join(testDirectory, 'test.txt')
|
||||
await fs.writeFile(testFile, 'hello world')
|
||||
|
||||
await expect(fs.stat(testFile)).resolves.not.toThrow()
|
||||
|
||||
await cacheUtils.unlinkFile(testFile)
|
||||
|
||||
// This should throw as testFile should not exist
|
||||
await expect(fs.stat(testFile)).rejects.toThrow()
|
||||
|
||||
await fs.rmdir(testDirectory)
|
||||
})
|
||||
|
||||
test('assertDefined throws if undefined', () => {
|
||||
expect(() => cacheUtils.assertDefined('test', undefined)).toThrowError()
|
||||
})
|
||||
|
||||
test('assertDefined returns value', () => {
|
||||
expect(cacheUtils.assertDefined('test', 5)).toBe(5)
|
||||
})
|
||||
|
||||
test('resolvePaths works on github workspace directory', async () => {
|
||||
const workspace = process.env['GITHUB_WORKSPACE'] ?? '.'
|
||||
const paths = await cacheUtils.resolvePaths([workspace])
|
||||
expect(paths.length).toBeGreaterThan(0)
|
||||
})
|
||||
-17
@@ -1,17 +0,0 @@
|
||||
#!/bin/sh
|
||||
|
||||
# Validate args
|
||||
prefix="$1"
|
||||
if [ -z "$prefix" ]; then
|
||||
echo "Must supply prefix argument"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
path="$2"
|
||||
if [ -z "$path" ]; then
|
||||
echo "Must supply path argument"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
mkdir -p $path
|
||||
echo "$prefix $GITHUB_RUN_ID" > $path/test-file.txt
|
||||
-160
@@ -1,160 +0,0 @@
|
||||
import * as core from '@actions/core'
|
||||
import {DownloadProgress} from '../src/internal/downloadUtils'
|
||||
|
||||
test('download progress tracked correctly', () => {
|
||||
const progress = new DownloadProgress(1000)
|
||||
|
||||
expect(progress.contentLength).toBe(1000)
|
||||
expect(progress.receivedBytes).toBe(0)
|
||||
expect(progress.segmentIndex).toBe(0)
|
||||
expect(progress.segmentOffset).toBe(0)
|
||||
expect(progress.segmentSize).toBe(0)
|
||||
expect(progress.displayedComplete).toBe(false)
|
||||
expect(progress.timeoutHandle).toBeUndefined()
|
||||
expect(progress.getTransferredBytes()).toBe(0)
|
||||
expect(progress.isDone()).toBe(false)
|
||||
|
||||
progress.nextSegment(500)
|
||||
|
||||
expect(progress.contentLength).toBe(1000)
|
||||
expect(progress.receivedBytes).toBe(0)
|
||||
expect(progress.segmentIndex).toBe(1)
|
||||
expect(progress.segmentOffset).toBe(0)
|
||||
expect(progress.segmentSize).toBe(500)
|
||||
expect(progress.displayedComplete).toBe(false)
|
||||
expect(progress.timeoutHandle).toBeUndefined()
|
||||
expect(progress.getTransferredBytes()).toBe(0)
|
||||
expect(progress.isDone()).toBe(false)
|
||||
|
||||
progress.setReceivedBytes(250)
|
||||
|
||||
expect(progress.contentLength).toBe(1000)
|
||||
expect(progress.receivedBytes).toBe(250)
|
||||
expect(progress.segmentIndex).toBe(1)
|
||||
expect(progress.segmentOffset).toBe(0)
|
||||
expect(progress.segmentSize).toBe(500)
|
||||
expect(progress.displayedComplete).toBe(false)
|
||||
expect(progress.timeoutHandle).toBeUndefined()
|
||||
expect(progress.getTransferredBytes()).toBe(250)
|
||||
expect(progress.isDone()).toBe(false)
|
||||
|
||||
progress.setReceivedBytes(500)
|
||||
|
||||
expect(progress.contentLength).toBe(1000)
|
||||
expect(progress.receivedBytes).toBe(500)
|
||||
expect(progress.segmentIndex).toBe(1)
|
||||
expect(progress.segmentOffset).toBe(0)
|
||||
expect(progress.segmentSize).toBe(500)
|
||||
expect(progress.displayedComplete).toBe(false)
|
||||
expect(progress.timeoutHandle).toBeUndefined()
|
||||
expect(progress.getTransferredBytes()).toBe(500)
|
||||
expect(progress.isDone()).toBe(false)
|
||||
|
||||
progress.nextSegment(500)
|
||||
|
||||
expect(progress.contentLength).toBe(1000)
|
||||
expect(progress.receivedBytes).toBe(0)
|
||||
expect(progress.segmentIndex).toBe(2)
|
||||
expect(progress.segmentOffset).toBe(500)
|
||||
expect(progress.segmentSize).toBe(500)
|
||||
expect(progress.displayedComplete).toBe(false)
|
||||
expect(progress.timeoutHandle).toBeUndefined()
|
||||
expect(progress.getTransferredBytes()).toBe(500)
|
||||
expect(progress.isDone()).toBe(false)
|
||||
|
||||
progress.setReceivedBytes(250)
|
||||
|
||||
expect(progress.contentLength).toBe(1000)
|
||||
expect(progress.receivedBytes).toBe(250)
|
||||
expect(progress.segmentIndex).toBe(2)
|
||||
expect(progress.segmentOffset).toBe(500)
|
||||
expect(progress.segmentSize).toBe(500)
|
||||
expect(progress.displayedComplete).toBe(false)
|
||||
expect(progress.timeoutHandle).toBeUndefined()
|
||||
expect(progress.getTransferredBytes()).toBe(750)
|
||||
expect(progress.isDone()).toBe(false)
|
||||
|
||||
progress.setReceivedBytes(500)
|
||||
|
||||
expect(progress.contentLength).toBe(1000)
|
||||
expect(progress.receivedBytes).toBe(500)
|
||||
expect(progress.segmentIndex).toBe(2)
|
||||
expect(progress.segmentOffset).toBe(500)
|
||||
expect(progress.segmentSize).toBe(500)
|
||||
expect(progress.displayedComplete).toBe(false)
|
||||
expect(progress.timeoutHandle).toBeUndefined()
|
||||
expect(progress.getTransferredBytes()).toBe(1000)
|
||||
expect(progress.isDone()).toBe(true)
|
||||
})
|
||||
|
||||
test('display timer works correctly', done => {
|
||||
const progress = new DownloadProgress(1000)
|
||||
|
||||
const infoMock = jest.spyOn(core, 'info')
|
||||
infoMock.mockImplementation(() => {})
|
||||
|
||||
const check = (): void => {
|
||||
expect(infoMock).toHaveBeenLastCalledWith(
|
||||
expect.stringContaining('Received 500 of 1000')
|
||||
)
|
||||
}
|
||||
|
||||
// Validate no further updates are displayed after stopping the timer.
|
||||
const test2 = (): void => {
|
||||
check()
|
||||
expect(progress.timeoutHandle).toBeUndefined()
|
||||
done()
|
||||
}
|
||||
|
||||
// Validate the progress is displayed, stop the timer, and call test2.
|
||||
const test1 = (): void => {
|
||||
check()
|
||||
|
||||
progress.stopDisplayTimer()
|
||||
progress.setReceivedBytes(1000)
|
||||
|
||||
setTimeout(() => test2(), 500)
|
||||
}
|
||||
|
||||
// Start the timer, update the received bytes, and call test1.
|
||||
const start = (): void => {
|
||||
progress.startDisplayTimer(10)
|
||||
expect(progress.timeoutHandle).toBeDefined()
|
||||
|
||||
progress.setReceivedBytes(500)
|
||||
|
||||
setTimeout(() => test1(), 500)
|
||||
}
|
||||
|
||||
start()
|
||||
})
|
||||
|
||||
test('display does not print completed line twice', () => {
|
||||
const progress = new DownloadProgress(1000)
|
||||
|
||||
const infoMock = jest.spyOn(core, 'info')
|
||||
infoMock.mockImplementation(() => {})
|
||||
|
||||
progress.display()
|
||||
|
||||
expect(progress.displayedComplete).toBe(false)
|
||||
expect(infoMock).toHaveBeenCalledTimes(1)
|
||||
|
||||
progress.nextSegment(1000)
|
||||
progress.setReceivedBytes(500)
|
||||
progress.display()
|
||||
|
||||
expect(progress.displayedComplete).toBe(false)
|
||||
expect(infoMock).toHaveBeenCalledTimes(2)
|
||||
|
||||
progress.setReceivedBytes(1000)
|
||||
progress.display()
|
||||
|
||||
expect(progress.displayedComplete).toBe(true)
|
||||
expect(infoMock).toHaveBeenCalledTimes(3)
|
||||
|
||||
progress.display()
|
||||
|
||||
expect(progress.displayedComplete).toBe(true)
|
||||
expect(infoMock).toHaveBeenCalledTimes(3)
|
||||
})
|
||||
-80
@@ -1,80 +0,0 @@
|
||||
import {
|
||||
DownloadOptions,
|
||||
UploadOptions,
|
||||
getDownloadOptions,
|
||||
getUploadOptions
|
||||
} from '../src/options'
|
||||
|
||||
const useAzureSdk = true
|
||||
const downloadConcurrency = 8
|
||||
const timeoutInMs = 30000
|
||||
const segmentTimeoutInMs = 600000
|
||||
const lookupOnly = false
|
||||
const uploadConcurrency = 4
|
||||
const uploadChunkSize = 32 * 1024 * 1024
|
||||
|
||||
test('getDownloadOptions sets defaults', async () => {
|
||||
const actualOptions = getDownloadOptions()
|
||||
|
||||
expect(actualOptions).toEqual({
|
||||
useAzureSdk,
|
||||
downloadConcurrency,
|
||||
timeoutInMs,
|
||||
segmentTimeoutInMs,
|
||||
lookupOnly
|
||||
})
|
||||
})
|
||||
|
||||
test('getDownloadOptions overrides all settings', async () => {
|
||||
const expectedOptions: DownloadOptions = {
|
||||
useAzureSdk: false,
|
||||
downloadConcurrency: 14,
|
||||
timeoutInMs: 20000,
|
||||
segmentTimeoutInMs: 3600000,
|
||||
lookupOnly: true
|
||||
}
|
||||
|
||||
const actualOptions = getDownloadOptions(expectedOptions)
|
||||
|
||||
expect(actualOptions).toEqual(expectedOptions)
|
||||
})
|
||||
|
||||
test('getUploadOptions sets defaults', async () => {
|
||||
const actualOptions = getUploadOptions()
|
||||
|
||||
expect(actualOptions).toEqual({
|
||||
uploadConcurrency,
|
||||
uploadChunkSize
|
||||
})
|
||||
})
|
||||
|
||||
test('getUploadOptions overrides all settings', async () => {
|
||||
const expectedOptions: UploadOptions = {
|
||||
uploadConcurrency: 2,
|
||||
uploadChunkSize: 16 * 1024 * 1024
|
||||
}
|
||||
|
||||
const actualOptions = getUploadOptions(expectedOptions)
|
||||
|
||||
expect(actualOptions).toEqual(expectedOptions)
|
||||
})
|
||||
|
||||
test('getDownloadOptions overrides download timeout minutes', async () => {
|
||||
const expectedOptions: DownloadOptions = {
|
||||
useAzureSdk: false,
|
||||
downloadConcurrency: 14,
|
||||
timeoutInMs: 20000,
|
||||
segmentTimeoutInMs: 3600000,
|
||||
lookupOnly: true
|
||||
}
|
||||
process.env.SEGMENT_DOWNLOAD_TIMEOUT_MINS = '10'
|
||||
const actualOptions = getDownloadOptions(expectedOptions)
|
||||
|
||||
expect(actualOptions.useAzureSdk).toEqual(expectedOptions.useAzureSdk)
|
||||
expect(actualOptions.downloadConcurrency).toEqual(
|
||||
expectedOptions.downloadConcurrency
|
||||
)
|
||||
expect(actualOptions.timeoutInMs).toEqual(expectedOptions.timeoutInMs)
|
||||
expect(actualOptions.segmentTimeoutInMs).toEqual(600000)
|
||||
expect(actualOptions.lookupOnly).toEqual(expectedOptions.lookupOnly)
|
||||
})
|
||||
-179
@@ -1,179 +0,0 @@
|
||||
import {retry, retryTypedResponse} from '../src/internal/requestUtils'
|
||||
import {HttpClientError} from '@actions/http-client'
|
||||
import * as requestUtils from '../src/internal/requestUtils'
|
||||
|
||||
interface ITestResponse {
|
||||
statusCode: number
|
||||
result: string | null
|
||||
error: Error | null
|
||||
}
|
||||
|
||||
function TestResponse(
|
||||
action: number | Error,
|
||||
result: string | null = null
|
||||
): ITestResponse {
|
||||
if (action instanceof Error) {
|
||||
return {
|
||||
statusCode: -1,
|
||||
result,
|
||||
error: action
|
||||
}
|
||||
} else {
|
||||
return {
|
||||
statusCode: action,
|
||||
result,
|
||||
error: null
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
async function handleResponse(
|
||||
response: ITestResponse | undefined
|
||||
): Promise<ITestResponse> {
|
||||
if (!response) {
|
||||
fail('Retry method called too many times')
|
||||
}
|
||||
|
||||
if (response.error) {
|
||||
throw response.error
|
||||
} else {
|
||||
return Promise.resolve(response)
|
||||
}
|
||||
}
|
||||
|
||||
async function testRetryExpectingResult(
|
||||
responses: ITestResponse[],
|
||||
expectedResult: string | null
|
||||
): Promise<void> {
|
||||
responses = responses.reverse() // Reverse responses since we pop from end
|
||||
|
||||
const actualResult = await retry(
|
||||
'test',
|
||||
async () => handleResponse(responses.pop()),
|
||||
(response: ITestResponse) => response.statusCode,
|
||||
2, // maxAttempts
|
||||
0 // delay
|
||||
)
|
||||
|
||||
expect(actualResult.result).toEqual(expectedResult)
|
||||
}
|
||||
|
||||
async function testRetryConvertingErrorToResult(
|
||||
responses: ITestResponse[],
|
||||
expectedStatus: number,
|
||||
expectedResult: string | null
|
||||
): Promise<void> {
|
||||
responses = responses.reverse() // Reverse responses since we pop from end
|
||||
|
||||
const actualResult = await retry(
|
||||
'test',
|
||||
async () => handleResponse(responses.pop()),
|
||||
(response: ITestResponse) => response.statusCode,
|
||||
2, // maxAttempts
|
||||
0, // delay
|
||||
(e: Error) => {
|
||||
if (e instanceof HttpClientError) {
|
||||
return {
|
||||
statusCode: e.statusCode,
|
||||
result: null,
|
||||
error: null
|
||||
}
|
||||
}
|
||||
}
|
||||
)
|
||||
|
||||
expect(actualResult.statusCode).toEqual(expectedStatus)
|
||||
expect(actualResult.result).toEqual(expectedResult)
|
||||
}
|
||||
|
||||
async function testRetryExpectingError(
|
||||
responses: ITestResponse[]
|
||||
): Promise<void> {
|
||||
responses = responses.reverse() // Reverse responses since we pop from end
|
||||
|
||||
expect(
|
||||
retry(
|
||||
'test',
|
||||
async () => handleResponse(responses.pop()),
|
||||
(response: ITestResponse) => response.statusCode,
|
||||
2, // maxAttempts,
|
||||
0 // delay
|
||||
)
|
||||
).rejects.toBeInstanceOf(Error)
|
||||
}
|
||||
|
||||
test('retry works on successful response', async () => {
|
||||
await testRetryExpectingResult([TestResponse(200, 'Ok')], 'Ok')
|
||||
})
|
||||
|
||||
test('retry works after retryable status code', async () => {
|
||||
await testRetryExpectingResult(
|
||||
[TestResponse(503), TestResponse(200, 'Ok')],
|
||||
'Ok'
|
||||
)
|
||||
})
|
||||
|
||||
test('retry fails after exhausting retries', async () => {
|
||||
await testRetryExpectingError([
|
||||
TestResponse(503),
|
||||
TestResponse(503),
|
||||
TestResponse(200, 'Ok')
|
||||
])
|
||||
})
|
||||
|
||||
test('retry fails after non-retryable status code', async () => {
|
||||
await testRetryExpectingError([TestResponse(500), TestResponse(200, 'Ok')])
|
||||
})
|
||||
|
||||
test('retry works after error', async () => {
|
||||
await testRetryExpectingResult(
|
||||
[TestResponse(new Error('Test error')), TestResponse(200, 'Ok')],
|
||||
'Ok'
|
||||
)
|
||||
})
|
||||
|
||||
test('retry returns after client error', async () => {
|
||||
await testRetryExpectingResult(
|
||||
[TestResponse(400), TestResponse(200, 'Ok')],
|
||||
null
|
||||
)
|
||||
})
|
||||
|
||||
test('retry converts errors to response object', async () => {
|
||||
await testRetryConvertingErrorToResult(
|
||||
[TestResponse(new HttpClientError('Test error', 409))],
|
||||
409,
|
||||
null
|
||||
)
|
||||
})
|
||||
|
||||
test('retryTypedResponse gives an error with error message', async () => {
|
||||
const httpClientError = new HttpClientError(
|
||||
'The cache filesize must be between 0 and 10 * 1024 * 1024 bytes',
|
||||
400
|
||||
)
|
||||
jest.spyOn(requestUtils, 'retry').mockReturnValue(
|
||||
new Promise(resolve => {
|
||||
resolve(httpClientError)
|
||||
})
|
||||
)
|
||||
try {
|
||||
await retryTypedResponse<string>(
|
||||
'reserveCache',
|
||||
async () =>
|
||||
new Promise(resolve => {
|
||||
resolve({
|
||||
statusCode: 400,
|
||||
result: '',
|
||||
headers: {},
|
||||
error: httpClientError
|
||||
})
|
||||
})
|
||||
)
|
||||
} catch (error) {
|
||||
expect(error).toHaveProperty(
|
||||
'message',
|
||||
'The cache filesize must be between 0 and 10 * 1024 * 1024 bytes'
|
||||
)
|
||||
}
|
||||
})
|
||||
-314
@@ -1,314 +0,0 @@
|
||||
import * as core from '@actions/core'
|
||||
import * as path from 'path'
|
||||
import {restoreCache} from '../src/cache'
|
||||
import * as cacheHttpClient from '../src/internal/cacheHttpClient'
|
||||
import * as cacheUtils from '../src/internal/cacheUtils'
|
||||
import {CacheFilename, CompressionMethod} from '../src/internal/constants'
|
||||
import {ArtifactCacheEntry} from '../src/internal/contracts'
|
||||
import * as tar from '../src/internal/tar'
|
||||
|
||||
jest.mock('../src/internal/cacheHttpClient')
|
||||
jest.mock('../src/internal/cacheUtils')
|
||||
jest.mock('../src/internal/tar')
|
||||
|
||||
beforeAll(() => {
|
||||
jest.spyOn(console, 'log').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'debug').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'info').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'warning').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'error').mockImplementation(() => {})
|
||||
|
||||
jest.spyOn(cacheUtils, 'getCacheFileName').mockImplementation(cm => {
|
||||
const actualUtils = jest.requireActual('../src/internal/cacheUtils')
|
||||
return actualUtils.getCacheFileName(cm)
|
||||
})
|
||||
})
|
||||
|
||||
test('restore with no path should fail', async () => {
|
||||
const paths: string[] = []
|
||||
const key = 'node-test'
|
||||
await expect(restoreCache(paths, key)).rejects.toThrowError(
|
||||
`Path Validation Error: At least one directory or file path is required`
|
||||
)
|
||||
})
|
||||
|
||||
test('restore with too many keys should fail', async () => {
|
||||
const paths = ['node_modules']
|
||||
const key = 'node-test'
|
||||
const restoreKeys = [...Array(20).keys()].map(x => x.toString())
|
||||
await expect(restoreCache(paths, key, restoreKeys)).rejects.toThrowError(
|
||||
`Key Validation Error: Keys are limited to a maximum of 10.`
|
||||
)
|
||||
})
|
||||
|
||||
test('restore with large key should fail', async () => {
|
||||
const paths = ['node_modules']
|
||||
const key = 'foo'.repeat(512) // Over the 512 character limit
|
||||
await expect(restoreCache(paths, key)).rejects.toThrowError(
|
||||
`Key Validation Error: ${key} cannot be larger than 512 characters.`
|
||||
)
|
||||
})
|
||||
|
||||
test('restore with invalid key should fail', async () => {
|
||||
const paths = ['node_modules']
|
||||
const key = 'comma,comma'
|
||||
await expect(restoreCache(paths, key)).rejects.toThrowError(
|
||||
`Key Validation Error: ${key} cannot contain commas.`
|
||||
)
|
||||
})
|
||||
|
||||
test('restore with no cache found', async () => {
|
||||
const paths = ['node_modules']
|
||||
const key = 'node-test'
|
||||
|
||||
jest.spyOn(cacheHttpClient, 'getCacheEntry').mockImplementation(async () => {
|
||||
return Promise.resolve(null)
|
||||
})
|
||||
|
||||
const cacheKey = await restoreCache(paths, key)
|
||||
|
||||
expect(cacheKey).toBe(undefined)
|
||||
})
|
||||
|
||||
test('restore with server error should fail', async () => {
|
||||
const paths = ['node_modules']
|
||||
const key = 'node-test'
|
||||
const logWarningMock = jest.spyOn(core, 'warning')
|
||||
|
||||
jest.spyOn(cacheHttpClient, 'getCacheEntry').mockImplementation(() => {
|
||||
throw new Error('HTTP Error Occurred')
|
||||
})
|
||||
|
||||
const cacheKey = await restoreCache(paths, key)
|
||||
expect(cacheKey).toBe(undefined)
|
||||
expect(logWarningMock).toHaveBeenCalledTimes(1)
|
||||
expect(logWarningMock).toHaveBeenCalledWith(
|
||||
'Failed to restore: HTTP Error Occurred'
|
||||
)
|
||||
})
|
||||
|
||||
test('restore with restore keys and no cache found', async () => {
|
||||
const paths = ['node_modules']
|
||||
const key = 'node-test'
|
||||
const restoreKey = 'node-'
|
||||
|
||||
jest.spyOn(cacheHttpClient, 'getCacheEntry').mockImplementation(async () => {
|
||||
return Promise.resolve(null)
|
||||
})
|
||||
|
||||
const cacheKey = await restoreCache(paths, key, [restoreKey])
|
||||
|
||||
expect(cacheKey).toBe(undefined)
|
||||
})
|
||||
|
||||
test('restore with gzip compressed cache found', async () => {
|
||||
const paths = ['node_modules']
|
||||
const key = 'node-test'
|
||||
|
||||
const cacheEntry: ArtifactCacheEntry = {
|
||||
cacheKey: key,
|
||||
scope: 'refs/heads/main',
|
||||
archiveLocation: 'www.actionscache.test/download'
|
||||
}
|
||||
const getCacheMock = jest.spyOn(cacheHttpClient, 'getCacheEntry')
|
||||
getCacheMock.mockImplementation(async () => {
|
||||
return Promise.resolve(cacheEntry)
|
||||
})
|
||||
|
||||
const tempPath = '/foo/bar'
|
||||
|
||||
const createTempDirectoryMock = jest.spyOn(cacheUtils, 'createTempDirectory')
|
||||
createTempDirectoryMock.mockImplementation(async () => {
|
||||
return Promise.resolve(tempPath)
|
||||
})
|
||||
|
||||
const archivePath = path.join(tempPath, CacheFilename.Gzip)
|
||||
const downloadCacheMock = jest.spyOn(cacheHttpClient, 'downloadCache')
|
||||
|
||||
const fileSize = 142
|
||||
const getArchiveFileSizeInBytesMock = jest
|
||||
.spyOn(cacheUtils, 'getArchiveFileSizeInBytes')
|
||||
.mockReturnValue(fileSize)
|
||||
|
||||
const extractTarMock = jest.spyOn(tar, 'extractTar')
|
||||
const unlinkFileMock = jest.spyOn(cacheUtils, 'unlinkFile')
|
||||
|
||||
const compression = CompressionMethod.Gzip
|
||||
const getCompressionMock = jest
|
||||
.spyOn(cacheUtils, 'getCompressionMethod')
|
||||
.mockReturnValue(Promise.resolve(compression))
|
||||
|
||||
const cacheKey = await restoreCache(paths, key)
|
||||
|
||||
expect(cacheKey).toBe(key)
|
||||
expect(getCacheMock).toHaveBeenCalledWith([key], paths, {
|
||||
compressionMethod: compression,
|
||||
enableCrossOsArchive: false
|
||||
})
|
||||
expect(createTempDirectoryMock).toHaveBeenCalledTimes(1)
|
||||
expect(downloadCacheMock).toHaveBeenCalledWith(
|
||||
cacheEntry.archiveLocation,
|
||||
archivePath,
|
||||
undefined
|
||||
)
|
||||
expect(getArchiveFileSizeInBytesMock).toHaveBeenCalledWith(archivePath)
|
||||
|
||||
expect(extractTarMock).toHaveBeenCalledTimes(1)
|
||||
expect(extractTarMock).toHaveBeenCalledWith(archivePath, compression)
|
||||
|
||||
expect(unlinkFileMock).toHaveBeenCalledTimes(1)
|
||||
expect(unlinkFileMock).toHaveBeenCalledWith(archivePath)
|
||||
|
||||
expect(getCompressionMock).toHaveBeenCalledTimes(1)
|
||||
})
|
||||
|
||||
test('restore with zstd compressed cache found', async () => {
|
||||
const paths = ['node_modules']
|
||||
const key = 'node-test'
|
||||
|
||||
const infoMock = jest.spyOn(core, 'info')
|
||||
|
||||
const cacheEntry: ArtifactCacheEntry = {
|
||||
cacheKey: key,
|
||||
scope: 'refs/heads/main',
|
||||
archiveLocation: 'www.actionscache.test/download'
|
||||
}
|
||||
const getCacheMock = jest.spyOn(cacheHttpClient, 'getCacheEntry')
|
||||
getCacheMock.mockImplementation(async () => {
|
||||
return Promise.resolve(cacheEntry)
|
||||
})
|
||||
const tempPath = '/foo/bar'
|
||||
|
||||
const createTempDirectoryMock = jest.spyOn(cacheUtils, 'createTempDirectory')
|
||||
createTempDirectoryMock.mockImplementation(async () => {
|
||||
return Promise.resolve(tempPath)
|
||||
})
|
||||
|
||||
const archivePath = path.join(tempPath, CacheFilename.Zstd)
|
||||
const downloadCacheMock = jest.spyOn(cacheHttpClient, 'downloadCache')
|
||||
|
||||
const fileSize = 62915000
|
||||
const getArchiveFileSizeInBytesMock = jest
|
||||
.spyOn(cacheUtils, 'getArchiveFileSizeInBytes')
|
||||
.mockReturnValue(fileSize)
|
||||
|
||||
const extractTarMock = jest.spyOn(tar, 'extractTar')
|
||||
const compression = CompressionMethod.Zstd
|
||||
const getCompressionMock = jest
|
||||
.spyOn(cacheUtils, 'getCompressionMethod')
|
||||
.mockReturnValue(Promise.resolve(compression))
|
||||
|
||||
const cacheKey = await restoreCache(paths, key)
|
||||
|
||||
expect(cacheKey).toBe(key)
|
||||
expect(getCacheMock).toHaveBeenCalledWith([key], paths, {
|
||||
compressionMethod: compression,
|
||||
enableCrossOsArchive: false
|
||||
})
|
||||
expect(createTempDirectoryMock).toHaveBeenCalledTimes(1)
|
||||
expect(downloadCacheMock).toHaveBeenCalledWith(
|
||||
cacheEntry.archiveLocation,
|
||||
archivePath,
|
||||
undefined
|
||||
)
|
||||
expect(getArchiveFileSizeInBytesMock).toHaveBeenCalledWith(archivePath)
|
||||
expect(infoMock).toHaveBeenCalledWith(`Cache Size: ~60 MB (62915000 B)`)
|
||||
|
||||
expect(extractTarMock).toHaveBeenCalledTimes(1)
|
||||
expect(extractTarMock).toHaveBeenCalledWith(archivePath, compression)
|
||||
expect(getCompressionMock).toHaveBeenCalledTimes(1)
|
||||
})
|
||||
|
||||
test('restore with cache found for restore key', async () => {
|
||||
const paths = ['node_modules']
|
||||
const key = 'node-test'
|
||||
const restoreKey = 'node-'
|
||||
|
||||
const infoMock = jest.spyOn(core, 'info')
|
||||
|
||||
const cacheEntry: ArtifactCacheEntry = {
|
||||
cacheKey: restoreKey,
|
||||
scope: 'refs/heads/main',
|
||||
archiveLocation: 'www.actionscache.test/download'
|
||||
}
|
||||
const getCacheMock = jest.spyOn(cacheHttpClient, 'getCacheEntry')
|
||||
getCacheMock.mockImplementation(async () => {
|
||||
return Promise.resolve(cacheEntry)
|
||||
})
|
||||
const tempPath = '/foo/bar'
|
||||
|
||||
const createTempDirectoryMock = jest.spyOn(cacheUtils, 'createTempDirectory')
|
||||
createTempDirectoryMock.mockImplementation(async () => {
|
||||
return Promise.resolve(tempPath)
|
||||
})
|
||||
|
||||
const archivePath = path.join(tempPath, CacheFilename.Zstd)
|
||||
const downloadCacheMock = jest.spyOn(cacheHttpClient, 'downloadCache')
|
||||
|
||||
const fileSize = 142
|
||||
const getArchiveFileSizeInBytesMock = jest
|
||||
.spyOn(cacheUtils, 'getArchiveFileSizeInBytes')
|
||||
.mockReturnValue(fileSize)
|
||||
|
||||
const extractTarMock = jest.spyOn(tar, 'extractTar')
|
||||
const compression = CompressionMethod.Zstd
|
||||
const getCompressionMock = jest
|
||||
.spyOn(cacheUtils, 'getCompressionMethod')
|
||||
.mockReturnValue(Promise.resolve(compression))
|
||||
|
||||
const cacheKey = await restoreCache(paths, key, [restoreKey])
|
||||
|
||||
expect(cacheKey).toBe(restoreKey)
|
||||
expect(getCacheMock).toHaveBeenCalledWith([key, restoreKey], paths, {
|
||||
compressionMethod: compression,
|
||||
enableCrossOsArchive: false
|
||||
})
|
||||
expect(createTempDirectoryMock).toHaveBeenCalledTimes(1)
|
||||
expect(downloadCacheMock).toHaveBeenCalledWith(
|
||||
cacheEntry.archiveLocation,
|
||||
archivePath,
|
||||
undefined
|
||||
)
|
||||
expect(getArchiveFileSizeInBytesMock).toHaveBeenCalledWith(archivePath)
|
||||
expect(infoMock).toHaveBeenCalledWith(`Cache Size: ~0 MB (142 B)`)
|
||||
|
||||
expect(extractTarMock).toHaveBeenCalledTimes(1)
|
||||
expect(extractTarMock).toHaveBeenCalledWith(archivePath, compression)
|
||||
expect(getCompressionMock).toHaveBeenCalledTimes(1)
|
||||
})
|
||||
|
||||
test('restore with dry run', async () => {
|
||||
const paths = ['node_modules']
|
||||
const key = 'node-test'
|
||||
const options = {lookupOnly: true}
|
||||
|
||||
const cacheEntry: ArtifactCacheEntry = {
|
||||
cacheKey: key,
|
||||
scope: 'refs/heads/main',
|
||||
archiveLocation: 'www.actionscache.test/download'
|
||||
}
|
||||
const getCacheMock = jest.spyOn(cacheHttpClient, 'getCacheEntry')
|
||||
getCacheMock.mockImplementation(async () => {
|
||||
return Promise.resolve(cacheEntry)
|
||||
})
|
||||
|
||||
const createTempDirectoryMock = jest.spyOn(cacheUtils, 'createTempDirectory')
|
||||
const downloadCacheMock = jest.spyOn(cacheHttpClient, 'downloadCache')
|
||||
|
||||
const compression = CompressionMethod.Gzip
|
||||
const getCompressionMock = jest
|
||||
.spyOn(cacheUtils, 'getCompressionMethod')
|
||||
.mockReturnValue(Promise.resolve(compression))
|
||||
|
||||
const cacheKey = await restoreCache(paths, key, undefined, options)
|
||||
|
||||
expect(cacheKey).toBe(key)
|
||||
expect(getCompressionMock).toHaveBeenCalledTimes(1)
|
||||
expect(getCacheMock).toHaveBeenCalledWith([key], paths, {
|
||||
compressionMethod: compression,
|
||||
enableCrossOsArchive: false
|
||||
})
|
||||
// creating a tempDir and downloading the cache are skipped
|
||||
expect(createTempDirectoryMock).toHaveBeenCalledTimes(0)
|
||||
expect(downloadCacheMock).toHaveBeenCalledTimes(0)
|
||||
})
|
||||
-329
@@ -1,329 +0,0 @@
|
||||
import * as core from '@actions/core'
|
||||
import * as path from 'path'
|
||||
import {saveCache} from '../src/cache'
|
||||
import * as cacheHttpClient from '../src/internal/cacheHttpClient'
|
||||
import * as cacheUtils from '../src/internal/cacheUtils'
|
||||
import {CacheFilename, CompressionMethod} from '../src/internal/constants'
|
||||
import * as tar from '../src/internal/tar'
|
||||
import {TypedResponse} from '@actions/http-client/lib/interfaces'
|
||||
import {
|
||||
ReserveCacheResponse,
|
||||
ITypedResponseWithError
|
||||
} from '../src/internal/contracts'
|
||||
import {HttpClientError} from '@actions/http-client'
|
||||
|
||||
jest.mock('../src/internal/cacheHttpClient')
|
||||
jest.mock('../src/internal/cacheUtils')
|
||||
jest.mock('../src/internal/tar')
|
||||
|
||||
beforeAll(() => {
|
||||
jest.spyOn(console, 'log').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'debug').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'info').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'warning').mockImplementation(() => {})
|
||||
jest.spyOn(core, 'error').mockImplementation(() => {})
|
||||
jest.spyOn(cacheUtils, 'getCacheFileName').mockImplementation(cm => {
|
||||
const actualUtils = jest.requireActual('../src/internal/cacheUtils')
|
||||
return actualUtils.getCacheFileName(cm)
|
||||
})
|
||||
jest.spyOn(cacheUtils, 'resolvePaths').mockImplementation(async filePaths => {
|
||||
return filePaths.map(x => path.resolve(x))
|
||||
})
|
||||
jest.spyOn(cacheUtils, 'createTempDirectory').mockImplementation(async () => {
|
||||
return Promise.resolve('/foo/bar')
|
||||
})
|
||||
})
|
||||
|
||||
test('save with missing input should fail', async () => {
|
||||
const paths: string[] = []
|
||||
const primaryKey = 'Linux-node-bb828da54c148048dd17899ba9fda624811cfb43'
|
||||
await expect(saveCache(paths, primaryKey)).rejects.toThrowError(
|
||||
`Path Validation Error: At least one directory or file path is required`
|
||||
)
|
||||
})
|
||||
|
||||
test('save with large cache outputs should fail', async () => {
|
||||
const filePath = 'node_modules'
|
||||
const primaryKey = 'Linux-node-bb828da54c148048dd17899ba9fda624811cfb43'
|
||||
const cachePaths = [path.resolve(filePath)]
|
||||
|
||||
const createTarMock = jest.spyOn(tar, 'createTar')
|
||||
const logWarningMock = jest.spyOn(core, 'warning')
|
||||
|
||||
const cacheSize = 11 * 1024 * 1024 * 1024 //~11GB, over the 10GB limit
|
||||
jest
|
||||
.spyOn(cacheUtils, 'getArchiveFileSizeInBytes')
|
||||
.mockReturnValueOnce(cacheSize)
|
||||
const compression = CompressionMethod.Gzip
|
||||
const getCompressionMock = jest
|
||||
.spyOn(cacheUtils, 'getCompressionMethod')
|
||||
.mockReturnValueOnce(Promise.resolve(compression))
|
||||
|
||||
const cacheId = await saveCache([filePath], primaryKey)
|
||||
expect(cacheId).toBe(-1)
|
||||
expect(logWarningMock).toHaveBeenCalledTimes(1)
|
||||
expect(logWarningMock).toHaveBeenCalledWith(
|
||||
'Failed to save: Cache size of ~11264 MB (11811160064 B) is over the 10GB limit, not saving cache.'
|
||||
)
|
||||
|
||||
const archiveFolder = '/foo/bar'
|
||||
|
||||
expect(createTarMock).toHaveBeenCalledTimes(1)
|
||||
expect(createTarMock).toHaveBeenCalledWith(
|
||||
archiveFolder,
|
||||
cachePaths,
|
||||
compression
|
||||
)
|
||||
expect(getCompressionMock).toHaveBeenCalledTimes(1)
|
||||
})
|
||||
|
||||
test('save with large cache outputs should fail in GHES with error message', async () => {
|
||||
const filePath = 'node_modules'
|
||||
const primaryKey = 'Linux-node-bb828da54c148048dd17899ba9fda624811cfb43'
|
||||
const cachePaths = [path.resolve(filePath)]
|
||||
|
||||
const createTarMock = jest.spyOn(tar, 'createTar')
|
||||
const logWarningMock = jest.spyOn(core, 'warning')
|
||||
|
||||
const cacheSize = 11 * 1024 * 1024 * 1024 //~11GB, over the 10GB limit
|
||||
jest
|
||||
.spyOn(cacheUtils, 'getArchiveFileSizeInBytes')
|
||||
.mockReturnValueOnce(cacheSize)
|
||||
const compression = CompressionMethod.Gzip
|
||||
const getCompressionMock = jest
|
||||
.spyOn(cacheUtils, 'getCompressionMethod')
|
||||
.mockReturnValueOnce(Promise.resolve(compression))
|
||||
|
||||
jest.spyOn(cacheUtils, 'isGhes').mockReturnValueOnce(true)
|
||||
|
||||
const reserveCacheMock = jest
|
||||
.spyOn(cacheHttpClient, 'reserveCache')
|
||||
.mockImplementation(async () => {
|
||||
const response: ITypedResponseWithError<ReserveCacheResponse> = {
|
||||
statusCode: 400,
|
||||
result: null,
|
||||
headers: {},
|
||||
error: new HttpClientError(
|
||||
'The cache filesize must be between 0 and 1073741824 bytes',
|
||||
400
|
||||
)
|
||||
}
|
||||
return response
|
||||
})
|
||||
|
||||
const cacheId = await saveCache([filePath], primaryKey)
|
||||
expect(cacheId).toBe(-1)
|
||||
expect(logWarningMock).toHaveBeenCalledTimes(1)
|
||||
expect(logWarningMock).toHaveBeenCalledWith(
|
||||
'Failed to save: The cache filesize must be between 0 and 1073741824 bytes'
|
||||
)
|
||||
|
||||
const archiveFolder = '/foo/bar'
|
||||
expect(reserveCacheMock).toHaveBeenCalledTimes(1)
|
||||
expect(createTarMock).toHaveBeenCalledTimes(1)
|
||||
expect(createTarMock).toHaveBeenCalledWith(
|
||||
archiveFolder,
|
||||
cachePaths,
|
||||
compression
|
||||
)
|
||||
expect(getCompressionMock).toHaveBeenCalledTimes(1)
|
||||
})
|
||||
|
||||
test('save with large cache outputs should fail in GHES without error message', async () => {
|
||||
const filePath = 'node_modules'
|
||||
const primaryKey = 'Linux-node-bb828da54c148048dd17899ba9fda624811cfb43'
|
||||
const cachePaths = [path.resolve(filePath)]
|
||||
|
||||
const createTarMock = jest.spyOn(tar, 'createTar')
|
||||
const logWarningMock = jest.spyOn(core, 'warning')
|
||||
|
||||
const cacheSize = 11 * 1024 * 1024 * 1024 //~11GB, over the 10GB limit
|
||||
jest
|
||||
.spyOn(cacheUtils, 'getArchiveFileSizeInBytes')
|
||||
.mockReturnValueOnce(cacheSize)
|
||||
const compression = CompressionMethod.Gzip
|
||||
const getCompressionMock = jest
|
||||
.spyOn(cacheUtils, 'getCompressionMethod')
|
||||
.mockReturnValueOnce(Promise.resolve(compression))
|
||||
|
||||
jest.spyOn(cacheUtils, 'isGhes').mockReturnValueOnce(true)
|
||||
|
||||
const reserveCacheMock = jest
|
||||
.spyOn(cacheHttpClient, 'reserveCache')
|
||||
.mockImplementation(async () => {
|
||||
const response: ITypedResponseWithError<ReserveCacheResponse> = {
|
||||
statusCode: 400,
|
||||
result: null,
|
||||
headers: {}
|
||||
}
|
||||
return response
|
||||
})
|
||||
|
||||
const cacheId = await saveCache([filePath], primaryKey)
|
||||
expect(cacheId).toBe(-1)
|
||||
expect(logWarningMock).toHaveBeenCalledTimes(1)
|
||||
expect(logWarningMock).toHaveBeenCalledWith(
|
||||
'Failed to save: Cache size of ~11264 MB (11811160064 B) is over the data cap limit, not saving cache.'
|
||||
)
|
||||
|
||||
const archiveFolder = '/foo/bar'
|
||||
expect(reserveCacheMock).toHaveBeenCalledTimes(1)
|
||||
expect(createTarMock).toHaveBeenCalledTimes(1)
|
||||
expect(createTarMock).toHaveBeenCalledWith(
|
||||
archiveFolder,
|
||||
cachePaths,
|
||||
compression
|
||||
)
|
||||
expect(getCompressionMock).toHaveBeenCalledTimes(1)
|
||||
})
|
||||
|
||||
test('save with reserve cache failure should fail', async () => {
|
||||
const paths = ['node_modules']
|
||||
const primaryKey = 'Linux-node-bb828da54c148048dd17899ba9fda624811cfb43'
|
||||
const logInfoMock = jest.spyOn(core, 'info')
|
||||
|
||||
const reserveCacheMock = jest
|
||||
.spyOn(cacheHttpClient, 'reserveCache')
|
||||
.mockImplementation(async () => {
|
||||
const response: TypedResponse<ReserveCacheResponse> = {
|
||||
statusCode: 500,
|
||||
result: null,
|
||||
headers: {}
|
||||
}
|
||||
return response
|
||||
})
|
||||
|
||||
const createTarMock = jest.spyOn(tar, 'createTar')
|
||||
const saveCacheMock = jest.spyOn(cacheHttpClient, 'saveCache')
|
||||
const compression = CompressionMethod.Zstd
|
||||
const getCompressionMock = jest
|
||||
.spyOn(cacheUtils, 'getCompressionMethod')
|
||||
.mockReturnValueOnce(Promise.resolve(compression))
|
||||
|
||||
const cacheId = await saveCache(paths, primaryKey)
|
||||
expect(cacheId).toBe(-1)
|
||||
expect(logInfoMock).toHaveBeenCalledTimes(1)
|
||||
expect(logInfoMock).toHaveBeenCalledWith(
|
||||
`Failed to save: Unable to reserve cache with key ${primaryKey}, another job may be creating this cache. More details: undefined`
|
||||
)
|
||||
|
||||
expect(reserveCacheMock).toHaveBeenCalledTimes(1)
|
||||
expect(reserveCacheMock).toHaveBeenCalledWith(primaryKey, paths, {
|
||||
cacheSize: undefined,
|
||||
compressionMethod: compression,
|
||||
enableCrossOsArchive: false
|
||||
})
|
||||
expect(createTarMock).toHaveBeenCalledTimes(1)
|
||||
expect(saveCacheMock).toHaveBeenCalledTimes(0)
|
||||
expect(getCompressionMock).toHaveBeenCalledTimes(1)
|
||||
})
|
||||
|
||||
test('save with server error should fail', async () => {
|
||||
const filePath = 'node_modules'
|
||||
const primaryKey = 'Linux-node-bb828da54c148048dd17899ba9fda624811cfb43'
|
||||
const cachePaths = [path.resolve(filePath)]
|
||||
const logWarningMock = jest.spyOn(core, 'warning')
|
||||
const cacheId = 4
|
||||
const reserveCacheMock = jest
|
||||
.spyOn(cacheHttpClient, 'reserveCache')
|
||||
.mockImplementation(async () => {
|
||||
const response: TypedResponse<ReserveCacheResponse> = {
|
||||
statusCode: 500,
|
||||
result: {cacheId},
|
||||
headers: {}
|
||||
}
|
||||
return response
|
||||
})
|
||||
|
||||
const createTarMock = jest.spyOn(tar, 'createTar')
|
||||
|
||||
const saveCacheMock = jest
|
||||
.spyOn(cacheHttpClient, 'saveCache')
|
||||
.mockImplementationOnce(() => {
|
||||
throw new Error('HTTP Error Occurred')
|
||||
})
|
||||
const compression = CompressionMethod.Zstd
|
||||
const getCompressionMock = jest
|
||||
.spyOn(cacheUtils, 'getCompressionMethod')
|
||||
.mockReturnValueOnce(Promise.resolve(compression))
|
||||
|
||||
await saveCache([filePath], primaryKey)
|
||||
expect(logWarningMock).toHaveBeenCalledTimes(1)
|
||||
expect(logWarningMock).toHaveBeenCalledWith(
|
||||
'Failed to save: HTTP Error Occurred'
|
||||
)
|
||||
|
||||
expect(reserveCacheMock).toHaveBeenCalledTimes(1)
|
||||
expect(reserveCacheMock).toHaveBeenCalledWith(primaryKey, [filePath], {
|
||||
cacheSize: undefined,
|
||||
compressionMethod: compression,
|
||||
enableCrossOsArchive: false
|
||||
})
|
||||
const archiveFolder = '/foo/bar'
|
||||
const archiveFile = path.join(archiveFolder, CacheFilename.Zstd)
|
||||
expect(createTarMock).toHaveBeenCalledTimes(1)
|
||||
expect(createTarMock).toHaveBeenCalledWith(
|
||||
archiveFolder,
|
||||
cachePaths,
|
||||
compression
|
||||
)
|
||||
expect(saveCacheMock).toHaveBeenCalledTimes(1)
|
||||
expect(saveCacheMock).toHaveBeenCalledWith(cacheId, archiveFile, undefined)
|
||||
expect(getCompressionMock).toHaveBeenCalledTimes(1)
|
||||
})
|
||||
|
||||
test('save with valid inputs uploads a cache', async () => {
|
||||
const filePath = 'node_modules'
|
||||
const primaryKey = 'Linux-node-bb828da54c148048dd17899ba9fda624811cfb43'
|
||||
const cachePaths = [path.resolve(filePath)]
|
||||
|
||||
const cacheId = 4
|
||||
const reserveCacheMock = jest
|
||||
.spyOn(cacheHttpClient, 'reserveCache')
|
||||
.mockImplementation(async () => {
|
||||
const response: TypedResponse<ReserveCacheResponse> = {
|
||||
statusCode: 500,
|
||||
result: {cacheId},
|
||||
headers: {}
|
||||
}
|
||||
return response
|
||||
})
|
||||
const createTarMock = jest.spyOn(tar, 'createTar')
|
||||
|
||||
const saveCacheMock = jest.spyOn(cacheHttpClient, 'saveCache')
|
||||
const compression = CompressionMethod.Zstd
|
||||
const getCompressionMock = jest
|
||||
.spyOn(cacheUtils, 'getCompressionMethod')
|
||||
.mockReturnValue(Promise.resolve(compression))
|
||||
|
||||
await saveCache([filePath], primaryKey)
|
||||
|
||||
expect(reserveCacheMock).toHaveBeenCalledTimes(1)
|
||||
expect(reserveCacheMock).toHaveBeenCalledWith(primaryKey, [filePath], {
|
||||
cacheSize: undefined,
|
||||
compressionMethod: compression,
|
||||
enableCrossOsArchive: false
|
||||
})
|
||||
const archiveFolder = '/foo/bar'
|
||||
const archiveFile = path.join(archiveFolder, CacheFilename.Zstd)
|
||||
expect(createTarMock).toHaveBeenCalledTimes(1)
|
||||
expect(createTarMock).toHaveBeenCalledWith(
|
||||
archiveFolder,
|
||||
cachePaths,
|
||||
compression
|
||||
)
|
||||
expect(saveCacheMock).toHaveBeenCalledTimes(1)
|
||||
expect(saveCacheMock).toHaveBeenCalledWith(cacheId, archiveFile, undefined)
|
||||
expect(getCompressionMock).toHaveBeenCalledTimes(1)
|
||||
})
|
||||
|
||||
test('save with non existing path should not save cache', async () => {
|
||||
const path = 'node_modules'
|
||||
const primaryKey = 'Linux-node-bb828da54c148048dd17899ba9fda624811cfb43'
|
||||
jest.spyOn(cacheUtils, 'resolvePaths').mockImplementation(async () => {
|
||||
return []
|
||||
})
|
||||
await expect(saveCache([path], primaryKey)).rejects.toThrowError(
|
||||
`Path Validation Error: Path(s) specified in the action for caching do(es) not exist, hence no cache is being saved.`
|
||||
)
|
||||
})
|
||||
Vendored
-482
@@ -1,482 +0,0 @@
|
||||
import * as exec from '@actions/exec'
|
||||
import * as io from '@actions/io'
|
||||
import * as path from 'path'
|
||||
import {
|
||||
CacheFilename,
|
||||
CompressionMethod,
|
||||
GnuTarPathOnWindows,
|
||||
ManifestFilename,
|
||||
SystemTarPathOnWindows,
|
||||
TarFilename
|
||||
} from '../src/internal/constants'
|
||||
import * as tar from '../src/internal/tar'
|
||||
import * as utils from '../src/internal/cacheUtils'
|
||||
// eslint-disable-next-line @typescript-eslint/no-require-imports
|
||||
import fs = require('fs')
|
||||
|
||||
jest.mock('@actions/exec')
|
||||
jest.mock('@actions/io')
|
||||
|
||||
const IS_WINDOWS = process.platform === 'win32'
|
||||
const IS_MAC = process.platform === 'darwin'
|
||||
|
||||
const defaultTarPath = IS_MAC ? 'gtar' : 'tar'
|
||||
|
||||
const defaultEnv = {MSYS: 'winsymlinks:nativestrict'}
|
||||
|
||||
function getTempDir(): string {
|
||||
return path.join(__dirname, '_temp', 'tar')
|
||||
}
|
||||
|
||||
beforeAll(async () => {
|
||||
jest.spyOn(io, 'which').mockImplementation(async tool => {
|
||||
return tool
|
||||
})
|
||||
|
||||
process.env['GITHUB_WORKSPACE'] = process.cwd()
|
||||
await jest.requireActual('@actions/io').rmRF(getTempDir())
|
||||
})
|
||||
|
||||
beforeEach(async () => {
|
||||
jest.restoreAllMocks()
|
||||
})
|
||||
|
||||
afterAll(async () => {
|
||||
delete process.env['GITHUB_WORKSPACE']
|
||||
await jest.requireActual('@actions/io').rmRF(getTempDir())
|
||||
})
|
||||
|
||||
test('zstd extract tar', async () => {
|
||||
const mkdirMock = jest.spyOn(io, 'mkdirP')
|
||||
const execMock = jest.spyOn(exec, 'exec')
|
||||
|
||||
const archivePath = IS_WINDOWS
|
||||
? `${process.env['windir']}\\fakepath\\cache.tar`
|
||||
: 'cache.tar'
|
||||
const workspace = process.env['GITHUB_WORKSPACE']
|
||||
const tarPath = IS_WINDOWS ? GnuTarPathOnWindows : defaultTarPath
|
||||
|
||||
await tar.extractTar(archivePath, CompressionMethod.Zstd)
|
||||
|
||||
expect(mkdirMock).toHaveBeenCalledWith(workspace)
|
||||
expect(execMock).toHaveBeenCalledTimes(1)
|
||||
expect(execMock).toHaveBeenCalledWith(
|
||||
[
|
||||
`"${tarPath}"`,
|
||||
'-xf',
|
||||
IS_WINDOWS ? archivePath.replace(/\\/g, '/') : archivePath,
|
||||
'-P',
|
||||
'-C',
|
||||
IS_WINDOWS ? workspace?.replace(/\\/g, '/') : workspace
|
||||
]
|
||||
.concat(IS_WINDOWS ? ['--force-local'] : [])
|
||||
.concat(IS_MAC ? ['--delay-directory-restore'] : [])
|
||||
.concat([
|
||||
'--use-compress-program',
|
||||
IS_WINDOWS ? '"zstd -d --long=30"' : 'unzstd --long=30'
|
||||
])
|
||||
.join(' '),
|
||||
undefined,
|
||||
{
|
||||
cwd: undefined,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
})
|
||||
|
||||
test('zstd extract tar with windows BSDtar', async () => {
|
||||
if (IS_WINDOWS) {
|
||||
const mkdirMock = jest.spyOn(io, 'mkdirP')
|
||||
const execMock = jest.spyOn(exec, 'exec')
|
||||
jest
|
||||
.spyOn(utils, 'getGnuTarPathOnWindows')
|
||||
.mockReturnValue(Promise.resolve(''))
|
||||
|
||||
const archivePath = `${process.env['windir']}\\fakepath\\cache.tar`
|
||||
const workspace = process.env['GITHUB_WORKSPACE']
|
||||
const tarPath = SystemTarPathOnWindows
|
||||
|
||||
await tar.extractTar(archivePath, CompressionMethod.Zstd)
|
||||
|
||||
expect(mkdirMock).toHaveBeenCalledWith(workspace)
|
||||
expect(execMock).toHaveBeenCalledTimes(2)
|
||||
|
||||
expect(execMock).toHaveBeenNthCalledWith(
|
||||
1,
|
||||
[
|
||||
'zstd -d --long=30 --force -o',
|
||||
TarFilename.replace(new RegExp(`\\${path.sep}`, 'g'), '/'),
|
||||
archivePath.replace(new RegExp(`\\${path.sep}`, 'g'), '/')
|
||||
].join(' '),
|
||||
undefined,
|
||||
{
|
||||
cwd: undefined,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
|
||||
expect(execMock).toHaveBeenNthCalledWith(
|
||||
2,
|
||||
[
|
||||
`"${tarPath}"`,
|
||||
'-xf',
|
||||
TarFilename.replace(new RegExp(`\\${path.sep}`, 'g'), '/'),
|
||||
'-P',
|
||||
'-C',
|
||||
workspace?.replace(/\\/g, '/')
|
||||
].join(' '),
|
||||
undefined,
|
||||
{
|
||||
cwd: undefined,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
}
|
||||
})
|
||||
|
||||
test('gzip extract tar', async () => {
|
||||
const mkdirMock = jest.spyOn(io, 'mkdirP')
|
||||
const execMock = jest.spyOn(exec, 'exec')
|
||||
const archivePath = IS_WINDOWS
|
||||
? `${process.env['windir']}\\fakepath\\cache.tar`
|
||||
: 'cache.tar'
|
||||
const workspace = process.env['GITHUB_WORKSPACE']
|
||||
|
||||
await tar.extractTar(archivePath, CompressionMethod.Gzip)
|
||||
|
||||
expect(mkdirMock).toHaveBeenCalledWith(workspace)
|
||||
const tarPath = IS_WINDOWS ? GnuTarPathOnWindows : defaultTarPath
|
||||
expect(execMock).toHaveBeenCalledTimes(1)
|
||||
expect(execMock).toHaveBeenCalledWith(
|
||||
[
|
||||
`"${tarPath}"`,
|
||||
'-xf',
|
||||
IS_WINDOWS ? archivePath.replace(/\\/g, '/') : archivePath,
|
||||
'-P',
|
||||
'-C',
|
||||
IS_WINDOWS ? workspace?.replace(/\\/g, '/') : workspace
|
||||
]
|
||||
.concat(IS_WINDOWS ? ['--force-local'] : [])
|
||||
.concat(IS_MAC ? ['--delay-directory-restore'] : [])
|
||||
.concat(['-z'])
|
||||
.join(' '),
|
||||
undefined,
|
||||
{
|
||||
cwd: undefined,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
})
|
||||
|
||||
test('gzip extract GNU tar on windows with GNUtar in path', async () => {
|
||||
if (IS_WINDOWS) {
|
||||
// GNU tar present in path but not at default location
|
||||
jest
|
||||
.spyOn(utils, 'getGnuTarPathOnWindows')
|
||||
.mockReturnValue(Promise.resolve('tar'))
|
||||
const execMock = jest.spyOn(exec, 'exec')
|
||||
const archivePath = `${process.env['windir']}\\fakepath\\cache.tar`
|
||||
const workspace = process.env['GITHUB_WORKSPACE']
|
||||
|
||||
await tar.extractTar(archivePath, CompressionMethod.Gzip)
|
||||
|
||||
expect(execMock).toHaveBeenCalledTimes(1)
|
||||
expect(execMock).toHaveBeenCalledWith(
|
||||
[
|
||||
`"tar"`,
|
||||
'-xf',
|
||||
archivePath.replace(/\\/g, '/'),
|
||||
'-P',
|
||||
'-C',
|
||||
workspace?.replace(/\\/g, '/'),
|
||||
'--force-local',
|
||||
'-z'
|
||||
].join(' '),
|
||||
undefined,
|
||||
{
|
||||
cwd: undefined,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
}
|
||||
})
|
||||
|
||||
test('zstd create tar', async () => {
|
||||
const execMock = jest.spyOn(exec, 'exec')
|
||||
|
||||
const archiveFolder = getTempDir()
|
||||
const workspace = process.env['GITHUB_WORKSPACE']
|
||||
const sourceDirectories = ['~/.npm/cache', `${workspace}/dist`]
|
||||
|
||||
await fs.promises.mkdir(archiveFolder, {recursive: true})
|
||||
|
||||
await tar.createTar(archiveFolder, sourceDirectories, CompressionMethod.Zstd)
|
||||
|
||||
const tarPath = IS_WINDOWS ? GnuTarPathOnWindows : defaultTarPath
|
||||
|
||||
expect(execMock).toHaveBeenCalledTimes(1)
|
||||
expect(execMock).toHaveBeenCalledWith(
|
||||
[
|
||||
`"${tarPath}"`,
|
||||
'--posix',
|
||||
'-cf',
|
||||
IS_WINDOWS ? CacheFilename.Zstd.replace(/\\/g, '/') : CacheFilename.Zstd,
|
||||
'--exclude',
|
||||
IS_WINDOWS ? CacheFilename.Zstd.replace(/\\/g, '/') : CacheFilename.Zstd,
|
||||
'-P',
|
||||
'-C',
|
||||
IS_WINDOWS ? workspace?.replace(/\\/g, '/') : workspace,
|
||||
'--files-from',
|
||||
ManifestFilename
|
||||
]
|
||||
.concat(IS_WINDOWS ? ['--force-local'] : [])
|
||||
.concat(IS_MAC ? ['--delay-directory-restore'] : [])
|
||||
.concat([
|
||||
'--use-compress-program',
|
||||
IS_WINDOWS ? '"zstd -T0 --long=30"' : 'zstdmt --long=30'
|
||||
])
|
||||
.join(' '),
|
||||
undefined, // args
|
||||
{
|
||||
cwd: archiveFolder,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
})
|
||||
|
||||
test('zstd create tar with windows BSDtar', async () => {
|
||||
if (IS_WINDOWS) {
|
||||
const execMock = jest.spyOn(exec, 'exec')
|
||||
jest
|
||||
.spyOn(utils, 'getGnuTarPathOnWindows')
|
||||
.mockReturnValue(Promise.resolve(''))
|
||||
|
||||
const archiveFolder = getTempDir()
|
||||
const workspace = process.env['GITHUB_WORKSPACE']
|
||||
const sourceDirectories = ['~/.npm/cache', `${workspace}/dist`]
|
||||
|
||||
await fs.promises.mkdir(archiveFolder, {recursive: true})
|
||||
|
||||
await tar.createTar(
|
||||
archiveFolder,
|
||||
sourceDirectories,
|
||||
CompressionMethod.Zstd
|
||||
)
|
||||
|
||||
const tarPath = SystemTarPathOnWindows
|
||||
|
||||
expect(execMock).toHaveBeenCalledTimes(2)
|
||||
|
||||
expect(execMock).toHaveBeenNthCalledWith(
|
||||
1,
|
||||
[
|
||||
`"${tarPath}"`,
|
||||
'--posix',
|
||||
'-cf',
|
||||
TarFilename.replace(/\\/g, '/'),
|
||||
'--exclude',
|
||||
TarFilename.replace(/\\/g, '/'),
|
||||
'-P',
|
||||
'-C',
|
||||
workspace?.replace(/\\/g, '/'),
|
||||
'--files-from',
|
||||
ManifestFilename
|
||||
].join(' '),
|
||||
undefined, // args
|
||||
{
|
||||
cwd: archiveFolder,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
|
||||
expect(execMock).toHaveBeenNthCalledWith(
|
||||
2,
|
||||
[
|
||||
'zstd -T0 --long=30 --force -o',
|
||||
CacheFilename.Zstd.replace(/\\/g, '/'),
|
||||
TarFilename.replace(/\\/g, '/')
|
||||
].join(' '),
|
||||
undefined, // args
|
||||
{
|
||||
cwd: archiveFolder,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
}
|
||||
})
|
||||
|
||||
test('gzip create tar', async () => {
|
||||
const execMock = jest.spyOn(exec, 'exec')
|
||||
|
||||
const archiveFolder = getTempDir()
|
||||
const workspace = process.env['GITHUB_WORKSPACE']
|
||||
const sourceDirectories = ['~/.npm/cache', `${workspace}/dist`]
|
||||
|
||||
await fs.promises.mkdir(archiveFolder, {recursive: true})
|
||||
|
||||
await tar.createTar(archiveFolder, sourceDirectories, CompressionMethod.Gzip)
|
||||
|
||||
const tarPath = IS_WINDOWS ? GnuTarPathOnWindows : defaultTarPath
|
||||
|
||||
expect(execMock).toHaveBeenCalledTimes(1)
|
||||
expect(execMock).toHaveBeenCalledWith(
|
||||
[
|
||||
`"${tarPath}"`,
|
||||
'--posix',
|
||||
'-cf',
|
||||
IS_WINDOWS ? CacheFilename.Gzip.replace(/\\/g, '/') : CacheFilename.Gzip,
|
||||
'--exclude',
|
||||
IS_WINDOWS ? CacheFilename.Gzip.replace(/\\/g, '/') : CacheFilename.Gzip,
|
||||
'-P',
|
||||
'-C',
|
||||
IS_WINDOWS ? workspace?.replace(/\\/g, '/') : workspace,
|
||||
'--files-from',
|
||||
ManifestFilename
|
||||
]
|
||||
.concat(IS_WINDOWS ? ['--force-local'] : [])
|
||||
.concat(IS_MAC ? ['--delay-directory-restore'] : [])
|
||||
.concat(['-z'])
|
||||
.join(' '),
|
||||
undefined, // args
|
||||
{
|
||||
cwd: archiveFolder,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
})
|
||||
|
||||
test('zstd list tar', async () => {
|
||||
const execMock = jest.spyOn(exec, 'exec')
|
||||
|
||||
const archivePath = IS_WINDOWS
|
||||
? `${process.env['windir']}\\fakepath\\cache.tar`
|
||||
: 'cache.tar'
|
||||
|
||||
await tar.listTar(archivePath, CompressionMethod.Zstd)
|
||||
|
||||
const tarPath = IS_WINDOWS ? GnuTarPathOnWindows : defaultTarPath
|
||||
expect(execMock).toHaveBeenCalledTimes(1)
|
||||
expect(execMock).toHaveBeenCalledWith(
|
||||
[
|
||||
`"${tarPath}"`,
|
||||
'-tf',
|
||||
IS_WINDOWS ? archivePath.replace(/\\/g, '/') : archivePath,
|
||||
'-P'
|
||||
]
|
||||
.concat(IS_WINDOWS ? ['--force-local'] : [])
|
||||
.concat(IS_MAC ? ['--delay-directory-restore'] : [])
|
||||
.concat([
|
||||
'--use-compress-program',
|
||||
IS_WINDOWS ? '"zstd -d --long=30"' : 'unzstd --long=30'
|
||||
])
|
||||
.join(' '),
|
||||
undefined,
|
||||
{
|
||||
cwd: undefined,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
})
|
||||
|
||||
test('zstd list tar with windows BSDtar', async () => {
|
||||
if (IS_WINDOWS) {
|
||||
const execMock = jest.spyOn(exec, 'exec')
|
||||
jest
|
||||
.spyOn(utils, 'getGnuTarPathOnWindows')
|
||||
.mockReturnValue(Promise.resolve(''))
|
||||
const archivePath = `${process.env['windir']}\\fakepath\\cache.tar`
|
||||
|
||||
await tar.listTar(archivePath, CompressionMethod.Zstd)
|
||||
|
||||
const tarPath = SystemTarPathOnWindows
|
||||
expect(execMock).toHaveBeenCalledTimes(2)
|
||||
|
||||
expect(execMock).toHaveBeenNthCalledWith(
|
||||
1,
|
||||
[
|
||||
'zstd -d --long=30 --force -o',
|
||||
TarFilename.replace(new RegExp(`\\${path.sep}`, 'g'), '/'),
|
||||
archivePath.replace(new RegExp(`\\${path.sep}`, 'g'), '/')
|
||||
].join(' '),
|
||||
undefined,
|
||||
{
|
||||
cwd: undefined,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
|
||||
expect(execMock).toHaveBeenNthCalledWith(
|
||||
2,
|
||||
[
|
||||
`"${tarPath}"`,
|
||||
'-tf',
|
||||
TarFilename.replace(new RegExp(`\\${path.sep}`, 'g'), '/'),
|
||||
'-P'
|
||||
].join(' '),
|
||||
undefined,
|
||||
{
|
||||
cwd: undefined,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
}
|
||||
})
|
||||
|
||||
test('zstdWithoutLong list tar', async () => {
|
||||
const execMock = jest.spyOn(exec, 'exec')
|
||||
|
||||
const archivePath = IS_WINDOWS
|
||||
? `${process.env['windir']}\\fakepath\\cache.tar`
|
||||
: 'cache.tar'
|
||||
|
||||
await tar.listTar(archivePath, CompressionMethod.ZstdWithoutLong)
|
||||
|
||||
const tarPath = IS_WINDOWS ? GnuTarPathOnWindows : defaultTarPath
|
||||
expect(execMock).toHaveBeenCalledTimes(1)
|
||||
expect(execMock).toHaveBeenCalledWith(
|
||||
[
|
||||
`"${tarPath}"`,
|
||||
'-tf',
|
||||
IS_WINDOWS ? archivePath.replace(/\\/g, '/') : archivePath,
|
||||
'-P'
|
||||
]
|
||||
.concat(IS_WINDOWS ? ['--force-local'] : [])
|
||||
.concat(IS_MAC ? ['--delay-directory-restore'] : [])
|
||||
.concat(['--use-compress-program', IS_WINDOWS ? '"zstd -d"' : 'unzstd'])
|
||||
.join(' '),
|
||||
undefined,
|
||||
{
|
||||
cwd: undefined,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
})
|
||||
|
||||
test('gzip list tar', async () => {
|
||||
const execMock = jest.spyOn(exec, 'exec')
|
||||
const archivePath = IS_WINDOWS
|
||||
? `${process.env['windir']}\\fakepath\\cache.tar`
|
||||
: 'cache.tar'
|
||||
|
||||
await tar.listTar(archivePath, CompressionMethod.Gzip)
|
||||
|
||||
const tarPath = IS_WINDOWS ? GnuTarPathOnWindows : defaultTarPath
|
||||
expect(execMock).toHaveBeenCalledTimes(1)
|
||||
expect(execMock).toHaveBeenCalledWith(
|
||||
[
|
||||
`"${tarPath}"`,
|
||||
'-tf',
|
||||
IS_WINDOWS ? archivePath.replace(/\\/g, '/') : archivePath,
|
||||
'-P'
|
||||
]
|
||||
.concat(IS_WINDOWS ? ['--force-local'] : [])
|
||||
.concat(IS_MAC ? ['--delay-directory-restore'] : [])
|
||||
.concat(['-z'])
|
||||
.join(' '),
|
||||
undefined,
|
||||
{
|
||||
cwd: undefined,
|
||||
env: expect.objectContaining(defaultEnv)
|
||||
}
|
||||
)
|
||||
})
|
||||
-36
@@ -1,36 +0,0 @@
|
||||
#!/bin/sh
|
||||
|
||||
# Validate args
|
||||
prefix="$1"
|
||||
if [ -z "$prefix" ]; then
|
||||
echo "Must supply prefix argument"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
path="$2"
|
||||
if [ -z "$path" ]; then
|
||||
echo "Must specify path argument"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# Sanity check GITHUB_RUN_ID defined
|
||||
if [ -z "$GITHUB_RUN_ID" ]; then
|
||||
echo "GITHUB_RUN_ID not defined"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# Verify file exists
|
||||
file="$path/test-file.txt"
|
||||
echo "Checking for $file"
|
||||
if [ ! -e $file ]; then
|
||||
echo "File does not exist"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# Verify file content
|
||||
content="$(cat $file)"
|
||||
echo "File content:\n$content"
|
||||
if [ -z "$(echo $content | grep --fixed-strings "$prefix $GITHUB_RUN_ID")" ]; then
|
||||
echo "Unexpected file content"
|
||||
exit 1
|
||||
fi
|
||||
-1106
File diff suppressed because it is too large
Load Diff
Vendored
-56
@@ -1,56 +0,0 @@
|
||||
{
|
||||
"name": "@actions/cache",
|
||||
"version": "3.2.1",
|
||||
"preview": true,
|
||||
"description": "Actions cache lib",
|
||||
"keywords": [
|
||||
"github",
|
||||
"actions",
|
||||
"cache"
|
||||
],
|
||||
"homepage": "https://github.com/actions/toolkit/tree/main/packages/cache",
|
||||
"license": "MIT",
|
||||
"main": "lib/cache.js",
|
||||
"types": "lib/cache.d.ts",
|
||||
"directories": {
|
||||
"lib": "lib",
|
||||
"test": "__tests__"
|
||||
},
|
||||
"files": [
|
||||
"lib",
|
||||
"!.DS_Store"
|
||||
],
|
||||
"publishConfig": {
|
||||
"access": "public"
|
||||
},
|
||||
"repository": {
|
||||
"type": "git",
|
||||
"url": "git+https://github.com/actions/toolkit.git",
|
||||
"directory": "packages/cache"
|
||||
},
|
||||
"scripts": {
|
||||
"audit-moderate": "npm install && npm audit --json --audit-level=moderate > audit.json",
|
||||
"test": "echo \"Error: run tests from root\" && exit 1",
|
||||
"tsc": "tsc"
|
||||
},
|
||||
"bugs": {
|
||||
"url": "https://github.com/actions/toolkit/issues"
|
||||
},
|
||||
"dependencies": {
|
||||
"@actions/core": "^1.10.0",
|
||||
"@actions/exec": "^1.0.1",
|
||||
"@actions/glob": "^0.1.0",
|
||||
"@actions/http-client": "^2.0.1",
|
||||
"@actions/io": "^1.0.1",
|
||||
"@azure/abort-controller": "^1.1.0",
|
||||
"@azure/ms-rest-js": "^2.6.0",
|
||||
"@azure/storage-blob": "^12.13.0",
|
||||
"semver": "^6.1.0",
|
||||
"uuid": "^3.3.3"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@types/semver": "^6.0.0",
|
||||
"@types/uuid": "^3.4.5",
|
||||
"typescript": "^4.8.0"
|
||||
}
|
||||
}
|
||||
Vendored
-260
@@ -1,260 +0,0 @@
|
||||
import * as core from '@actions/core'
|
||||
import * as path from 'path'
|
||||
import * as utils from './internal/cacheUtils'
|
||||
import * as cacheHttpClient from './internal/cacheHttpClient'
|
||||
import {createTar, extractTar, listTar} from './internal/tar'
|
||||
import {DownloadOptions, UploadOptions} from './options'
|
||||
|
||||
export class ValidationError extends Error {
|
||||
constructor(message: string) {
|
||||
super(message)
|
||||
this.name = 'ValidationError'
|
||||
Object.setPrototypeOf(this, ValidationError.prototype)
|
||||
}
|
||||
}
|
||||
|
||||
export class ReserveCacheError extends Error {
|
||||
constructor(message: string) {
|
||||
super(message)
|
||||
this.name = 'ReserveCacheError'
|
||||
Object.setPrototypeOf(this, ReserveCacheError.prototype)
|
||||
}
|
||||
}
|
||||
|
||||
function checkPaths(paths: string[]): void {
|
||||
if (!paths || paths.length === 0) {
|
||||
throw new ValidationError(
|
||||
`Path Validation Error: At least one directory or file path is required`
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
function checkKey(key: string): void {
|
||||
if (key.length > 512) {
|
||||
throw new ValidationError(
|
||||
`Key Validation Error: ${key} cannot be larger than 512 characters.`
|
||||
)
|
||||
}
|
||||
const regex = /^[^,]*$/
|
||||
if (!regex.test(key)) {
|
||||
throw new ValidationError(
|
||||
`Key Validation Error: ${key} cannot contain commas.`
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* isFeatureAvailable to check the presence of Actions cache service
|
||||
*
|
||||
* @returns boolean return true if Actions cache service feature is available, otherwise false
|
||||
*/
|
||||
|
||||
export function isFeatureAvailable(): boolean {
|
||||
return !!process.env['ACTIONS_CACHE_URL']
|
||||
}
|
||||
|
||||
/**
|
||||
* Restores cache from keys
|
||||
*
|
||||
* @param paths a list of file paths to restore from the cache
|
||||
* @param primaryKey an explicit key for restoring the cache
|
||||
* @param restoreKeys an optional ordered list of keys to use for restoring the cache if no cache hit occurred for key
|
||||
* @param downloadOptions cache download options
|
||||
* @param enableCrossOsArchive an optional boolean enabled to restore on windows any cache created on any platform
|
||||
* @returns string returns the key for the cache hit, otherwise returns undefined
|
||||
*/
|
||||
export async function restoreCache(
|
||||
paths: string[],
|
||||
primaryKey: string,
|
||||
restoreKeys?: string[],
|
||||
options?: DownloadOptions,
|
||||
enableCrossOsArchive = false
|
||||
): Promise<string | undefined> {
|
||||
checkPaths(paths)
|
||||
|
||||
restoreKeys = restoreKeys || []
|
||||
const keys = [primaryKey, ...restoreKeys]
|
||||
|
||||
core.debug('Resolved Keys:')
|
||||
core.debug(JSON.stringify(keys))
|
||||
|
||||
if (keys.length > 10) {
|
||||
throw new ValidationError(
|
||||
`Key Validation Error: Keys are limited to a maximum of 10.`
|
||||
)
|
||||
}
|
||||
for (const key of keys) {
|
||||
checkKey(key)
|
||||
}
|
||||
|
||||
const compressionMethod = await utils.getCompressionMethod()
|
||||
let archivePath = ''
|
||||
try {
|
||||
// path are needed to compute version
|
||||
const cacheEntry = await cacheHttpClient.getCacheEntry(keys, paths, {
|
||||
compressionMethod,
|
||||
enableCrossOsArchive
|
||||
})
|
||||
if (!cacheEntry?.archiveLocation) {
|
||||
// Cache not found
|
||||
return undefined
|
||||
}
|
||||
|
||||
if (options?.lookupOnly) {
|
||||
core.info('Lookup only - skipping download')
|
||||
return cacheEntry.cacheKey
|
||||
}
|
||||
|
||||
archivePath = path.join(
|
||||
await utils.createTempDirectory(),
|
||||
utils.getCacheFileName(compressionMethod)
|
||||
)
|
||||
core.debug(`Archive Path: ${archivePath}`)
|
||||
|
||||
// Download the cache from the cache entry
|
||||
await cacheHttpClient.downloadCache(
|
||||
cacheEntry.archiveLocation,
|
||||
archivePath,
|
||||
options
|
||||
)
|
||||
|
||||
if (core.isDebug()) {
|
||||
await listTar(archivePath, compressionMethod)
|
||||
}
|
||||
|
||||
const archiveFileSize = utils.getArchiveFileSizeInBytes(archivePath)
|
||||
core.info(
|
||||
`Cache Size: ~${Math.round(
|
||||
archiveFileSize / (1024 * 1024)
|
||||
)} MB (${archiveFileSize} B)`
|
||||
)
|
||||
|
||||
await extractTar(archivePath, compressionMethod)
|
||||
core.info('Cache restored successfully')
|
||||
|
||||
return cacheEntry.cacheKey
|
||||
} catch (error) {
|
||||
const typedError = error as Error
|
||||
if (typedError.name === ValidationError.name) {
|
||||
throw error
|
||||
} else {
|
||||
// Supress all non-validation cache related errors because caching should be optional
|
||||
core.warning(`Failed to restore: ${(error as Error).message}`)
|
||||
}
|
||||
} finally {
|
||||
// Try to delete the archive to save space
|
||||
try {
|
||||
await utils.unlinkFile(archivePath)
|
||||
} catch (error) {
|
||||
core.debug(`Failed to delete archive: ${error}`)
|
||||
}
|
||||
}
|
||||
|
||||
return undefined
|
||||
}
|
||||
|
||||
/**
|
||||
* Saves a list of files with the specified key
|
||||
*
|
||||
* @param paths a list of file paths to be cached
|
||||
* @param key an explicit key for restoring the cache
|
||||
* @param enableCrossOsArchive an optional boolean enabled to save cache on windows which could be restored on any platform
|
||||
* @param options cache upload options
|
||||
* @returns number returns cacheId if the cache was saved successfully and throws an error if save fails
|
||||
*/
|
||||
export async function saveCache(
|
||||
paths: string[],
|
||||
key: string,
|
||||
options?: UploadOptions,
|
||||
enableCrossOsArchive = false
|
||||
): Promise<number> {
|
||||
checkPaths(paths)
|
||||
checkKey(key)
|
||||
|
||||
const compressionMethod = await utils.getCompressionMethod()
|
||||
let cacheId = -1
|
||||
|
||||
const cachePaths = await utils.resolvePaths(paths)
|
||||
core.debug('Cache Paths:')
|
||||
core.debug(`${JSON.stringify(cachePaths)}`)
|
||||
|
||||
if (cachePaths.length === 0) {
|
||||
throw new Error(
|
||||
`Path Validation Error: Path(s) specified in the action for caching do(es) not exist, hence no cache is being saved.`
|
||||
)
|
||||
}
|
||||
|
||||
const archiveFolder = await utils.createTempDirectory()
|
||||
const archivePath = path.join(
|
||||
archiveFolder,
|
||||
utils.getCacheFileName(compressionMethod)
|
||||
)
|
||||
|
||||
core.debug(`Archive Path: ${archivePath}`)
|
||||
|
||||
try {
|
||||
await createTar(archiveFolder, cachePaths, compressionMethod)
|
||||
if (core.isDebug()) {
|
||||
await listTar(archivePath, compressionMethod)
|
||||
}
|
||||
const fileSizeLimit = 10 * 1024 * 1024 * 1024 // 10GB per repo limit
|
||||
const archiveFileSize = utils.getArchiveFileSizeInBytes(archivePath)
|
||||
core.debug(`File Size: ${archiveFileSize}`)
|
||||
|
||||
// For GHES, this check will take place in ReserveCache API with enterprise file size limit
|
||||
if (archiveFileSize > fileSizeLimit && !utils.isGhes()) {
|
||||
throw new Error(
|
||||
`Cache size of ~${Math.round(
|
||||
archiveFileSize / (1024 * 1024)
|
||||
)} MB (${archiveFileSize} B) is over the 10GB limit, not saving cache.`
|
||||
)
|
||||
}
|
||||
|
||||
core.debug('Reserving Cache')
|
||||
const reserveCacheResponse = await cacheHttpClient.reserveCache(
|
||||
key,
|
||||
paths,
|
||||
{
|
||||
compressionMethod,
|
||||
enableCrossOsArchive,
|
||||
cacheSize: archiveFileSize
|
||||
}
|
||||
)
|
||||
|
||||
if (reserveCacheResponse?.result?.cacheId) {
|
||||
cacheId = reserveCacheResponse?.result?.cacheId
|
||||
} else if (reserveCacheResponse?.statusCode === 400) {
|
||||
throw new Error(
|
||||
reserveCacheResponse?.error?.message ??
|
||||
`Cache size of ~${Math.round(
|
||||
archiveFileSize / (1024 * 1024)
|
||||
)} MB (${archiveFileSize} B) is over the data cap limit, not saving cache.`
|
||||
)
|
||||
} else {
|
||||
throw new ReserveCacheError(
|
||||
`Unable to reserve cache with key ${key}, another job may be creating this cache. More details: ${reserveCacheResponse?.error?.message}`
|
||||
)
|
||||
}
|
||||
|
||||
core.debug(`Saving Cache (ID: ${cacheId})`)
|
||||
await cacheHttpClient.saveCache(cacheId, archivePath, options)
|
||||
} catch (error) {
|
||||
const typedError = error as Error
|
||||
if (typedError.name === ValidationError.name) {
|
||||
throw error
|
||||
} else if (typedError.name === ReserveCacheError.name) {
|
||||
core.info(`Failed to save: ${typedError.message}`)
|
||||
} else {
|
||||
core.warning(`Failed to save: ${typedError.message}`)
|
||||
}
|
||||
} finally {
|
||||
// Try to delete the archive to save space
|
||||
try {
|
||||
await utils.unlinkFile(archivePath)
|
||||
} catch (error) {
|
||||
core.debug(`Failed to delete archive: ${error}`)
|
||||
}
|
||||
}
|
||||
|
||||
return cacheId
|
||||
}
|
||||
-364
@@ -1,364 +0,0 @@
|
||||
import * as core from '@actions/core'
|
||||
import {HttpClient} from '@actions/http-client'
|
||||
import {BearerCredentialHandler} from '@actions/http-client/lib/auth'
|
||||
import {
|
||||
RequestOptions,
|
||||
TypedResponse
|
||||
} from '@actions/http-client/lib/interfaces'
|
||||
import * as crypto from 'crypto'
|
||||
import * as fs from 'fs'
|
||||
import {URL} from 'url'
|
||||
|
||||
import * as utils from './cacheUtils'
|
||||
import {CompressionMethod} from './constants'
|
||||
import {
|
||||
ArtifactCacheEntry,
|
||||
InternalCacheOptions,
|
||||
CommitCacheRequest,
|
||||
ReserveCacheRequest,
|
||||
ReserveCacheResponse,
|
||||
ITypedResponseWithError,
|
||||
ArtifactCacheList
|
||||
} from './contracts'
|
||||
import {downloadCacheHttpClient, downloadCacheStorageSDK} from './downloadUtils'
|
||||
import {
|
||||
DownloadOptions,
|
||||
UploadOptions,
|
||||
getDownloadOptions,
|
||||
getUploadOptions
|
||||
} from '../options'
|
||||
import {
|
||||
isSuccessStatusCode,
|
||||
retryHttpClientResponse,
|
||||
retryTypedResponse
|
||||
} from './requestUtils'
|
||||
|
||||
const versionSalt = '1.0'
|
||||
|
||||
function getCacheApiUrl(resource: string): string {
|
||||
const baseUrl: string = process.env['ACTIONS_CACHE_URL'] || ''
|
||||
if (!baseUrl) {
|
||||
throw new Error('Cache Service Url not found, unable to restore cache.')
|
||||
}
|
||||
|
||||
const url = `${baseUrl}_apis/artifactcache/${resource}`
|
||||
core.debug(`Resource Url: ${url}`)
|
||||
return url
|
||||
}
|
||||
|
||||
function createAcceptHeader(type: string, apiVersion: string): string {
|
||||
return `${type};api-version=${apiVersion}`
|
||||
}
|
||||
|
||||
function getRequestOptions(): RequestOptions {
|
||||
const requestOptions: RequestOptions = {
|
||||
headers: {
|
||||
Accept: createAcceptHeader('application/json', '6.0-preview.1')
|
||||
}
|
||||
}
|
||||
|
||||
return requestOptions
|
||||
}
|
||||
|
||||
function createHttpClient(): HttpClient {
|
||||
const token = process.env['ACTIONS_RUNTIME_TOKEN'] || ''
|
||||
const bearerCredentialHandler = new BearerCredentialHandler(token)
|
||||
|
||||
return new HttpClient(
|
||||
'actions/cache',
|
||||
[bearerCredentialHandler],
|
||||
getRequestOptions()
|
||||
)
|
||||
}
|
||||
|
||||
export function getCacheVersion(
|
||||
paths: string[],
|
||||
compressionMethod?: CompressionMethod,
|
||||
enableCrossOsArchive = false
|
||||
): string {
|
||||
const components = paths
|
||||
|
||||
// Add compression method to cache version to restore
|
||||
// compressed cache as per compression method
|
||||
if (compressionMethod) {
|
||||
components.push(compressionMethod)
|
||||
}
|
||||
|
||||
// Only check for windows platforms if enableCrossOsArchive is false
|
||||
if (process.platform === 'win32' && !enableCrossOsArchive) {
|
||||
components.push('windows-only')
|
||||
}
|
||||
|
||||
// Add salt to cache version to support breaking changes in cache entry
|
||||
components.push(versionSalt)
|
||||
|
||||
return crypto
|
||||
.createHash('sha256')
|
||||
.update(components.join('|'))
|
||||
.digest('hex')
|
||||
}
|
||||
|
||||
export async function getCacheEntry(
|
||||
keys: string[],
|
||||
paths: string[],
|
||||
options?: InternalCacheOptions
|
||||
): Promise<ArtifactCacheEntry | null> {
|
||||
const httpClient = createHttpClient()
|
||||
const version = getCacheVersion(
|
||||
paths,
|
||||
options?.compressionMethod,
|
||||
options?.enableCrossOsArchive
|
||||
)
|
||||
const resource = `cache?keys=${encodeURIComponent(
|
||||
keys.join(',')
|
||||
)}&version=${version}`
|
||||
|
||||
const response = await retryTypedResponse('getCacheEntry', async () =>
|
||||
httpClient.getJson<ArtifactCacheEntry>(getCacheApiUrl(resource))
|
||||
)
|
||||
// Cache not found
|
||||
if (response.statusCode === 204) {
|
||||
// List cache for primary key only if cache miss occurs
|
||||
if (core.isDebug()) {
|
||||
await printCachesListForDiagnostics(keys[0], httpClient, version)
|
||||
}
|
||||
return null
|
||||
}
|
||||
if (!isSuccessStatusCode(response.statusCode)) {
|
||||
throw new Error(`Cache service responded with ${response.statusCode}`)
|
||||
}
|
||||
|
||||
const cacheResult = response.result
|
||||
const cacheDownloadUrl = cacheResult?.archiveLocation
|
||||
if (!cacheDownloadUrl) {
|
||||
// Cache achiveLocation not found. This should never happen, and hence bail out.
|
||||
throw new Error('Cache not found.')
|
||||
}
|
||||
core.setSecret(cacheDownloadUrl)
|
||||
core.debug(`Cache Result:`)
|
||||
core.debug(JSON.stringify(cacheResult))
|
||||
|
||||
return cacheResult
|
||||
}
|
||||
|
||||
async function printCachesListForDiagnostics(
|
||||
key: string,
|
||||
httpClient: HttpClient,
|
||||
version: string
|
||||
): Promise<void> {
|
||||
const resource = `caches?key=${encodeURIComponent(key)}`
|
||||
const response = await retryTypedResponse('listCache', async () =>
|
||||
httpClient.getJson<ArtifactCacheList>(getCacheApiUrl(resource))
|
||||
)
|
||||
if (response.statusCode === 200) {
|
||||
const cacheListResult = response.result
|
||||
const totalCount = cacheListResult?.totalCount
|
||||
if (totalCount && totalCount > 0) {
|
||||
core.debug(
|
||||
`No matching cache found for cache key '${key}', version '${version} and scope ${process.env['GITHUB_REF']}. There exist one or more cache(s) with similar key but they have different version or scope. See more info on cache matching here: https://docs.github.com/en/actions/using-workflows/caching-dependencies-to-speed-up-workflows#matching-a-cache-key \nOther caches with similar key:`
|
||||
)
|
||||
for (const cacheEntry of cacheListResult?.artifactCaches || []) {
|
||||
core.debug(
|
||||
`Cache Key: ${cacheEntry?.cacheKey}, Cache Version: ${cacheEntry?.cacheVersion}, Cache Scope: ${cacheEntry?.scope}, Cache Created: ${cacheEntry?.creationTime}`
|
||||
)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
export async function downloadCache(
|
||||
archiveLocation: string,
|
||||
archivePath: string,
|
||||
options?: DownloadOptions
|
||||
): Promise<void> {
|
||||
const archiveUrl = new URL(archiveLocation)
|
||||
const downloadOptions = getDownloadOptions(options)
|
||||
|
||||
if (
|
||||
downloadOptions.useAzureSdk &&
|
||||
archiveUrl.hostname.endsWith('.blob.core.windows.net')
|
||||
) {
|
||||
// Use Azure storage SDK to download caches hosted on Azure to improve speed and reliability.
|
||||
await downloadCacheStorageSDK(archiveLocation, archivePath, downloadOptions)
|
||||
} else {
|
||||
// Otherwise, download using the Actions http-client.
|
||||
await downloadCacheHttpClient(archiveLocation, archivePath)
|
||||
}
|
||||
}
|
||||
|
||||
// Reserve Cache
|
||||
export async function reserveCache(
|
||||
key: string,
|
||||
paths: string[],
|
||||
options?: InternalCacheOptions
|
||||
): Promise<ITypedResponseWithError<ReserveCacheResponse>> {
|
||||
const httpClient = createHttpClient()
|
||||
const version = getCacheVersion(
|
||||
paths,
|
||||
options?.compressionMethod,
|
||||
options?.enableCrossOsArchive
|
||||
)
|
||||
|
||||
const reserveCacheRequest: ReserveCacheRequest = {
|
||||
key,
|
||||
version,
|
||||
cacheSize: options?.cacheSize
|
||||
}
|
||||
const response = await retryTypedResponse('reserveCache', async () =>
|
||||
httpClient.postJson<ReserveCacheResponse>(
|
||||
getCacheApiUrl('caches'),
|
||||
reserveCacheRequest
|
||||
)
|
||||
)
|
||||
return response
|
||||
}
|
||||
|
||||
function getContentRange(start: number, end: number): string {
|
||||
// Format: `bytes start-end/filesize
|
||||
// start and end are inclusive
|
||||
// filesize can be *
|
||||
// For a 200 byte chunk starting at byte 0:
|
||||
// Content-Range: bytes 0-199/*
|
||||
return `bytes ${start}-${end}/*`
|
||||
}
|
||||
|
||||
async function uploadChunk(
|
||||
httpClient: HttpClient,
|
||||
resourceUrl: string,
|
||||
openStream: () => NodeJS.ReadableStream,
|
||||
start: number,
|
||||
end: number
|
||||
): Promise<void> {
|
||||
core.debug(
|
||||
`Uploading chunk of size ${end -
|
||||
start +
|
||||
1} bytes at offset ${start} with content range: ${getContentRange(
|
||||
start,
|
||||
end
|
||||
)}`
|
||||
)
|
||||
const additionalHeaders = {
|
||||
'Content-Type': 'application/octet-stream',
|
||||
'Content-Range': getContentRange(start, end)
|
||||
}
|
||||
|
||||
const uploadChunkResponse = await retryHttpClientResponse(
|
||||
`uploadChunk (start: ${start}, end: ${end})`,
|
||||
async () =>
|
||||
httpClient.sendStream(
|
||||
'PATCH',
|
||||
resourceUrl,
|
||||
openStream(),
|
||||
additionalHeaders
|
||||
)
|
||||
)
|
||||
|
||||
if (!isSuccessStatusCode(uploadChunkResponse.message.statusCode)) {
|
||||
throw new Error(
|
||||
`Cache service responded with ${uploadChunkResponse.message.statusCode} during upload chunk.`
|
||||
)
|
||||
}
|
||||
}
|
||||
|
||||
async function uploadFile(
|
||||
httpClient: HttpClient,
|
||||
cacheId: number,
|
||||
archivePath: string,
|
||||
options?: UploadOptions
|
||||
): Promise<void> {
|
||||
// Upload Chunks
|
||||
const fileSize = utils.getArchiveFileSizeInBytes(archivePath)
|
||||
const resourceUrl = getCacheApiUrl(`caches/${cacheId.toString()}`)
|
||||
const fd = fs.openSync(archivePath, 'r')
|
||||
const uploadOptions = getUploadOptions(options)
|
||||
|
||||
const concurrency = utils.assertDefined(
|
||||
'uploadConcurrency',
|
||||
uploadOptions.uploadConcurrency
|
||||
)
|
||||
const maxChunkSize = utils.assertDefined(
|
||||
'uploadChunkSize',
|
||||
uploadOptions.uploadChunkSize
|
||||
)
|
||||
|
||||
const parallelUploads = [...new Array(concurrency).keys()]
|
||||
core.debug('Awaiting all uploads')
|
||||
let offset = 0
|
||||
|
||||
try {
|
||||
await Promise.all(
|
||||
parallelUploads.map(async () => {
|
||||
while (offset < fileSize) {
|
||||
const chunkSize = Math.min(fileSize - offset, maxChunkSize)
|
||||
const start = offset
|
||||
const end = offset + chunkSize - 1
|
||||
offset += maxChunkSize
|
||||
|
||||
await uploadChunk(
|
||||
httpClient,
|
||||
resourceUrl,
|
||||
() =>
|
||||
fs
|
||||
.createReadStream(archivePath, {
|
||||
fd,
|
||||
start,
|
||||
end,
|
||||
autoClose: false
|
||||
})
|
||||
.on('error', error => {
|
||||
throw new Error(
|
||||
`Cache upload failed because file read failed with ${error.message}`
|
||||
)
|
||||
}),
|
||||
start,
|
||||
end
|
||||
)
|
||||
}
|
||||
})
|
||||
)
|
||||
} finally {
|
||||
fs.closeSync(fd)
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
async function commitCache(
|
||||
httpClient: HttpClient,
|
||||
cacheId: number,
|
||||
filesize: number
|
||||
): Promise<TypedResponse<null>> {
|
||||
const commitCacheRequest: CommitCacheRequest = {size: filesize}
|
||||
return await retryTypedResponse('commitCache', async () =>
|
||||
httpClient.postJson<null>(
|
||||
getCacheApiUrl(`caches/${cacheId.toString()}`),
|
||||
commitCacheRequest
|
||||
)
|
||||
)
|
||||
}
|
||||
|
||||
export async function saveCache(
|
||||
cacheId: number,
|
||||
archivePath: string,
|
||||
options?: UploadOptions
|
||||
): Promise<void> {
|
||||
const httpClient = createHttpClient()
|
||||
|
||||
core.debug('Upload cache')
|
||||
await uploadFile(httpClient, cacheId, archivePath, options)
|
||||
|
||||
// Commit Cache
|
||||
core.debug('Commiting cache')
|
||||
const cacheSize = utils.getArchiveFileSizeInBytes(archivePath)
|
||||
core.info(
|
||||
`Cache Size: ~${Math.round(cacheSize / (1024 * 1024))} MB (${cacheSize} B)`
|
||||
)
|
||||
|
||||
const commitCacheResponse = await commitCache(httpClient, cacheId, cacheSize)
|
||||
if (!isSuccessStatusCode(commitCacheResponse.statusCode)) {
|
||||
throw new Error(
|
||||
`Cache service responded with ${commitCacheResponse.statusCode} during commit cache.`
|
||||
)
|
||||
}
|
||||
|
||||
core.info('Cache saved successfully')
|
||||
}
|
||||
-139
@@ -1,139 +0,0 @@
|
||||
import * as core from '@actions/core'
|
||||
import * as exec from '@actions/exec'
|
||||
import * as glob from '@actions/glob'
|
||||
import * as io from '@actions/io'
|
||||
import * as fs from 'fs'
|
||||
import * as path from 'path'
|
||||
import * as semver from 'semver'
|
||||
import * as util from 'util'
|
||||
import {v4 as uuidV4} from 'uuid'
|
||||
import {
|
||||
CacheFilename,
|
||||
CompressionMethod,
|
||||
GnuTarPathOnWindows
|
||||
} from './constants'
|
||||
|
||||
// From https://github.com/actions/toolkit/blob/main/packages/tool-cache/src/tool-cache.ts#L23
|
||||
export async function createTempDirectory(): Promise<string> {
|
||||
const IS_WINDOWS = process.platform === 'win32'
|
||||
|
||||
let tempDirectory: string = process.env['RUNNER_TEMP'] || ''
|
||||
|
||||
if (!tempDirectory) {
|
||||
let baseLocation: string
|
||||
if (IS_WINDOWS) {
|
||||
// On Windows use the USERPROFILE env variable
|
||||
baseLocation = process.env['USERPROFILE'] || 'C:\\'
|
||||
} else {
|
||||
if (process.platform === 'darwin') {
|
||||
baseLocation = '/Users'
|
||||
} else {
|
||||
baseLocation = '/home'
|
||||
}
|
||||
}
|
||||
tempDirectory = path.join(baseLocation, 'actions', 'temp')
|
||||
}
|
||||
|
||||
const dest = path.join(tempDirectory, uuidV4())
|
||||
await io.mkdirP(dest)
|
||||
return dest
|
||||
}
|
||||
|
||||
export function getArchiveFileSizeInBytes(filePath: string): number {
|
||||
return fs.statSync(filePath).size
|
||||
}
|
||||
|
||||
export async function resolvePaths(patterns: string[]): Promise<string[]> {
|
||||
const paths: string[] = []
|
||||
const workspace = process.env['GITHUB_WORKSPACE'] ?? process.cwd()
|
||||
const globber = await glob.create(patterns.join('\n'), {
|
||||
implicitDescendants: false
|
||||
})
|
||||
|
||||
for await (const file of globber.globGenerator()) {
|
||||
const relativeFile = path
|
||||
.relative(workspace, file)
|
||||
.replace(new RegExp(`\\${path.sep}`, 'g'), '/')
|
||||
core.debug(`Matched: ${relativeFile}`)
|
||||
// Paths are made relative so the tar entries are all relative to the root of the workspace.
|
||||
if (relativeFile === '') {
|
||||
// path.relative returns empty string if workspace and file are equal
|
||||
paths.push('.')
|
||||
} else {
|
||||
paths.push(`${relativeFile}`)
|
||||
}
|
||||
}
|
||||
|
||||
return paths
|
||||
}
|
||||
|
||||
export async function unlinkFile(filePath: fs.PathLike): Promise<void> {
|
||||
return util.promisify(fs.unlink)(filePath)
|
||||
}
|
||||
|
||||
async function getVersion(
|
||||
app: string,
|
||||
additionalArgs: string[] = []
|
||||
): Promise<string> {
|
||||
let versionOutput = ''
|
||||
additionalArgs.push('--version')
|
||||
core.debug(`Checking ${app} ${additionalArgs.join(' ')}`)
|
||||
try {
|
||||
await exec.exec(`${app}`, additionalArgs, {
|
||||
ignoreReturnCode: true,
|
||||
silent: true,
|
||||
listeners: {
|
||||
stdout: (data: Buffer): string => (versionOutput += data.toString()),
|
||||
stderr: (data: Buffer): string => (versionOutput += data.toString())
|
||||
}
|
||||
})
|
||||
} catch (err) {
|
||||
core.debug(err.message)
|
||||
}
|
||||
|
||||
versionOutput = versionOutput.trim()
|
||||
core.debug(versionOutput)
|
||||
return versionOutput
|
||||
}
|
||||
|
||||
// Use zstandard if possible to maximize cache performance
|
||||
export async function getCompressionMethod(): Promise<CompressionMethod> {
|
||||
const versionOutput = await getVersion('zstd', ['--quiet'])
|
||||
const version = semver.clean(versionOutput)
|
||||
core.debug(`zstd version: ${version}`)
|
||||
|
||||
if (versionOutput === '') {
|
||||
return CompressionMethod.Gzip
|
||||
} else {
|
||||
return CompressionMethod.ZstdWithoutLong
|
||||
}
|
||||
}
|
||||
|
||||
export function getCacheFileName(compressionMethod: CompressionMethod): string {
|
||||
return compressionMethod === CompressionMethod.Gzip
|
||||
? CacheFilename.Gzip
|
||||
: CacheFilename.Zstd
|
||||
}
|
||||
|
||||
export async function getGnuTarPathOnWindows(): Promise<string> {
|
||||
if (fs.existsSync(GnuTarPathOnWindows)) {
|
||||
return GnuTarPathOnWindows
|
||||
}
|
||||
const versionOutput = await getVersion('tar')
|
||||
return versionOutput.toLowerCase().includes('gnu tar') ? io.which('tar') : ''
|
||||
}
|
||||
|
||||
export function assertDefined<T>(name: string, value?: T): T {
|
||||
if (value === undefined) {
|
||||
throw Error(`Expected ${name} but value was undefiend`)
|
||||
}
|
||||
|
||||
return value
|
||||
}
|
||||
|
||||
export function isGhes(): boolean {
|
||||
const ghUrl = new URL(
|
||||
process.env['GITHUB_SERVER_URL'] || 'https://github.com'
|
||||
)
|
||||
return ghUrl.hostname.toUpperCase() !== 'GITHUB.COM'
|
||||
}
|
||||
-38
@@ -1,38 +0,0 @@
|
||||
export enum CacheFilename {
|
||||
Gzip = 'cache.tgz',
|
||||
Zstd = 'cache.tzst'
|
||||
}
|
||||
|
||||
export enum CompressionMethod {
|
||||
Gzip = 'gzip',
|
||||
// Long range mode was added to zstd in v1.3.2.
|
||||
// This enum is for earlier version of zstd that does not have --long support
|
||||
ZstdWithoutLong = 'zstd-without-long',
|
||||
Zstd = 'zstd'
|
||||
}
|
||||
|
||||
export enum ArchiveToolType {
|
||||
GNU = 'gnu',
|
||||
BSD = 'bsd'
|
||||
}
|
||||
|
||||
// The default number of retry attempts.
|
||||
export const DefaultRetryAttempts = 2
|
||||
|
||||
// The default delay in milliseconds between retry attempts.
|
||||
export const DefaultRetryDelay = 5000
|
||||
|
||||
// Socket timeout in milliseconds during download. If no traffic is received
|
||||
// over the socket during this period, the socket is destroyed and the download
|
||||
// is aborted.
|
||||
export const SocketTimeout = 5000
|
||||
|
||||
// The default path of GNUtar on hosted Windows runners
|
||||
export const GnuTarPathOnWindows = `${process.env['PROGRAMFILES']}\\Git\\usr\\bin\\tar.exe`
|
||||
|
||||
// The default path of BSDtar on hosted Windows runners
|
||||
export const SystemTarPathOnWindows = `${process.env['SYSTEMDRIVE']}\\Windows\\System32\\tar.exe`
|
||||
|
||||
export const TarFilename = 'cache.tar'
|
||||
|
||||
export const ManifestFilename = 'manifest.txt'
|
||||
-45
@@ -1,45 +0,0 @@
|
||||
import {CompressionMethod} from './constants'
|
||||
import {TypedResponse} from '@actions/http-client/lib/interfaces'
|
||||
import {HttpClientError} from '@actions/http-client'
|
||||
|
||||
export interface ITypedResponseWithError<T> extends TypedResponse<T> {
|
||||
error?: HttpClientError
|
||||
}
|
||||
|
||||
export interface ArtifactCacheEntry {
|
||||
cacheKey?: string
|
||||
scope?: string
|
||||
cacheVersion?: string
|
||||
creationTime?: string
|
||||
archiveLocation?: string
|
||||
}
|
||||
|
||||
export interface ArtifactCacheList {
|
||||
totalCount: number
|
||||
artifactCaches?: ArtifactCacheEntry[]
|
||||
}
|
||||
|
||||
export interface CommitCacheRequest {
|
||||
size: number
|
||||
}
|
||||
|
||||
export interface ReserveCacheRequest {
|
||||
key: string
|
||||
version?: string
|
||||
cacheSize?: number
|
||||
}
|
||||
|
||||
export interface ReserveCacheResponse {
|
||||
cacheId: number
|
||||
}
|
||||
|
||||
export interface InternalCacheOptions {
|
||||
compressionMethod?: CompressionMethod
|
||||
enableCrossOsArchive?: boolean
|
||||
cacheSize?: number
|
||||
}
|
||||
|
||||
export interface ArchiveTool {
|
||||
path: string
|
||||
type: string
|
||||
}
|
||||
-303
@@ -1,303 +0,0 @@
|
||||
import * as core from '@actions/core'
|
||||
import {HttpClient, HttpClientResponse} from '@actions/http-client'
|
||||
import {BlockBlobClient} from '@azure/storage-blob'
|
||||
import {TransferProgressEvent} from '@azure/ms-rest-js'
|
||||
import * as buffer from 'buffer'
|
||||
import * as fs from 'fs'
|
||||
import * as stream from 'stream'
|
||||
import * as util from 'util'
|
||||
|
||||
import * as utils from './cacheUtils'
|
||||
import {SocketTimeout} from './constants'
|
||||
import {DownloadOptions} from '../options'
|
||||
import {retryHttpClientResponse} from './requestUtils'
|
||||
|
||||
import {AbortController} from '@azure/abort-controller'
|
||||
|
||||
/**
|
||||
* Pipes the body of a HTTP response to a stream
|
||||
*
|
||||
* @param response the HTTP response
|
||||
* @param output the writable stream
|
||||
*/
|
||||
async function pipeResponseToStream(
|
||||
response: HttpClientResponse,
|
||||
output: NodeJS.WritableStream
|
||||
): Promise<void> {
|
||||
const pipeline = util.promisify(stream.pipeline)
|
||||
await pipeline(response.message, output)
|
||||
}
|
||||
|
||||
/**
|
||||
* Class for tracking the download state and displaying stats.
|
||||
*/
|
||||
export class DownloadProgress {
|
||||
contentLength: number
|
||||
segmentIndex: number
|
||||
segmentSize: number
|
||||
segmentOffset: number
|
||||
receivedBytes: number
|
||||
startTime: number
|
||||
displayedComplete: boolean
|
||||
timeoutHandle?: ReturnType<typeof setTimeout>
|
||||
|
||||
constructor(contentLength: number) {
|
||||
this.contentLength = contentLength
|
||||
this.segmentIndex = 0
|
||||
this.segmentSize = 0
|
||||
this.segmentOffset = 0
|
||||
this.receivedBytes = 0
|
||||
this.displayedComplete = false
|
||||
this.startTime = Date.now()
|
||||
}
|
||||
|
||||
/**
|
||||
* Progress to the next segment. Only call this method when the previous segment
|
||||
* is complete.
|
||||
*
|
||||
* @param segmentSize the length of the next segment
|
||||
*/
|
||||
nextSegment(segmentSize: number): void {
|
||||
this.segmentOffset = this.segmentOffset + this.segmentSize
|
||||
this.segmentIndex = this.segmentIndex + 1
|
||||
this.segmentSize = segmentSize
|
||||
this.receivedBytes = 0
|
||||
|
||||
core.debug(
|
||||
`Downloading segment at offset ${this.segmentOffset} with length ${this.segmentSize}...`
|
||||
)
|
||||
}
|
||||
|
||||
/**
|
||||
* Sets the number of bytes received for the current segment.
|
||||
*
|
||||
* @param receivedBytes the number of bytes received
|
||||
*/
|
||||
setReceivedBytes(receivedBytes: number): void {
|
||||
this.receivedBytes = receivedBytes
|
||||
}
|
||||
|
||||
/**
|
||||
* Returns the total number of bytes transferred.
|
||||
*/
|
||||
getTransferredBytes(): number {
|
||||
return this.segmentOffset + this.receivedBytes
|
||||
}
|
||||
|
||||
/**
|
||||
* Returns true if the download is complete.
|
||||
*/
|
||||
isDone(): boolean {
|
||||
return this.getTransferredBytes() === this.contentLength
|
||||
}
|
||||
|
||||
/**
|
||||
* Prints the current download stats. Once the download completes, this will print one
|
||||
* last line and then stop.
|
||||
*/
|
||||
display(): void {
|
||||
if (this.displayedComplete) {
|
||||
return
|
||||
}
|
||||
|
||||
const transferredBytes = this.segmentOffset + this.receivedBytes
|
||||
const percentage = (100 * (transferredBytes / this.contentLength)).toFixed(
|
||||
1
|
||||
)
|
||||
const elapsedTime = Date.now() - this.startTime
|
||||
const downloadSpeed = (
|
||||
transferredBytes /
|
||||
(1024 * 1024) /
|
||||
(elapsedTime / 1000)
|
||||
).toFixed(1)
|
||||
|
||||
core.info(
|
||||
`Received ${transferredBytes} of ${this.contentLength} (${percentage}%), ${downloadSpeed} MBs/sec`
|
||||
)
|
||||
|
||||
if (this.isDone()) {
|
||||
this.displayedComplete = true
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Returns a function used to handle TransferProgressEvents.
|
||||
*/
|
||||
onProgress(): (progress: TransferProgressEvent) => void {
|
||||
return (progress: TransferProgressEvent) => {
|
||||
this.setReceivedBytes(progress.loadedBytes)
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Starts the timer that displays the stats.
|
||||
*
|
||||
* @param delayInMs the delay between each write
|
||||
*/
|
||||
startDisplayTimer(delayInMs = 1000): void {
|
||||
const displayCallback = (): void => {
|
||||
this.display()
|
||||
|
||||
if (!this.isDone()) {
|
||||
this.timeoutHandle = setTimeout(displayCallback, delayInMs)
|
||||
}
|
||||
}
|
||||
|
||||
this.timeoutHandle = setTimeout(displayCallback, delayInMs)
|
||||
}
|
||||
|
||||
/**
|
||||
* Stops the timer that displays the stats. As this typically indicates the download
|
||||
* is complete, this will display one last line, unless the last line has already
|
||||
* been written.
|
||||
*/
|
||||
stopDisplayTimer(): void {
|
||||
if (this.timeoutHandle) {
|
||||
clearTimeout(this.timeoutHandle)
|
||||
this.timeoutHandle = undefined
|
||||
}
|
||||
|
||||
this.display()
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Download the cache using the Actions toolkit http-client
|
||||
*
|
||||
* @param archiveLocation the URL for the cache
|
||||
* @param archivePath the local path where the cache is saved
|
||||
*/
|
||||
export async function downloadCacheHttpClient(
|
||||
archiveLocation: string,
|
||||
archivePath: string
|
||||
): Promise<void> {
|
||||
const writeStream = fs.createWriteStream(archivePath)
|
||||
const httpClient = new HttpClient('actions/cache')
|
||||
const downloadResponse = await retryHttpClientResponse(
|
||||
'downloadCache',
|
||||
async () => httpClient.get(archiveLocation)
|
||||
)
|
||||
|
||||
// Abort download if no traffic received over the socket.
|
||||
downloadResponse.message.socket.setTimeout(SocketTimeout, () => {
|
||||
downloadResponse.message.destroy()
|
||||
core.debug(`Aborting download, socket timed out after ${SocketTimeout} ms`)
|
||||
})
|
||||
|
||||
await pipeResponseToStream(downloadResponse, writeStream)
|
||||
|
||||
// Validate download size.
|
||||
const contentLengthHeader = downloadResponse.message.headers['content-length']
|
||||
|
||||
if (contentLengthHeader) {
|
||||
const expectedLength = parseInt(contentLengthHeader)
|
||||
const actualLength = utils.getArchiveFileSizeInBytes(archivePath)
|
||||
|
||||
if (actualLength !== expectedLength) {
|
||||
throw new Error(
|
||||
`Incomplete download. Expected file size: ${expectedLength}, actual file size: ${actualLength}`
|
||||
)
|
||||
}
|
||||
} else {
|
||||
core.debug('Unable to validate download, no Content-Length header')
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Download the cache using the Azure Storage SDK. Only call this method if the
|
||||
* URL points to an Azure Storage endpoint.
|
||||
*
|
||||
* @param archiveLocation the URL for the cache
|
||||
* @param archivePath the local path where the cache is saved
|
||||
* @param options the download options with the defaults set
|
||||
*/
|
||||
export async function downloadCacheStorageSDK(
|
||||
archiveLocation: string,
|
||||
archivePath: string,
|
||||
options: DownloadOptions
|
||||
): Promise<void> {
|
||||
const client = new BlockBlobClient(archiveLocation, undefined, {
|
||||
retryOptions: {
|
||||
// Override the timeout used when downloading each 4 MB chunk
|
||||
// The default is 2 min / MB, which is way too slow
|
||||
tryTimeoutInMs: options.timeoutInMs
|
||||
}
|
||||
})
|
||||
|
||||
const properties = await client.getProperties()
|
||||
const contentLength = properties.contentLength ?? -1
|
||||
|
||||
if (contentLength < 0) {
|
||||
// We should never hit this condition, but just in case fall back to downloading the
|
||||
// file as one large stream
|
||||
core.debug(
|
||||
'Unable to determine content length, downloading file with http-client...'
|
||||
)
|
||||
|
||||
await downloadCacheHttpClient(archiveLocation, archivePath)
|
||||
} else {
|
||||
// Use downloadToBuffer for faster downloads, since internally it splits the
|
||||
// file into 4 MB chunks which can then be parallelized and retried independently
|
||||
//
|
||||
// If the file exceeds the buffer maximum length (~1 GB on 32-bit systems and ~2 GB
|
||||
// on 64-bit systems), split the download into multiple segments
|
||||
// ~2 GB = 2147483647, beyond this, we start getting out of range error. So, capping it accordingly.
|
||||
|
||||
// Updated segment size to 128MB = 134217728 bytes, to complete a segment faster and fail fast
|
||||
const maxSegmentSize = Math.min(134217728, buffer.constants.MAX_LENGTH)
|
||||
const downloadProgress = new DownloadProgress(contentLength)
|
||||
|
||||
const fd = fs.openSync(archivePath, 'w')
|
||||
|
||||
try {
|
||||
downloadProgress.startDisplayTimer()
|
||||
const controller = new AbortController()
|
||||
const abortSignal = controller.signal
|
||||
while (!downloadProgress.isDone()) {
|
||||
const segmentStart =
|
||||
downloadProgress.segmentOffset + downloadProgress.segmentSize
|
||||
|
||||
const segmentSize = Math.min(
|
||||
maxSegmentSize,
|
||||
contentLength - segmentStart
|
||||
)
|
||||
|
||||
downloadProgress.nextSegment(segmentSize)
|
||||
const result = await promiseWithTimeout(
|
||||
options.segmentTimeoutInMs || 3600000,
|
||||
client.downloadToBuffer(segmentStart, segmentSize, {
|
||||
abortSignal,
|
||||
concurrency: options.downloadConcurrency,
|
||||
onProgress: downloadProgress.onProgress()
|
||||
})
|
||||
)
|
||||
if (result === 'timeout') {
|
||||
controller.abort()
|
||||
throw new Error(
|
||||
'Aborting cache download as the download time exceeded the timeout.'
|
||||
)
|
||||
} else if (Buffer.isBuffer(result)) {
|
||||
fs.writeFileSync(fd, result)
|
||||
}
|
||||
}
|
||||
} finally {
|
||||
downloadProgress.stopDisplayTimer()
|
||||
fs.closeSync(fd)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
const promiseWithTimeout = async (
|
||||
timeoutMs: number,
|
||||
promise: Promise<Buffer>
|
||||
): Promise<unknown> => {
|
||||
let timeoutHandle: NodeJS.Timeout
|
||||
const timeoutPromise = new Promise(resolve => {
|
||||
timeoutHandle = setTimeout(() => resolve('timeout'), timeoutMs)
|
||||
})
|
||||
|
||||
return Promise.race([promise, timeoutPromise]).then(result => {
|
||||
clearTimeout(timeoutHandle)
|
||||
return result
|
||||
})
|
||||
}
|
||||
-138
@@ -1,138 +0,0 @@
|
||||
import * as core from '@actions/core'
|
||||
import {
|
||||
HttpCodes,
|
||||
HttpClientError,
|
||||
HttpClientResponse
|
||||
} from '@actions/http-client'
|
||||
import {DefaultRetryDelay, DefaultRetryAttempts} from './constants'
|
||||
import {ITypedResponseWithError} from './contracts'
|
||||
|
||||
export function isSuccessStatusCode(statusCode?: number): boolean {
|
||||
if (!statusCode) {
|
||||
return false
|
||||
}
|
||||
return statusCode >= 200 && statusCode < 300
|
||||
}
|
||||
|
||||
export function isServerErrorStatusCode(statusCode?: number): boolean {
|
||||
if (!statusCode) {
|
||||
return true
|
||||
}
|
||||
return statusCode >= 500
|
||||
}
|
||||
|
||||
export function isRetryableStatusCode(statusCode?: number): boolean {
|
||||
if (!statusCode) {
|
||||
return false
|
||||
}
|
||||
const retryableStatusCodes = [
|
||||
HttpCodes.BadGateway,
|
||||
HttpCodes.ServiceUnavailable,
|
||||
HttpCodes.GatewayTimeout
|
||||
]
|
||||
return retryableStatusCodes.includes(statusCode)
|
||||
}
|
||||
|
||||
async function sleep(milliseconds: number): Promise<void> {
|
||||
return new Promise(resolve => setTimeout(resolve, milliseconds))
|
||||
}
|
||||
|
||||
export async function retry<T>(
|
||||
name: string,
|
||||
method: () => Promise<T>,
|
||||
getStatusCode: (arg0: T) => number | undefined,
|
||||
maxAttempts = DefaultRetryAttempts,
|
||||
delay = DefaultRetryDelay,
|
||||
onError: ((arg0: Error) => T | undefined) | undefined = undefined
|
||||
): Promise<T> {
|
||||
let errorMessage = ''
|
||||
let attempt = 1
|
||||
|
||||
while (attempt <= maxAttempts) {
|
||||
let response: T | undefined = undefined
|
||||
let statusCode: number | undefined = undefined
|
||||
let isRetryable = false
|
||||
|
||||
try {
|
||||
response = await method()
|
||||
} catch (error) {
|
||||
if (onError) {
|
||||
response = onError(error)
|
||||
}
|
||||
|
||||
isRetryable = true
|
||||
errorMessage = error.message
|
||||
}
|
||||
|
||||
if (response) {
|
||||
statusCode = getStatusCode(response)
|
||||
|
||||
if (!isServerErrorStatusCode(statusCode)) {
|
||||
return response
|
||||
}
|
||||
}
|
||||
|
||||
if (statusCode) {
|
||||
isRetryable = isRetryableStatusCode(statusCode)
|
||||
errorMessage = `Cache service responded with ${statusCode}`
|
||||
}
|
||||
|
||||
core.debug(
|
||||
`${name} - Attempt ${attempt} of ${maxAttempts} failed with error: ${errorMessage}`
|
||||
)
|
||||
|
||||
if (!isRetryable) {
|
||||
core.debug(`${name} - Error is not retryable`)
|
||||
break
|
||||
}
|
||||
|
||||
await sleep(delay)
|
||||
attempt++
|
||||
}
|
||||
|
||||
throw Error(`${name} failed: ${errorMessage}`)
|
||||
}
|
||||
|
||||
export async function retryTypedResponse<T>(
|
||||
name: string,
|
||||
method: () => Promise<ITypedResponseWithError<T>>,
|
||||
maxAttempts = DefaultRetryAttempts,
|
||||
delay = DefaultRetryDelay
|
||||
): Promise<ITypedResponseWithError<T>> {
|
||||
return await retry(
|
||||
name,
|
||||
method,
|
||||
(response: ITypedResponseWithError<T>) => response.statusCode,
|
||||
maxAttempts,
|
||||
delay,
|
||||
// If the error object contains the statusCode property, extract it and return
|
||||
// an TypedResponse<T> so it can be processed by the retry logic.
|
||||
(error: Error) => {
|
||||
if (error instanceof HttpClientError) {
|
||||
return {
|
||||
statusCode: error.statusCode,
|
||||
result: null,
|
||||
headers: {},
|
||||
error
|
||||
}
|
||||
} else {
|
||||
return undefined
|
||||
}
|
||||
}
|
||||
)
|
||||
}
|
||||
|
||||
export async function retryHttpClientResponse(
|
||||
name: string,
|
||||
method: () => Promise<HttpClientResponse>,
|
||||
maxAttempts = DefaultRetryAttempts,
|
||||
delay = DefaultRetryDelay
|
||||
): Promise<HttpClientResponse> {
|
||||
return await retry(
|
||||
name,
|
||||
method,
|
||||
(response: HttpClientResponse) => response.message.statusCode,
|
||||
maxAttempts,
|
||||
delay
|
||||
)
|
||||
}
|
||||
Vendored
-297
@@ -1,297 +0,0 @@
|
||||
import {exec} from '@actions/exec'
|
||||
import * as io from '@actions/io'
|
||||
import {existsSync, writeFileSync} from 'fs'
|
||||
import * as path from 'path'
|
||||
import * as utils from './cacheUtils'
|
||||
import {ArchiveTool} from './contracts'
|
||||
import {
|
||||
CompressionMethod,
|
||||
SystemTarPathOnWindows,
|
||||
ArchiveToolType,
|
||||
TarFilename,
|
||||
ManifestFilename
|
||||
} from './constants'
|
||||
|
||||
const IS_WINDOWS = process.platform === 'win32'
|
||||
|
||||
// Returns tar path and type: BSD or GNU
|
||||
async function getTarPath(): Promise<ArchiveTool> {
|
||||
switch (process.platform) {
|
||||
case 'win32': {
|
||||
const gnuTar = await utils.getGnuTarPathOnWindows()
|
||||
const systemTar = SystemTarPathOnWindows
|
||||
if (gnuTar) {
|
||||
// Use GNUtar as default on windows
|
||||
return <ArchiveTool>{path: gnuTar, type: ArchiveToolType.GNU}
|
||||
} else if (existsSync(systemTar)) {
|
||||
return <ArchiveTool>{path: systemTar, type: ArchiveToolType.BSD}
|
||||
}
|
||||
break
|
||||
}
|
||||
case 'darwin': {
|
||||
const gnuTar = await io.which('gtar', false)
|
||||
if (gnuTar) {
|
||||
// fix permission denied errors when extracting BSD tar archive with GNU tar - https://github.com/actions/cache/issues/527
|
||||
return <ArchiveTool>{path: gnuTar, type: ArchiveToolType.GNU}
|
||||
} else {
|
||||
return <ArchiveTool>{
|
||||
path: await io.which('tar', true),
|
||||
type: ArchiveToolType.BSD
|
||||
}
|
||||
}
|
||||
}
|
||||
default:
|
||||
break
|
||||
}
|
||||
// Default assumption is GNU tar is present in path
|
||||
return <ArchiveTool>{
|
||||
path: await io.which('tar', true),
|
||||
type: ArchiveToolType.GNU
|
||||
}
|
||||
}
|
||||
|
||||
// Return arguments for tar as per tarPath, compressionMethod, method type and os
|
||||
async function getTarArgs(
|
||||
tarPath: ArchiveTool,
|
||||
compressionMethod: CompressionMethod,
|
||||
type: string,
|
||||
archivePath = ''
|
||||
): Promise<string[]> {
|
||||
const args = [`"${tarPath.path}"`]
|
||||
const cacheFileName = utils.getCacheFileName(compressionMethod)
|
||||
const tarFile = 'cache.tar'
|
||||
const workingDirectory = getWorkingDirectory()
|
||||
// Speficic args for BSD tar on windows for workaround
|
||||
const BSD_TAR_ZSTD =
|
||||
tarPath.type === ArchiveToolType.BSD &&
|
||||
compressionMethod !== CompressionMethod.Gzip &&
|
||||
IS_WINDOWS
|
||||
|
||||
// Method specific args
|
||||
switch (type) {
|
||||
case 'create':
|
||||
args.push(
|
||||
'--posix',
|
||||
'-cf',
|
||||
BSD_TAR_ZSTD
|
||||
? tarFile
|
||||
: cacheFileName.replace(new RegExp(`\\${path.sep}`, 'g'), '/'),
|
||||
'--exclude',
|
||||
BSD_TAR_ZSTD
|
||||
? tarFile
|
||||
: cacheFileName.replace(new RegExp(`\\${path.sep}`, 'g'), '/'),
|
||||
'-P',
|
||||
'-C',
|
||||
workingDirectory.replace(new RegExp(`\\${path.sep}`, 'g'), '/'),
|
||||
'--files-from',
|
||||
ManifestFilename
|
||||
)
|
||||
break
|
||||
case 'extract':
|
||||
args.push(
|
||||
'-xf',
|
||||
BSD_TAR_ZSTD
|
||||
? tarFile
|
||||
: archivePath.replace(new RegExp(`\\${path.sep}`, 'g'), '/'),
|
||||
'-P',
|
||||
'-C',
|
||||
workingDirectory.replace(new RegExp(`\\${path.sep}`, 'g'), '/')
|
||||
)
|
||||
break
|
||||
case 'list':
|
||||
args.push(
|
||||
'-tf',
|
||||
BSD_TAR_ZSTD
|
||||
? tarFile
|
||||
: archivePath.replace(new RegExp(`\\${path.sep}`, 'g'), '/'),
|
||||
'-P'
|
||||
)
|
||||
break
|
||||
}
|
||||
|
||||
// Platform specific args
|
||||
if (tarPath.type === ArchiveToolType.GNU) {
|
||||
switch (process.platform) {
|
||||
case 'win32':
|
||||
args.push('--force-local')
|
||||
break
|
||||
case 'darwin':
|
||||
args.push('--delay-directory-restore')
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
return args
|
||||
}
|
||||
|
||||
// Returns commands to run tar and compression program
|
||||
async function getCommands(
|
||||
compressionMethod: CompressionMethod,
|
||||
type: string,
|
||||
archivePath = ''
|
||||
): Promise<string[]> {
|
||||
let args
|
||||
|
||||
const tarPath = await getTarPath()
|
||||
const tarArgs = await getTarArgs(
|
||||
tarPath,
|
||||
compressionMethod,
|
||||
type,
|
||||
archivePath
|
||||
)
|
||||
const compressionArgs =
|
||||
type !== 'create'
|
||||
? await getDecompressionProgram(tarPath, compressionMethod, archivePath)
|
||||
: await getCompressionProgram(tarPath, compressionMethod)
|
||||
const BSD_TAR_ZSTD =
|
||||
tarPath.type === ArchiveToolType.BSD &&
|
||||
compressionMethod !== CompressionMethod.Gzip &&
|
||||
IS_WINDOWS
|
||||
|
||||
if (BSD_TAR_ZSTD && type !== 'create') {
|
||||
args = [[...compressionArgs].join(' '), [...tarArgs].join(' ')]
|
||||
} else {
|
||||
args = [[...tarArgs].join(' '), [...compressionArgs].join(' ')]
|
||||
}
|
||||
|
||||
if (BSD_TAR_ZSTD) {
|
||||
return args
|
||||
}
|
||||
|
||||
return [args.join(' ')]
|
||||
}
|
||||
|
||||
function getWorkingDirectory(): string {
|
||||
return process.env['GITHUB_WORKSPACE'] ?? process.cwd()
|
||||
}
|
||||
|
||||
// Common function for extractTar and listTar to get the compression method
|
||||
async function getDecompressionProgram(
|
||||
tarPath: ArchiveTool,
|
||||
compressionMethod: CompressionMethod,
|
||||
archivePath: string
|
||||
): Promise<string[]> {
|
||||
// -d: Decompress.
|
||||
// unzstd is equivalent to 'zstd -d'
|
||||
// --long=#: Enables long distance matching with # bits. Maximum is 30 (1GB) on 32-bit OS and 31 (2GB) on 64-bit.
|
||||
// Using 30 here because we also support 32-bit self-hosted runners.
|
||||
const BSD_TAR_ZSTD =
|
||||
tarPath.type === ArchiveToolType.BSD &&
|
||||
compressionMethod !== CompressionMethod.Gzip &&
|
||||
IS_WINDOWS
|
||||
switch (compressionMethod) {
|
||||
case CompressionMethod.Zstd:
|
||||
return BSD_TAR_ZSTD
|
||||
? [
|
||||
'zstd -d --long=30 --force -o',
|
||||
TarFilename,
|
||||
archivePath.replace(new RegExp(`\\${path.sep}`, 'g'), '/')
|
||||
]
|
||||
: [
|
||||
'--use-compress-program',
|
||||
IS_WINDOWS ? '"zstd -d --long=30"' : 'unzstd --long=30'
|
||||
]
|
||||
case CompressionMethod.ZstdWithoutLong:
|
||||
return BSD_TAR_ZSTD
|
||||
? [
|
||||
'zstd -d --force -o',
|
||||
TarFilename,
|
||||
archivePath.replace(new RegExp(`\\${path.sep}`, 'g'), '/')
|
||||
]
|
||||
: ['--use-compress-program', IS_WINDOWS ? '"zstd -d"' : 'unzstd']
|
||||
default:
|
||||
return ['-z']
|
||||
}
|
||||
}
|
||||
|
||||
// Used for creating the archive
|
||||
// -T#: Compress using # working thread. If # is 0, attempt to detect and use the number of physical CPU cores.
|
||||
// zstdmt is equivalent to 'zstd -T0'
|
||||
// --long=#: Enables long distance matching with # bits. Maximum is 30 (1GB) on 32-bit OS and 31 (2GB) on 64-bit.
|
||||
// Using 30 here because we also support 32-bit self-hosted runners.
|
||||
// Long range mode is added to zstd in v1.3.2 release, so we will not use --long in older version of zstd.
|
||||
async function getCompressionProgram(
|
||||
tarPath: ArchiveTool,
|
||||
compressionMethod: CompressionMethod
|
||||
): Promise<string[]> {
|
||||
const cacheFileName = utils.getCacheFileName(compressionMethod)
|
||||
const BSD_TAR_ZSTD =
|
||||
tarPath.type === ArchiveToolType.BSD &&
|
||||
compressionMethod !== CompressionMethod.Gzip &&
|
||||
IS_WINDOWS
|
||||
switch (compressionMethod) {
|
||||
case CompressionMethod.Zstd:
|
||||
return BSD_TAR_ZSTD
|
||||
? [
|
||||
'zstd -T0 --long=30 --force -o',
|
||||
cacheFileName.replace(new RegExp(`\\${path.sep}`, 'g'), '/'),
|
||||
TarFilename
|
||||
]
|
||||
: [
|
||||
'--use-compress-program',
|
||||
IS_WINDOWS ? '"zstd -T0 --long=30"' : 'zstdmt --long=30'
|
||||
]
|
||||
case CompressionMethod.ZstdWithoutLong:
|
||||
return BSD_TAR_ZSTD
|
||||
? [
|
||||
'zstd -T0 --force -o',
|
||||
cacheFileName.replace(new RegExp(`\\${path.sep}`, 'g'), '/'),
|
||||
TarFilename
|
||||
]
|
||||
: ['--use-compress-program', IS_WINDOWS ? '"zstd -T0"' : 'zstdmt']
|
||||
default:
|
||||
return ['-z']
|
||||
}
|
||||
}
|
||||
|
||||
// Executes all commands as separate processes
|
||||
async function execCommands(commands: string[], cwd?: string): Promise<void> {
|
||||
for (const command of commands) {
|
||||
try {
|
||||
await exec(command, undefined, {
|
||||
cwd,
|
||||
env: {...(process.env as object), MSYS: 'winsymlinks:nativestrict'}
|
||||
})
|
||||
} catch (error) {
|
||||
throw new Error(
|
||||
`${command.split(' ')[0]} failed with error: ${error?.message}`
|
||||
)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// List the contents of a tar
|
||||
export async function listTar(
|
||||
archivePath: string,
|
||||
compressionMethod: CompressionMethod
|
||||
): Promise<void> {
|
||||
const commands = await getCommands(compressionMethod, 'list', archivePath)
|
||||
await execCommands(commands)
|
||||
}
|
||||
|
||||
// Extract a tar
|
||||
export async function extractTar(
|
||||
archivePath: string,
|
||||
compressionMethod: CompressionMethod
|
||||
): Promise<void> {
|
||||
// Create directory to extract tar into
|
||||
const workingDirectory = getWorkingDirectory()
|
||||
await io.mkdirP(workingDirectory)
|
||||
const commands = await getCommands(compressionMethod, 'extract', archivePath)
|
||||
await execCommands(commands)
|
||||
}
|
||||
|
||||
// Create a tar
|
||||
export async function createTar(
|
||||
archiveFolder: string,
|
||||
sourceDirectories: string[],
|
||||
compressionMethod: CompressionMethod
|
||||
): Promise<void> {
|
||||
// Write source directories to manifest.txt to avoid command length limits
|
||||
writeFileSync(
|
||||
path.join(archiveFolder, ManifestFilename),
|
||||
sourceDirectories.join('\n')
|
||||
)
|
||||
const commands = await getCommands(compressionMethod, 'create')
|
||||
await execCommands(commands, archiveFolder)
|
||||
}
|
||||
Vendored
-149
@@ -1,149 +0,0 @@
|
||||
import * as core from '@actions/core'
|
||||
|
||||
/**
|
||||
* Options to control cache upload
|
||||
*/
|
||||
export interface UploadOptions {
|
||||
/**
|
||||
* Number of parallel cache upload
|
||||
*
|
||||
* @default 4
|
||||
*/
|
||||
uploadConcurrency?: number
|
||||
/**
|
||||
* Maximum chunk size in bytes for cache upload
|
||||
*
|
||||
* @default 32MB
|
||||
*/
|
||||
uploadChunkSize?: number
|
||||
}
|
||||
|
||||
/**
|
||||
* Options to control cache download
|
||||
*/
|
||||
export interface DownloadOptions {
|
||||
/**
|
||||
* Indicates whether to use the Azure Blob SDK to download caches
|
||||
* that are stored on Azure Blob Storage to improve reliability and
|
||||
* performance
|
||||
*
|
||||
* @default true
|
||||
*/
|
||||
useAzureSdk?: boolean
|
||||
|
||||
/**
|
||||
* Number of parallel downloads (this option only applies when using
|
||||
* the Azure SDK)
|
||||
*
|
||||
* @default 8
|
||||
*/
|
||||
downloadConcurrency?: number
|
||||
|
||||
/**
|
||||
* Maximum time for each download request, in milliseconds (this
|
||||
* option only applies when using the Azure SDK)
|
||||
*
|
||||
* @default 30000
|
||||
*/
|
||||
timeoutInMs?: number
|
||||
|
||||
/**
|
||||
* Time after which a segment download should be aborted if stuck
|
||||
*
|
||||
* @default 3600000
|
||||
*/
|
||||
segmentTimeoutInMs?: number
|
||||
|
||||
/**
|
||||
* Weather to skip downloading the cache entry.
|
||||
* If lookupOnly is set to true, the restore function will only check if
|
||||
* a matching cache entry exists and return the cache key if it does.
|
||||
*
|
||||
* @default false
|
||||
*/
|
||||
lookupOnly?: boolean
|
||||
}
|
||||
|
||||
/**
|
||||
* Returns a copy of the upload options with defaults filled in.
|
||||
*
|
||||
* @param copy the original upload options
|
||||
*/
|
||||
export function getUploadOptions(copy?: UploadOptions): UploadOptions {
|
||||
const result: UploadOptions = {
|
||||
uploadConcurrency: 4,
|
||||
uploadChunkSize: 32 * 1024 * 1024
|
||||
}
|
||||
|
||||
if (copy) {
|
||||
if (typeof copy.uploadConcurrency === 'number') {
|
||||
result.uploadConcurrency = copy.uploadConcurrency
|
||||
}
|
||||
|
||||
if (typeof copy.uploadChunkSize === 'number') {
|
||||
result.uploadChunkSize = copy.uploadChunkSize
|
||||
}
|
||||
}
|
||||
|
||||
core.debug(`Upload concurrency: ${result.uploadConcurrency}`)
|
||||
core.debug(`Upload chunk size: ${result.uploadChunkSize}`)
|
||||
|
||||
return result
|
||||
}
|
||||
|
||||
/**
|
||||
* Returns a copy of the download options with defaults filled in.
|
||||
*
|
||||
* @param copy the original download options
|
||||
*/
|
||||
export function getDownloadOptions(copy?: DownloadOptions): DownloadOptions {
|
||||
const result: DownloadOptions = {
|
||||
useAzureSdk: true,
|
||||
downloadConcurrency: 8,
|
||||
timeoutInMs: 30000,
|
||||
segmentTimeoutInMs: 600000,
|
||||
lookupOnly: false
|
||||
}
|
||||
|
||||
if (copy) {
|
||||
if (typeof copy.useAzureSdk === 'boolean') {
|
||||
result.useAzureSdk = copy.useAzureSdk
|
||||
}
|
||||
|
||||
if (typeof copy.downloadConcurrency === 'number') {
|
||||
result.downloadConcurrency = copy.downloadConcurrency
|
||||
}
|
||||
|
||||
if (typeof copy.timeoutInMs === 'number') {
|
||||
result.timeoutInMs = copy.timeoutInMs
|
||||
}
|
||||
|
||||
if (typeof copy.segmentTimeoutInMs === 'number') {
|
||||
result.segmentTimeoutInMs = copy.segmentTimeoutInMs
|
||||
}
|
||||
|
||||
if (typeof copy.lookupOnly === 'boolean') {
|
||||
result.lookupOnly = copy.lookupOnly
|
||||
}
|
||||
}
|
||||
const segmentDownloadTimeoutMins =
|
||||
process.env['SEGMENT_DOWNLOAD_TIMEOUT_MINS']
|
||||
|
||||
if (
|
||||
segmentDownloadTimeoutMins &&
|
||||
!isNaN(Number(segmentDownloadTimeoutMins)) &&
|
||||
isFinite(Number(segmentDownloadTimeoutMins))
|
||||
) {
|
||||
result.segmentTimeoutInMs = Number(segmentDownloadTimeoutMins) * 60 * 1000
|
||||
}
|
||||
core.debug(`Use Azure SDK: ${result.useAzureSdk}`)
|
||||
core.debug(`Download concurrency: ${result.downloadConcurrency}`)
|
||||
core.debug(`Request timeout (ms): ${result.timeoutInMs}`)
|
||||
core.debug(
|
||||
`Cache segment download timeout mins env var: ${process.env['SEGMENT_DOWNLOAD_TIMEOUT_MINS']}`
|
||||
)
|
||||
core.debug(`Segment download timeout (ms): ${result.segmentTimeoutInMs}`)
|
||||
core.debug(`Lookup only: ${result.lookupOnly}`)
|
||||
|
||||
return result
|
||||
}
|
||||
Vendored
-13
@@ -1,13 +0,0 @@
|
||||
{
|
||||
"extends": "../../tsconfig.json",
|
||||
"compilerOptions": {
|
||||
"baseUrl": "./",
|
||||
"outDir": "./lib",
|
||||
"rootDir": "./src",
|
||||
"lib": ["es6", "dom"],
|
||||
"useUnknownInCatchVariables": false
|
||||
},
|
||||
"include": [
|
||||
"./src"
|
||||
]
|
||||
}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user